(第八节)操作系统--磁盘管理和文件系统
写在最前面:
在上一节我们学习了两个简单的IO设备驱动管理–显示器和键盘,通过对这两个设备的学习,我们理清了
printf和scanf的实现流程,同时也看到了文件视图在操作系统中的作用。
在本节中,我们将更加深入的学习这个操作系统的第二个核心视图–文件视图。我们将从磁盘出发,层层递进,完成五层抽象机制,最终实现整个文件系统的构建。
磁盘工作的基本原理
磁盘工作的原理
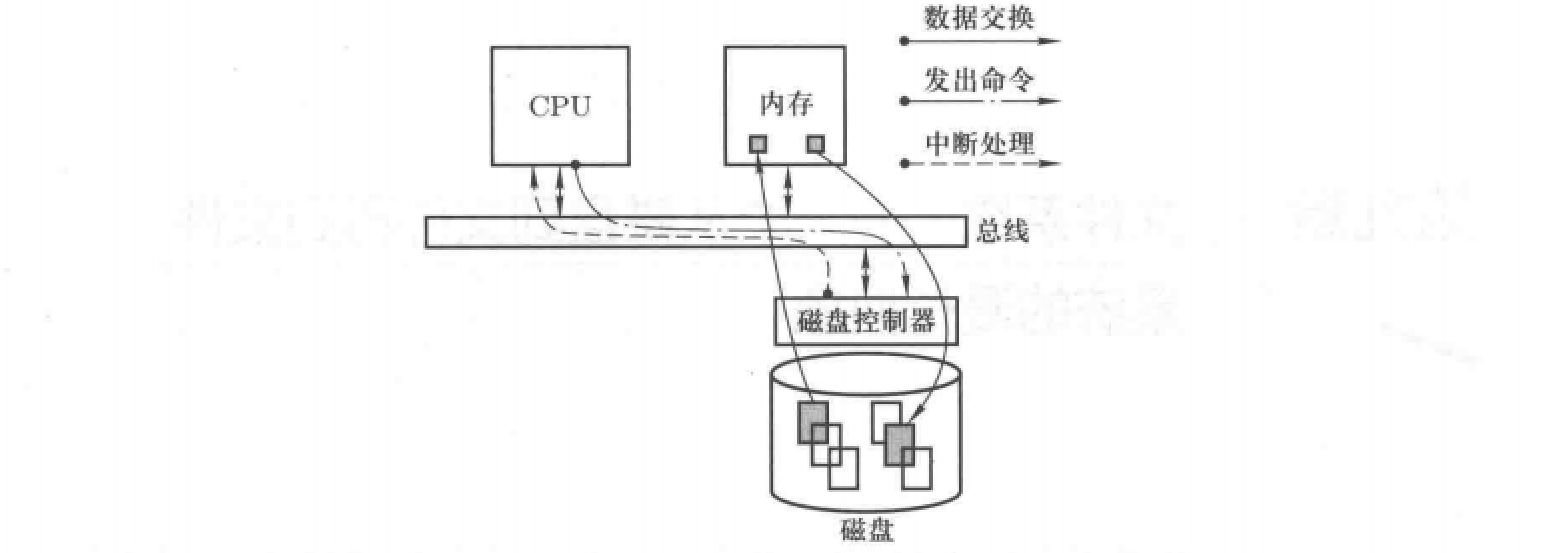
磁盘的工作原理与上一节中介绍的显示器、键盘一致,都是包含两条主线:
使用磁盘:CPU发送命令给磁盘设备,最终落到“out ax,端口号”磁盘中断:即磁盘完成工作后告诉CPU,CPU在中断处理中完成后续工作,比如将磁盘读入的内容放到内存buf等。
磁盘工作的过程
磁盘的基本构造
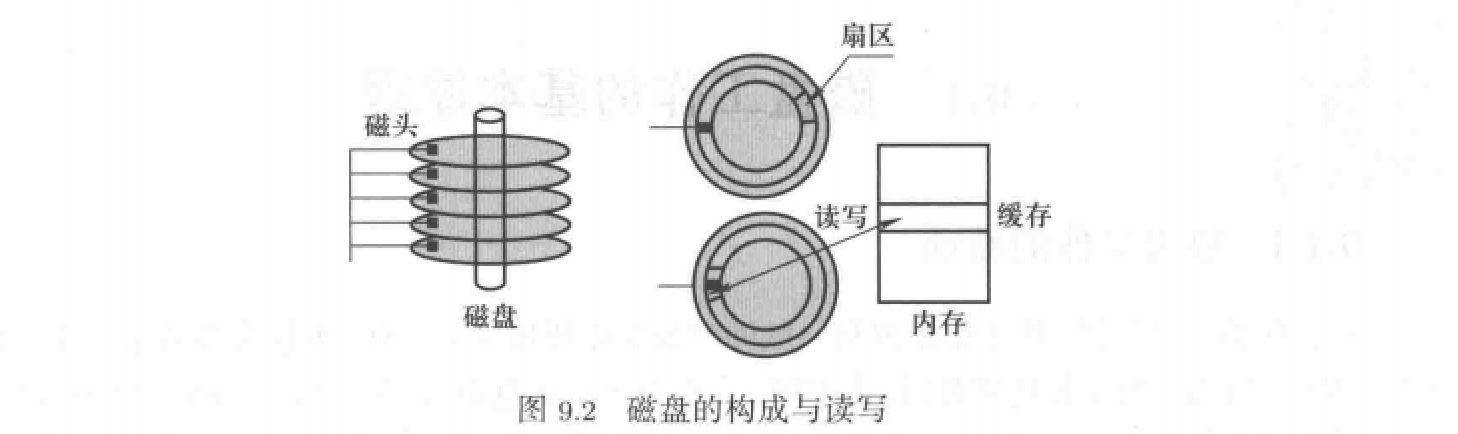
如图所示,一个磁盘由多个盘面组成,也就是图中的一层层的圆盘;而一个盘面又可以分为多个半径不同的同心环,这些同心环被称为磁道;每一个磁道又可以分为多个扇区,这是磁盘读写的基本单位。同时不同盘面的同一个磁道形成柱面。
磁盘读写的具体过程
如上图所示,在磁盘中有一个装置叫做磁头,每一个盘面都会有一个磁头,并且不同盘面的磁头是绑定在一起的,也就是说不同的磁头会对应不同盘面的同一个相对位置。而后将对应磁头上电即可进行扇区的选择和后续读写。具体的步骤可以分为以下几步:
