(第六节)操作系统--换入\换出(用空间和时间换虚存)
写在最前面
前面在内存管理部分我们介绍了地址翻译的相关知识,即通过段基址和偏移获取虚拟地址,而后通过虚拟地址获取到物理地址。
虚拟内存作为中转区域完成段页结合机制,同时32位逻辑地址可以定位到一个4G大小的区域,而这也是虚拟内存的标准大小,换句话说,每一个进程都对应一个虚拟内存且其大小为4G。
但是虚拟内存毕竟是虚拟的,只有将其与物理页框映射才可以落实到具体的硬件存储中。这就导致一个问题:虚拟内存太大了而实际物理内存太小,使得物理内存无法与所有的虚拟内存完成映射。因此,采取换入、换出机制,使用磁盘和时间换取空间。
换入:用户在访问某个虚拟内存时,如果此虚拟内存没有与物理内存关联,就立马从磁盘上读取内容并建立关联。换出:将物理内存上的部分内容移到磁盘中并和虚拟内存解除关联。
注:文章内容参考《操作系统原理 实现、与实践》,所用图片来自书配图与网络,仅用于个人学习使用。
规整的虚拟内存
基本概念介绍
什么叫规整?
规整是一个形容词,在这里是说每一个进程对应的虚拟内存都有相同的大小(32位操作系统定义的虚拟内存大小为4G)
建立规整的虚拟内存可以简化用户程序对内存的使用。
如何实现规整?
通过换入、换出机制。对于此机制的定义上面已经給出,我们下面要介绍这种机制的原理及如何实现这种机制。不过,在此之前先来看一下换入换出的示意图:
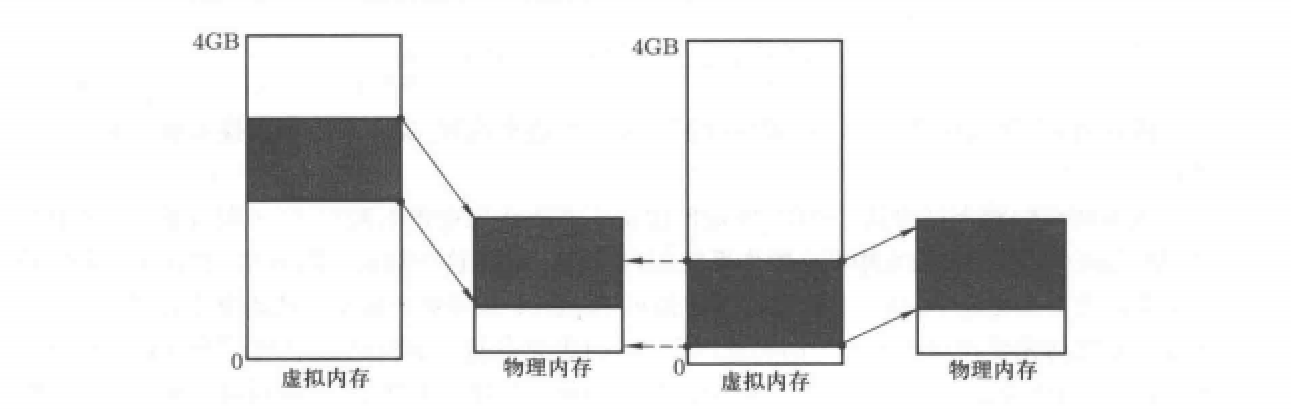
换入机制-请求调页
请求调页
换入的前提:映射未建立
我们以下图为例:
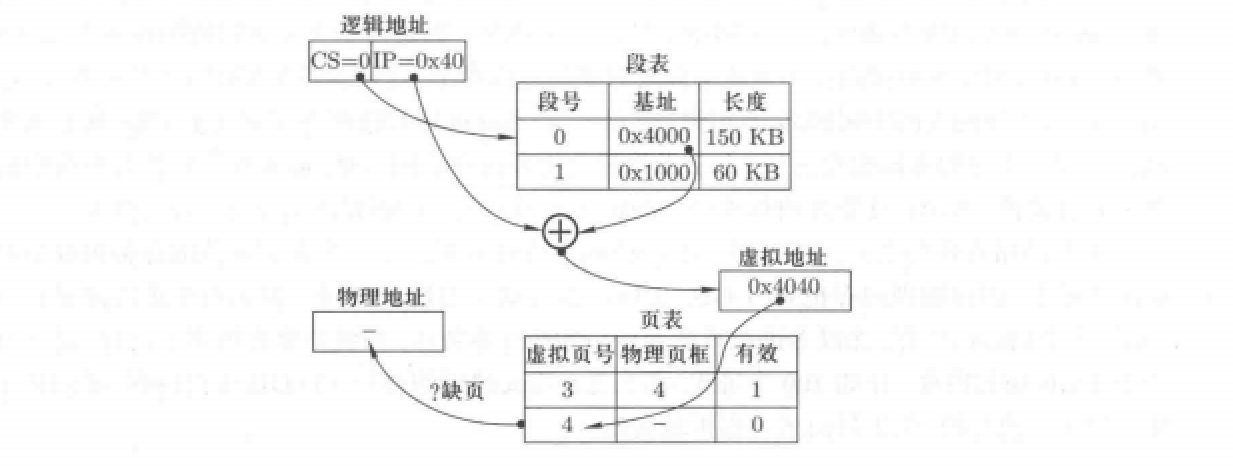
通过段基址+段内偏移得到虚拟地址为0x4040。而后就要将这个虚拟地址转换为实际物理地址,通过运算可得此虚拟地址对应的页号为4,所以查询页表得到物理地址。这时问题就出现了,页表中并没有建立映射关系,也就无法获取物理页。
这时,就要使用换入机制,即在缺少虚拟页时请求调页。
内存换入:请求调页
请求调页的过程发生在:MMU发现虚拟页面在页表项中有效位为0时。调页的流程大概如下:
- MMU向CPU发送缺页中断,而后执行这个中断程序。