柱面C的选择:通过控制磁头的移动选择对应的柱面。磁道的选择:本质是磁头的选择,将对应磁道上的磁头上电即可扇区的选择:选择完磁道后,即可旋转盘面将需要的扇区S转到上电磁头下方- 完成
读写:在磁盘扇区和内存缓存之间进行。
使用磁盘的直观方法
通过上文对磁盘工作原理和工作流程的介绍,我们可以得出使用磁盘完成读写的直观方法:CPU告知磁盘要读写的柱面C、磁头H、扇区S以及内存缓存位置和读写长度即可。当然在传入命令之前还需要获取这些信息的端口地址。
具体的实现代码如下:

如上图代码所示,实现代码主要包含两个函数,hd_out用于将信息传入对应端口,port_write完成数据交换。
其中对于hd_out函数的参数我们需要知道:
drive:为驱动器信息nsect:为读写长度信息sec:为扇区信息head:为磁头信息cyl:为柱面信息cmd:为读写类型信息
通过将这些信息放到控制器对应的位置即可完成后续的数据交换。
注:磁盘与内存之间进行数据交换是通过磁头进行的。磁头上电,读磁盘就是磁信号转换为电信号;写磁盘就是电信号转换为磁信号。数据的传输还是通过总线。
生磁盘的使用
第一层抽象:从扇区到磁盘块的请求
问题引入:CHS机制的复杂性
前面我们介绍了磁盘读写的流程:通过给定C、H、S定位到确定的扇区,而后进行数据交换。但是,对于上层用户来说要想准确定位到一个扇区,需要对磁盘的结构了解,还要知道这个磁盘有多少柱面、多少磁头、多少扇区等,这对于用户来说太复杂了。
所以,有必要引入新的机制来简化用户对于磁盘读写的操作,采取的方法就是——编址方案。
问题解决:新的编址方案
新的编址方案就是将CHS寻址与扇区号建立一个映射,换句话说,就是给每一个扇区编号,用户直接调用扇区号即可访问,CHS地址的转换由操作系统自动完成。
扇区编号方案选取
既然要给扇区编号,就要有一定的规范,接下来我们就来介绍一下这个规范:
首先确定0号扇区的位置,一般是0柱面(最外面的柱面)、0磁道(最上面的磁道)、0扇区(磁盘旋转整圈以后的扇区)为0号扇区,之后将与此扇区同一个磁道上的扇区依次进行命名。如下图所示:
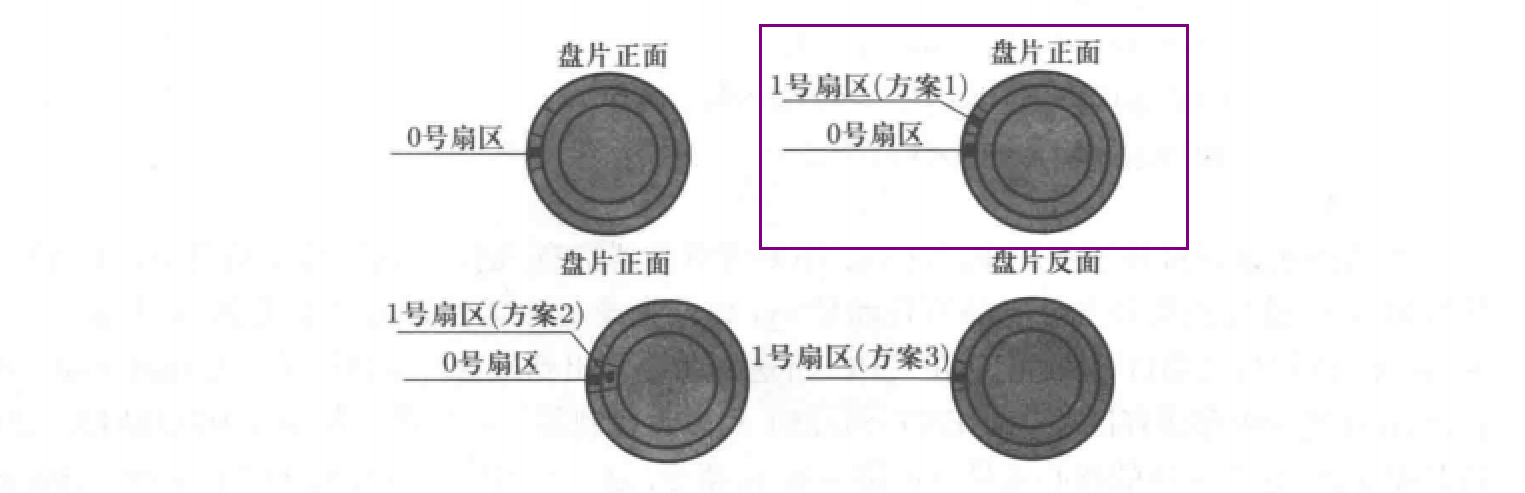
采取这种编号方案的原因
为什么要按照上图的方案1 来编号呢,其他几个方案为什么不行?
答案很简单,因为第一个方案可以提高磁盘读写的速度。
至于为什么与其他方案相比第一种方案读写较快,一个很重要的原因就是第一种方案在读写连续扇区时不需要进行磁道的切换。(与旋转磁盘、数据传输相比,磁道切换花费的时间最多)
注:磁盘访问时间=写入控制器时间+寻道时间(即柱面的选择,大约10ms)+旋转时间(即磁头在磁道上旋转,半周大概4ms)+传输时间(磁、电信号转换,大约0.3ms)
编址后地址的换算
通过第一种方案为扇区编号,可以得到编址结构如下:

当然,无论是采取哪一种编址方案,最终都要落实到CHS地址上。按照第一种方案可以得到扇区号和CHS扇区地址的计算公式:
根据上述公式可以推出由扇区号到CHS地址的计算方法:

到这里,就完成了CSH到扇区号的完整映射,用户只需要给出扇区号,操作系统就可以根据上公式自动换算出其具体地址,而后由out指令将参数信息传入磁盘控制器最终实现磁盘读写。
但是,磁盘的第一层抽象不仅仅只有编址方案,还有:从扇区到磁盘块的抽象
从扇区到磁盘块的抽象
因为磁盘进行数据交换花费的时间相比于磁道切换、磁盘旋转花费的时间可以忽略不计,所以将多个扇区抽象为一个磁盘块可以显著提高读写速度(不要每一个扇区读写完毕后都要进行磁盘旋转了)。
磁盘块的抽象是以空间换时间,但是现在磁盘越来越大而读写花费时间上却没有太大的进步,所以这种交换是值得的。

所以,使用盘块号取代扇区号,其换算关系如下:
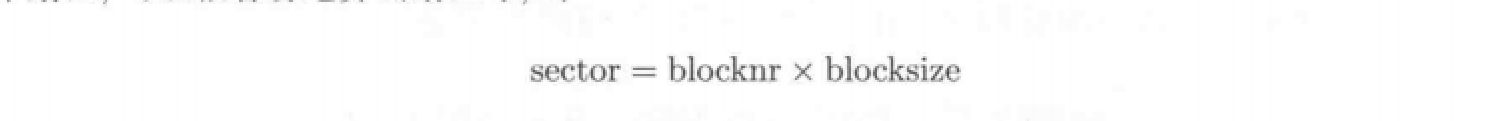
其中blocksize为磁盘块的大小即所含扇区的个数。一般来说,磁盘块越大则读写的效率越高,但是对空间的浪费也就越大。
不论如何抽象,最终还是要转换为CHS地址才可以真正完成磁盘读写。
承上启下
前面我们介绍了磁盘读写的第一层抽象:
扇区到磁盘块的抽象。用户只需要提供盘块号就可以完成扇区号、CHS地址的计算,进而准确定位到一个具体的扇区并完成读写操作请求。
但是,在实际操作系统中往往是多个进程产出多个磁盘块请求的情况,所以就要使用一个队列来管理这些请求,这就是磁盘管理的第二层抽象。
第二层抽象:多个进程产生的磁盘请求队列
抽象的实现与后续执行步骤
多个进程请求磁盘读写,使用请求队列来控制进行的请求。