- 中断程序首先会先在磁盘中找到这个虚拟页面对应的内容,并将其放到一个空闲页框中。
- 修改页表项,完成虚拟内存与物理页框的映射处理。
下图是对请求调页的流程概括:
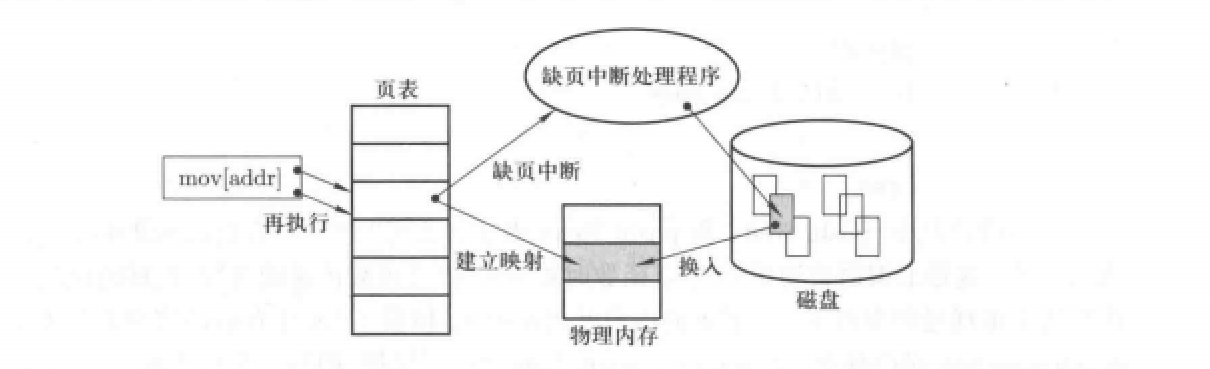
页面调入的具体实现
前面我们只是介绍了请求调页的流程,下面要学习其具体实现,会从代码的层面进行介绍。
代码1:从缺页中断程序开始
我们要分析此系统如何实现换入机制,肯定要从第一句代码开始,这个代码就是缺页中断的代码。
在操作系统启动时初始IDT表时就将14号中断设置为缺页中断,具体如下:

如上图所示,page_fault就是对应的中断处理函数,其具体代码如下:


我们来分析一下代码:
- 第一行:获取页面错误的类型,是
缺页还是越权访问,并把结果保存在eax里。 - 第二行:将edx的值保存在
cr2寄存器,用于确定缺页的虚拟地址。 - 第三、四行:将参数压栈,为后续函数传参。
- 第五行:判断错误类型,并跳转到对应函数,包括
do_no_page和do_wp_page - 后续就是函数的跳转与执行
do_no_page函数

分析一下代码:
- 第一行:通过与运算得出虚拟页号(
前20位) - 第二行:通过
get_free_page()获取一个空闲的物理内存 - 第三行:通过
bread_page()将磁盘内容放入物理内存中 - 第四行:通过
put_page()填写页表内容,完成映射
需要注意的是,bread_page完成磁盘读写的实现我们放到后面文件管理时具体介绍。
承上启下
上面我们介绍了内存换入的原因与实现,过程很简单:
缺页中断->虚拟页号获取->物理内存获取与磁盘写入->页表填写完成映射。到这里,主程序就可以寻址成功。
不只有换入,还有换出,因为我们在换入时会请求一个物理内存,但是我们无法保证一定有空闲的物理内存,一旦没有就要实施换出机制。换出的流程与实现要复杂一点,涉及到很多算法。
换入机制-页面换出
页面换出的基本算法
页面换出是在get_free_page时实现的,而页面换出的一个很重要的问题就是:如何确定要淘汰哪一页?