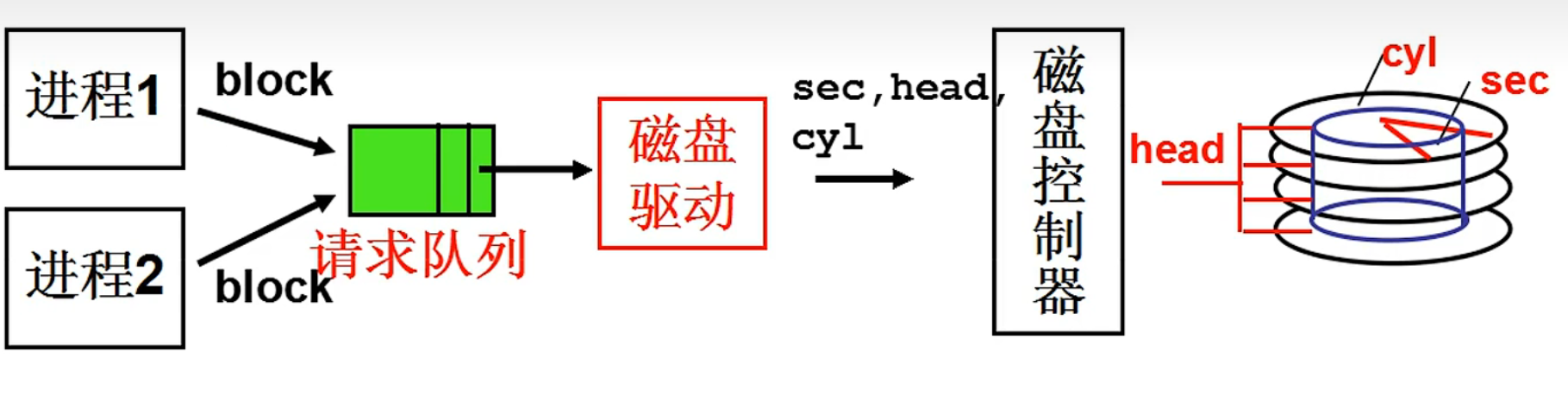
其实问题的关键不在于请求队列的建立,而在于如何从队列中选择下一个要执行的请求。这要综合考虑,使得平均访问延迟最小。
所以,下面我们将从最基本的调度算法讲起,而后一步步优化,最终给出一个较优的调度算法。
调度算法的选择
调度算法的目的就是为了使得访问延迟最小。下面我们介绍几个调度算法:
调度算法1:
FCFS算法

- 算法描述:最先请求的最先响应。
- 算法特点:最直观最公平的调度算法
- 算法缺点:磁头的来回奔袭,读写时间较长
调度算法2:
SSTF算法
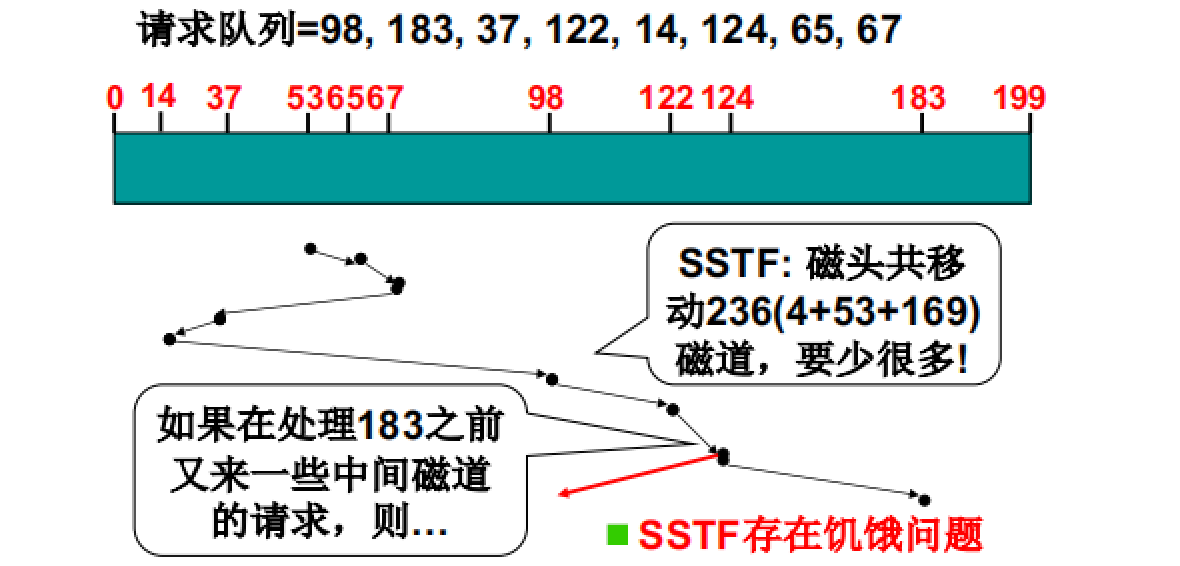
- 算法描述:优先选择距离最近的请求
- 算法特点:可以显著降低磁头移动的数目从而降低访问延迟
- 算法缺点:可能会导致一些距离局部较远的请求一直无法被响应,从而导致饥饿问题。
调度算法3:
SCAN算法
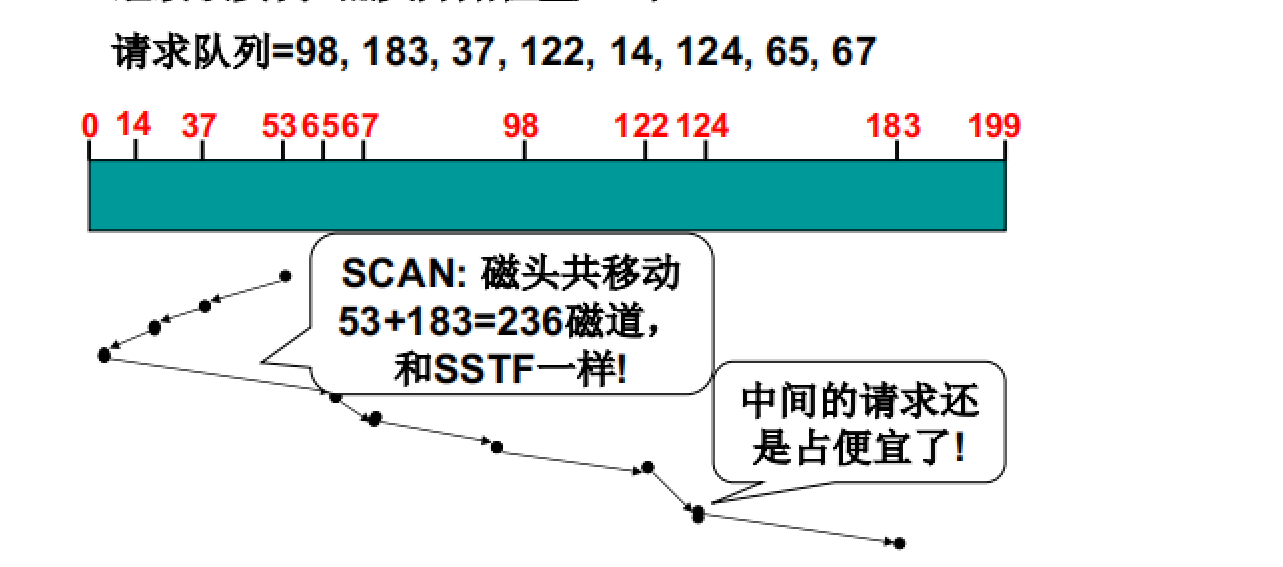
- 算法描述:在SSTF算法的基础上中途不回折
- 算法特点:可以显著降低访问延迟,同时也可以解决饥饿问题
- 算法缺点:如果从中间开始启动也可能会导致公平性问题
调度算法4:
C-SCAN算法即电梯算法

- 算法描述:在SCAN算法的基础上直接移动到另一端
- 算法特点:即兼顾了SCAN算法的优点又可以使得两端请求都可以很快处理
磁盘调度的补充
磁盘调度发生在磁盘中断后,即完成当前请求的读写任务后就会告知CPU,之后就会在队列中选择合适的盘块号进行下一次的读写。
关于这些调度算法的代码实现这里不再赘述。(之后也不会在各个部分介绍代码,而是重在概念、流程,在最后会整合磁盘管理的流程,到时会附上对应的代码)
在操作系统中有很多地方涉及到调度算法,比如:多进程切换时的调度、内存换入换出时的调度等,对于这些调度算法我们不需要死记硬背,而是要学会自己去推导,一般常用的推导思路:从FxFx开始,而后找出缺点,针对其进行优化等。
承上启下
前面我们介绍了操作系统对于磁盘管理的第二层抽象——多进程、多请求的处理。我们通过队列管理请求信息并使用调度算法确定请求执行顺序。
下面就要从数据的存储方面进行进一步优化,也就是第三层抽象——磁盘请求到高速缓存。
第三次抽象:从磁盘请求到高速缓存
磁盘读写与高速缓存的联系

如图所示,高速缓存是位于用户态buf和磁盘之间的一个区域,其作用就是为了减少磁盘读写次数以提高读写效率。
因为磁盘读写是以磁盘块为单位的,根据局部思想,程序访问的地址往往在同一个磁盘块,所以这时就不需要重复去读写磁盘了,而是将此磁盘块内容保存在高速缓存中以便于后续使用。如果访问内容已经在高速缓存,就不需要进行后续的请求req与电梯队列了。
承上启下
通过上文的三层抽象,用户只需要通过盘块号调用
bread函数即可完成磁盘的读写。
但是通过盘块号进行磁盘读写对于用户来说还是不够方便,因为用户不仅要了解磁盘块的概念、磁盘块的大小,还要记住数据存储的盘块号以便于后续访问。所以为了使得磁盘的数据访问更加符合人们习惯,引出了操作系统对于磁盘管理的进一步抽象——基于文件的磁盘使用。(文件抽象又可以分为两层,下面我们会依次进行介绍,由浅入深)