我们需要一些算法来确定换出机制的淘汰对象,这里我们主要介绍以下三种算法:(比较其优缺点,找到最优算法)

算法1:FIFO(先入先出)
我们以下面这个例子来看: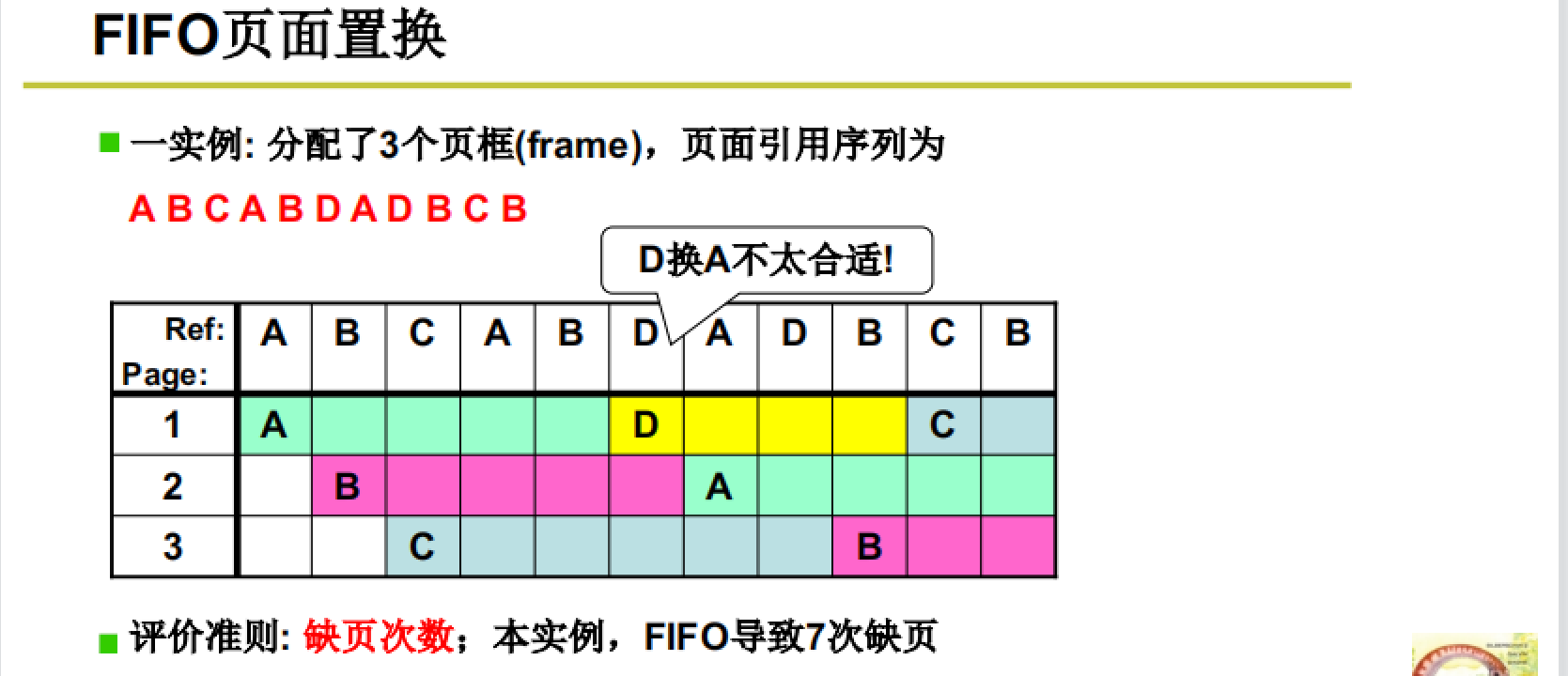
如图所示,使用FIFO算法进行页面换出和换入,缺页次数为7。这种算法并不是很好,因为往往导致刚刚换出的页又要被换入。
算法2:MIN(取最后一个使用的进行换出)
使用MIN算法实际操作我们上面的例子:
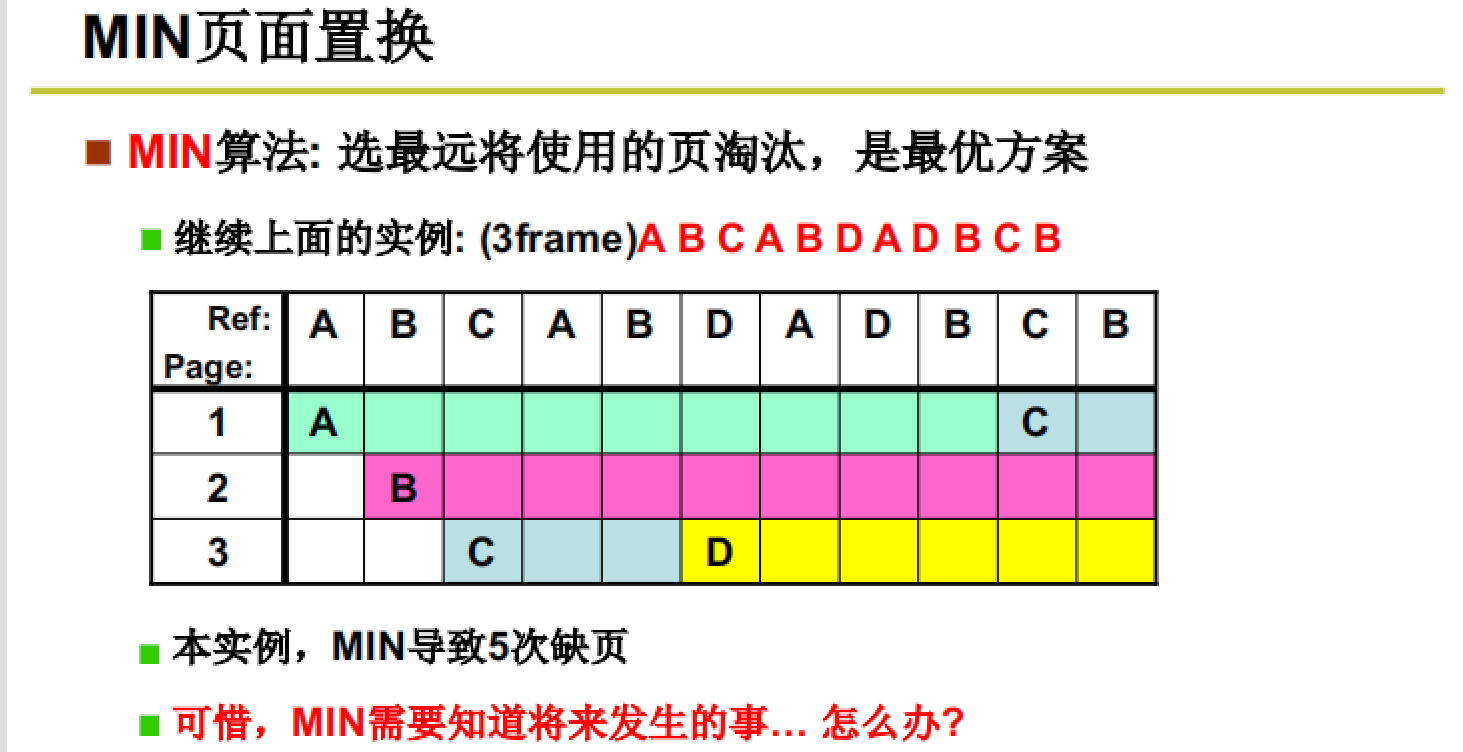
缺页次数变少了。其实,MIN算法就是最优的换出算法,可以有效减少缺页次数。
但是,MIN算法只是一种理想算法,在实际的情况下,我们不可能知道后面要发生什么,也就无法确定后续哪一个页最后被使用。
但但是,我们可以借鉴一下MIN算法的思想,从而引出LRU算法。
算法3:LRU算法
使用LRU算法的示例:
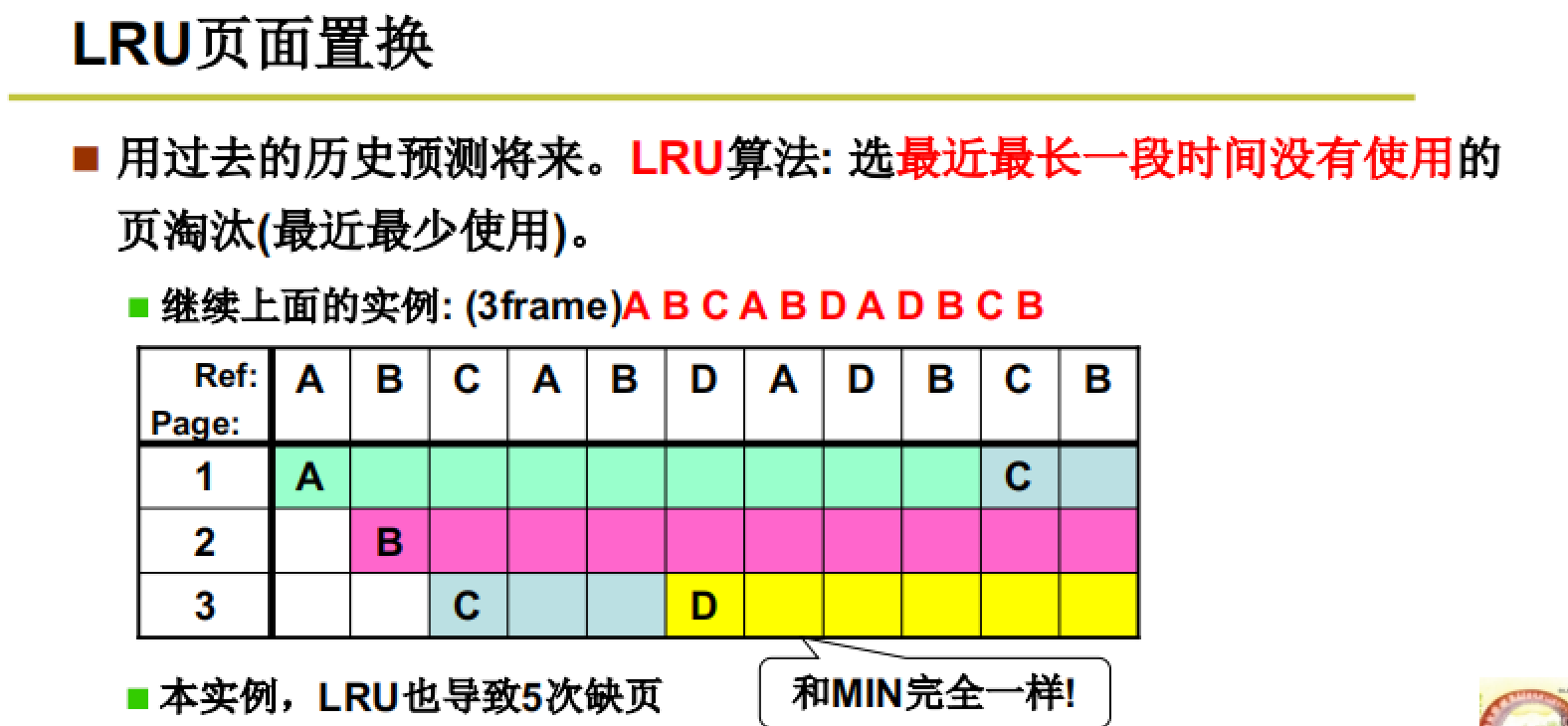
LRU算法就是使用历史来预测未来:根据局部性规律,我们的程序往往在一个固定的段中进行跳转,比如:while循环、for循环等操作。
所以如图所示,通过LRU算法得到的换出顺序与MIN算法一致,可以达到最优策略。
LRU算法的具体实现
实现方法1:
时间戳(模拟很简单,实践不适用)
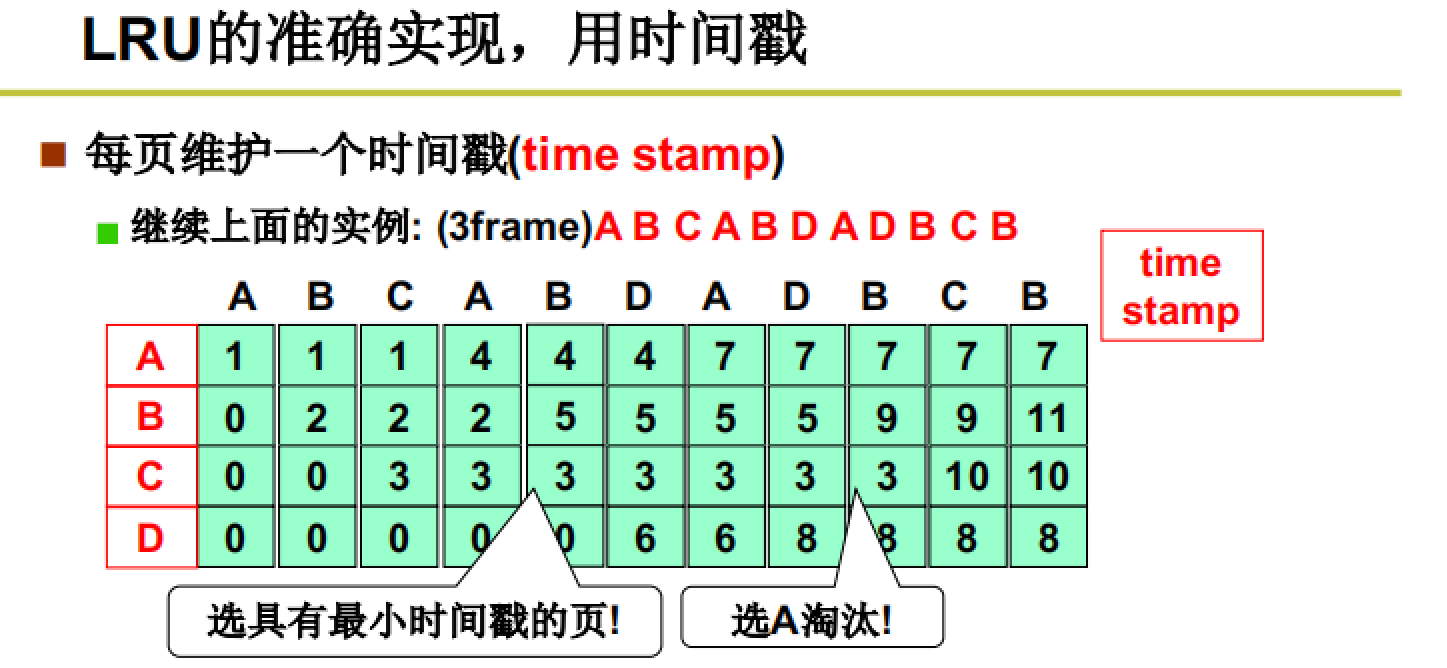
如图所示,我们维护一个表,在其中为每一个页定义一个时间戳,这个时间戳会随着页的使用而依次增加,换出时选择时间戳最小的页所在的页框进行换出。
使用时间戳的方法看起来很直观,也很好实现,但是在实际情况下很难落实:花费时间较多、时间戳溢出等
实现方法2:
页码栈(频繁修改指针,代价较大)
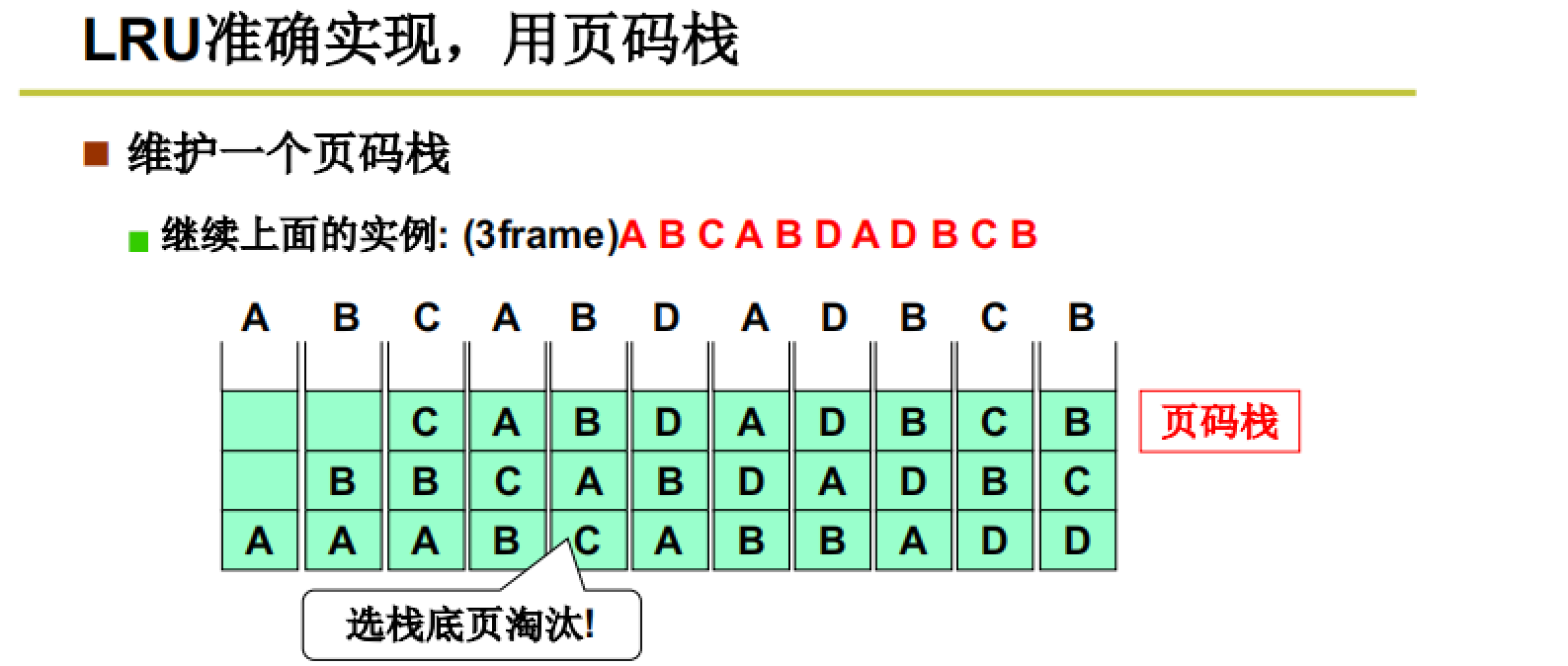
如图所示,维护一个页码栈,将最近使用的页放到最上面(浮起来),换出时选择沉底的页所在的页框。
使用页码栈会导致每次地址访问都要修改指针,时间代价较大。
承上启下
前面我们引出了
LRU算法,并给出了几种实现方法:时间戳、页码栈等,但是在实际情况下都很难高效实现。
所以我们要对LRU算法进行进一步改进:使用LRU的近似实现
clock算法
clock算法就是对LRU算法的近似实现,将时间计数改为了是和否,而不是使用递增数字。使用最近没有使用近似最少使用。
原始clock算法实现(单指针)
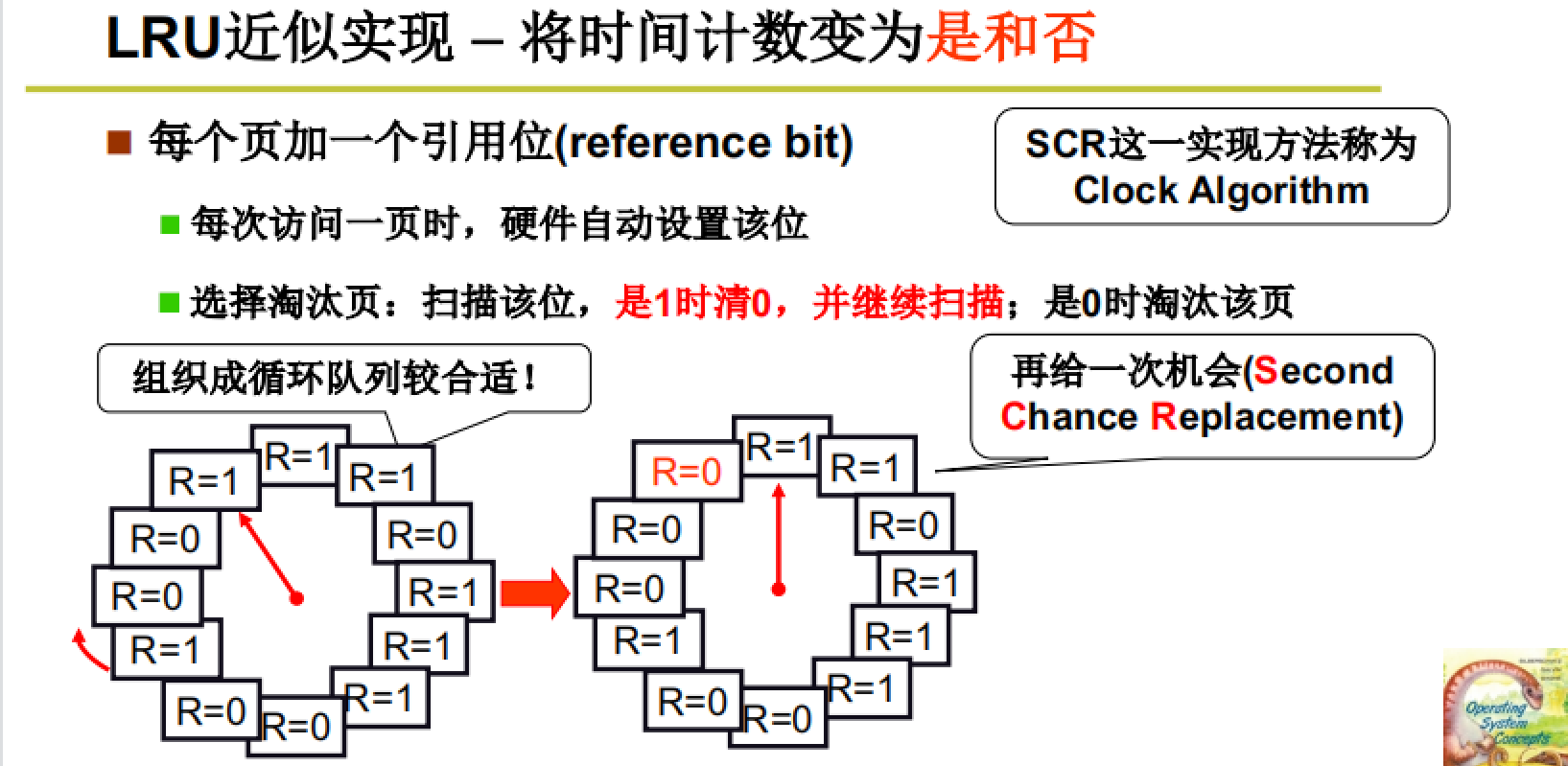
如图所示,每一个页加一个引用位,每一次访问此页时就将该位置为1;而后在缺页而选择淘汰页时,将该位为1的页置0,该位为0页淘汰。
注:图中的每一个框框都是分配给此进程的物理页框。
这种方法可以很好的节省资源,因为我们可以将页的引用位放到页码表里,当MMU进行查询时自动执行置0操作,而不需要像前面那样维护一个复杂的数据结构。
clock算法的分析与改进(双指针)
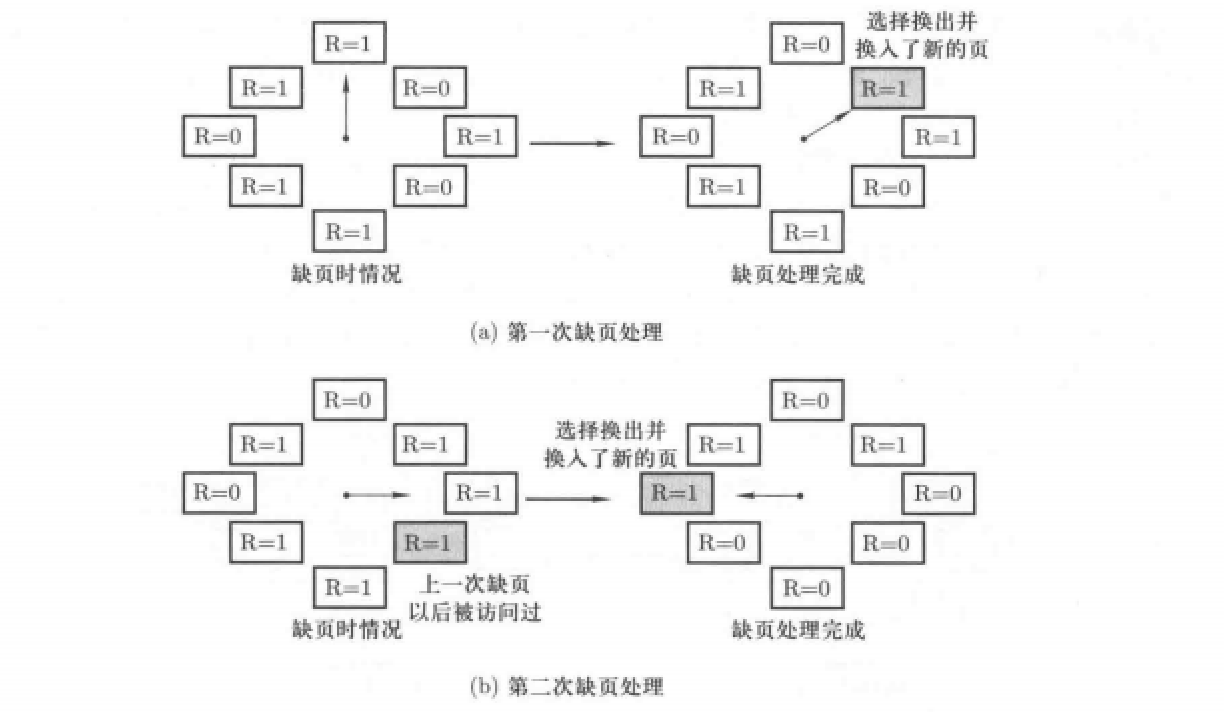
原始clock算法虽然可以节省很多资源、很高效,但是其对LRU的近似并不好。
我们看下面这个例子:

因为现在的计算机内存都比较大,缺页的情况发生的很少,所以会导致所有页的引用位被置1;而后在缺页时选择淘汰页时,会把所有的页的引用位都归零,并选取其中一个进行调出;这样就会导致clock算法退化为FIFO算法。
问题所在:记录的历史信息太长,导致“最近没有使用近似最少使用”中的最近没有体现出来
问题解决:定时清除R位。使用双指针的方式进行,快指针用于清除,慢指针用于选择淘汰页。
页框个数分配和全局置换
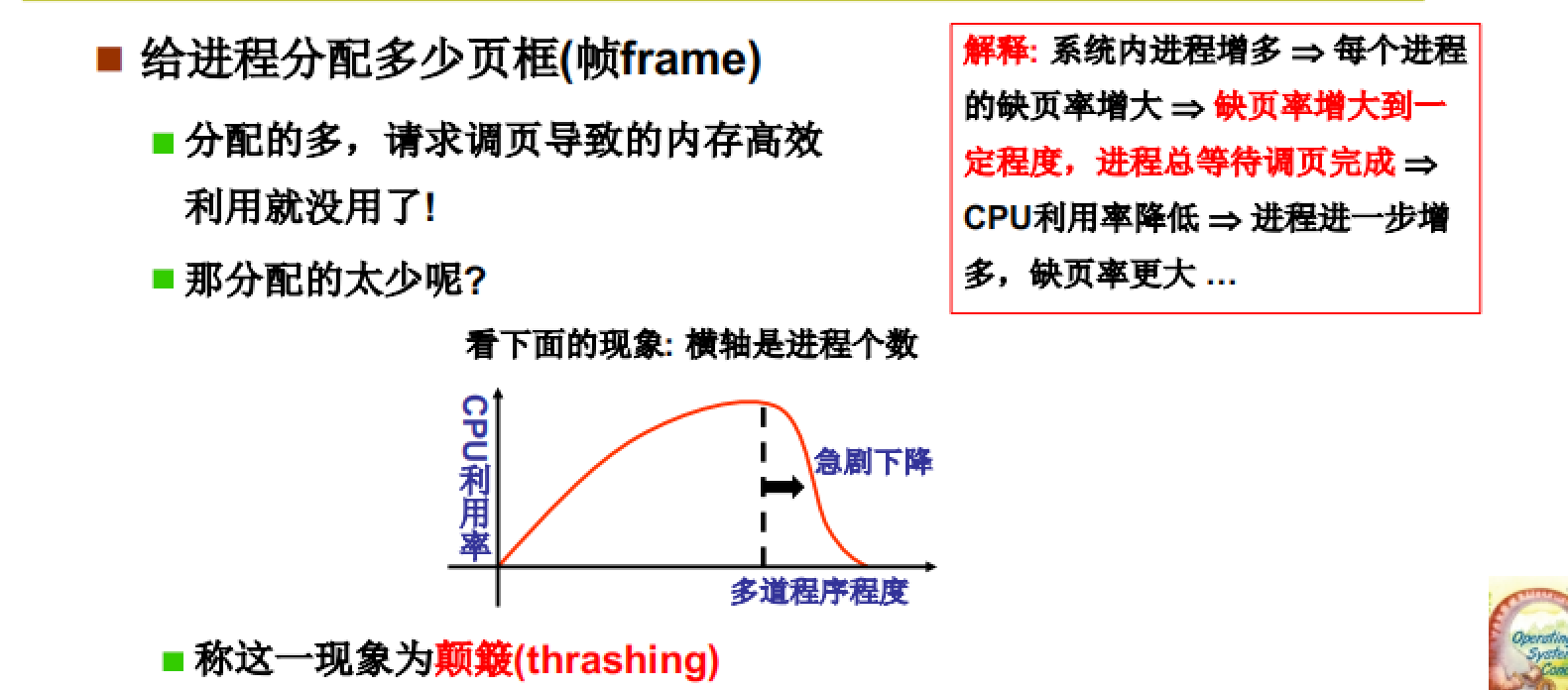
如图所示,给每一个进程分配的页框数目是一个很需要考虑的问题:分配的多会使得换入、换出机制的失效,分配的少会导致颠簸现象(本质还是缺页)
分配页框的个数也有很多算法来计算,一般思想是:计算一个工作集,使其可以覆盖局部。这里我们不再介绍。
写在最后:总结
这一节我们介绍了一个规整的虚拟内存的实现:通过换入、换出机制保证每一个进程都有一个固定大小的虚拟内存空间。同时介绍了换入换出机制的原理和实现,其中涉及到很多算法以提高换入、换出的效率。
到这里,操作系统中的核心视图——多进程视图就学习完毕了。后面我们将进行IO设备驱动、文件管理等的介绍与学习。