基于文件的磁盘使用
第四层抽象:引出文件
raw disk即生磁盘对于普通用户来说还是太复杂了,所以操作系统引入一个更高层次的抽象:文件
文件是什么样的?
- 用户眼中的文件就是一个
字符流。 - 磁盘上的文件则是由一个个
盘块拼接而成的。
到这里,本小节内容就已经出来了:如何将字符流与盘块号对应起来。即建立字符流到盘块集合的映射关系。
映射的作用
看下面这个例子:
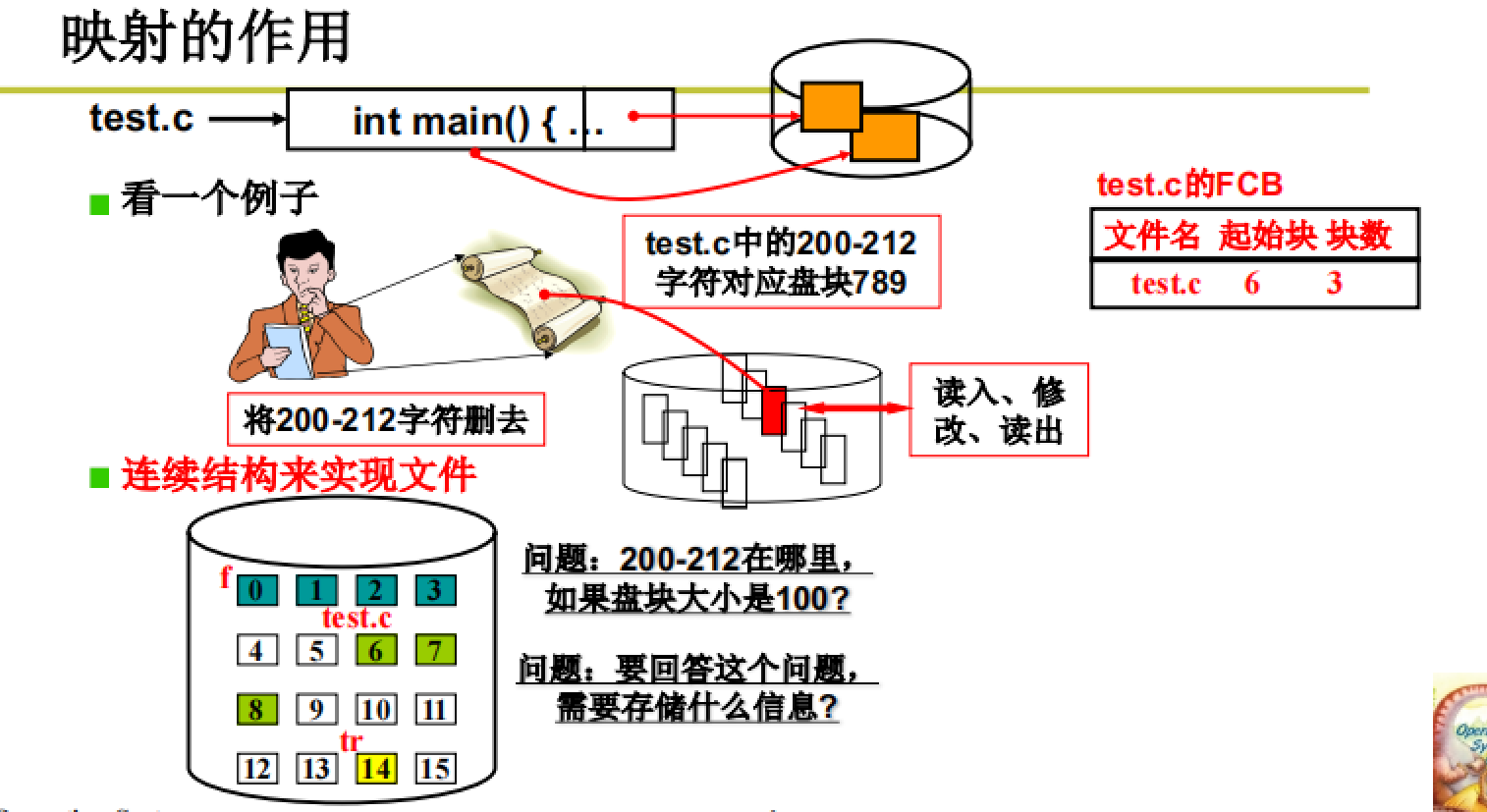
如图所示,在用户眼中这个test.c文件就是一个多个字符组成的字符流,可以直接在这个流中进行修改;而在最终在磁盘中,字符流的修改就要具化到一个具体的盘块,之后进行内容修改。
映射就是将用户对于磁盘的使用具体到硬件的实现,即完成字符流到盘块号的转换。
映射的建立
文件是存放在磁盘上的盘块上的,所以要建立映射关系,只需要在FCB中初始化一个数据结构,记录当前文件处于的起始块和块数即可。
所以这时用户想对文件进行操作只需要给出文件名和所操作区域在字符流的位置就可以了。
文件存储的结构
前面我们介绍映射关系时默认使用的文件存储结构是连续结构,这种方式有很多缺点。下面我们会具体介绍一些文件存储的结构并分析其优缺点。
存储结构1:
连续结构
结构视图:
视图介绍:创建文件时,会将对应的字符流依次存放在盘块号连续的多个磁盘块上,然后将第一个磁盘块的盘块号放到此文件的FCB中。用户需要访问此文件时,就可以通过文件的FCB取出起始块号并与pos计算得出磁盘块块号。
映射表的建立:如图所示,只需要保存文件名、起始块号、文件长度即可。
优点:访问速度很快,可以根据字符位置很快计算出磁盘块块号
缺点:文件改写很麻烦,同时对文件进行追加内容时可能会覆盖掉其他文件。
存储结构2:
链式结构
结构视图: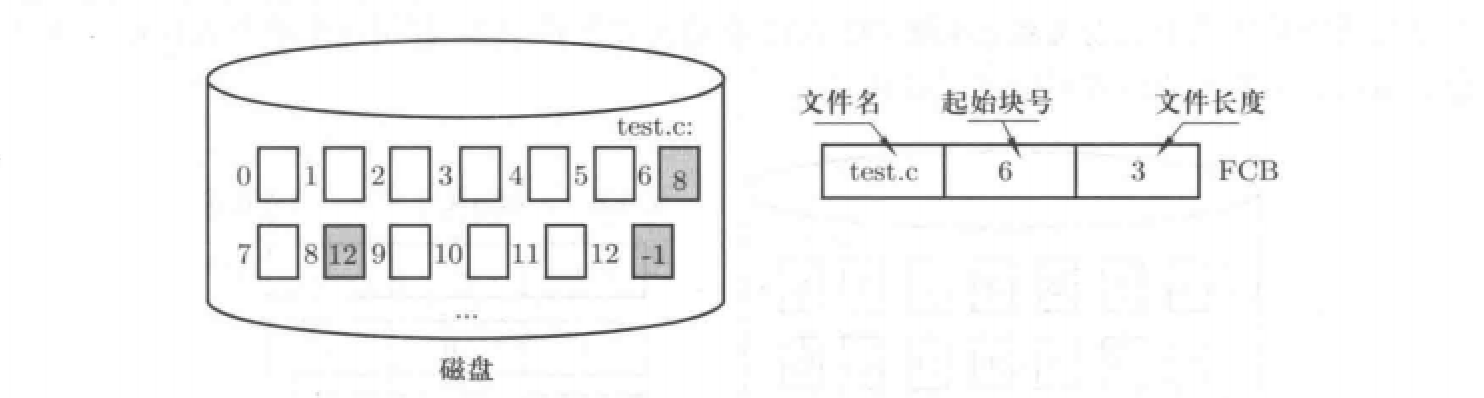
视图介绍:字符流的存储不需要连续,而是可以存放在不同的磁盘块中,只是每一个磁盘块中都要存储下一个磁盘块的盘块号。
映射表的建立:如图所示,只需要保存文件名、起始块号、文件长度即可。
优点:方便对文件进行修改。
缺点:文件读的效率很低,因为涉及到跳转。
存储结构3:
索引结构
结构视图:
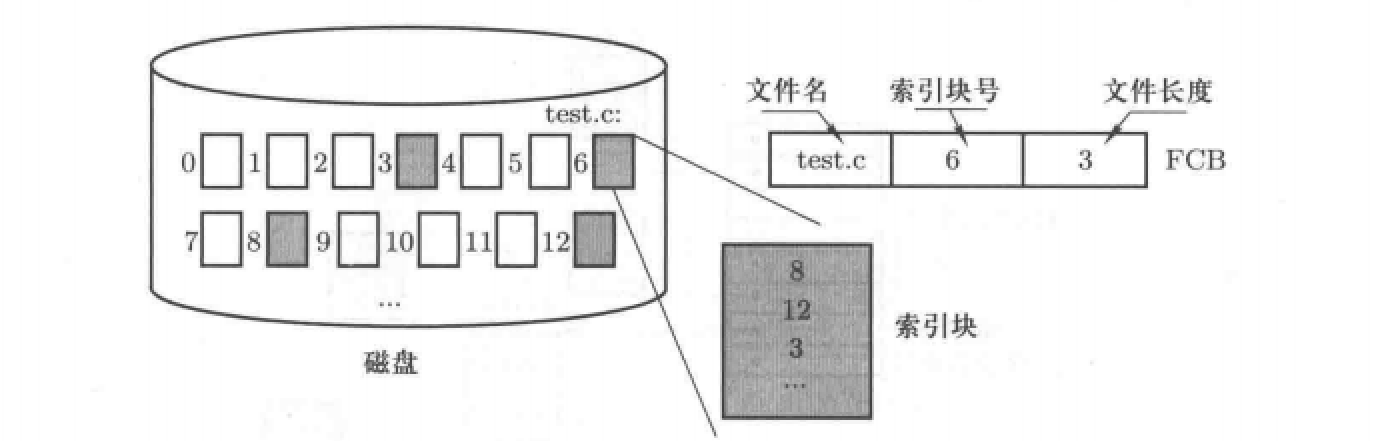
视图介绍:对于一个文件,其字符流被分为多个逻辑块,这些逻辑块被存储在不连续的磁盘块中,也是拿出一个磁盘块作为索引块,用于存储该文件各个逻辑块存储的磁盘块块号。
映射表的建立:需要存储文件名、索引块号、文件长度
优点:读写效率都较高。因为对于读操作,索引存储结构是顺序结构和链式结构的折中;而对于写操作,由于是存储在不连续的磁盘块,所以效率较高。
缺点:没有考虑到文件大小的因素,即小文件不需要索引块、大文件一个索引块存储不了。
存储结构4:
多级索引结构(** **)
结构视图:
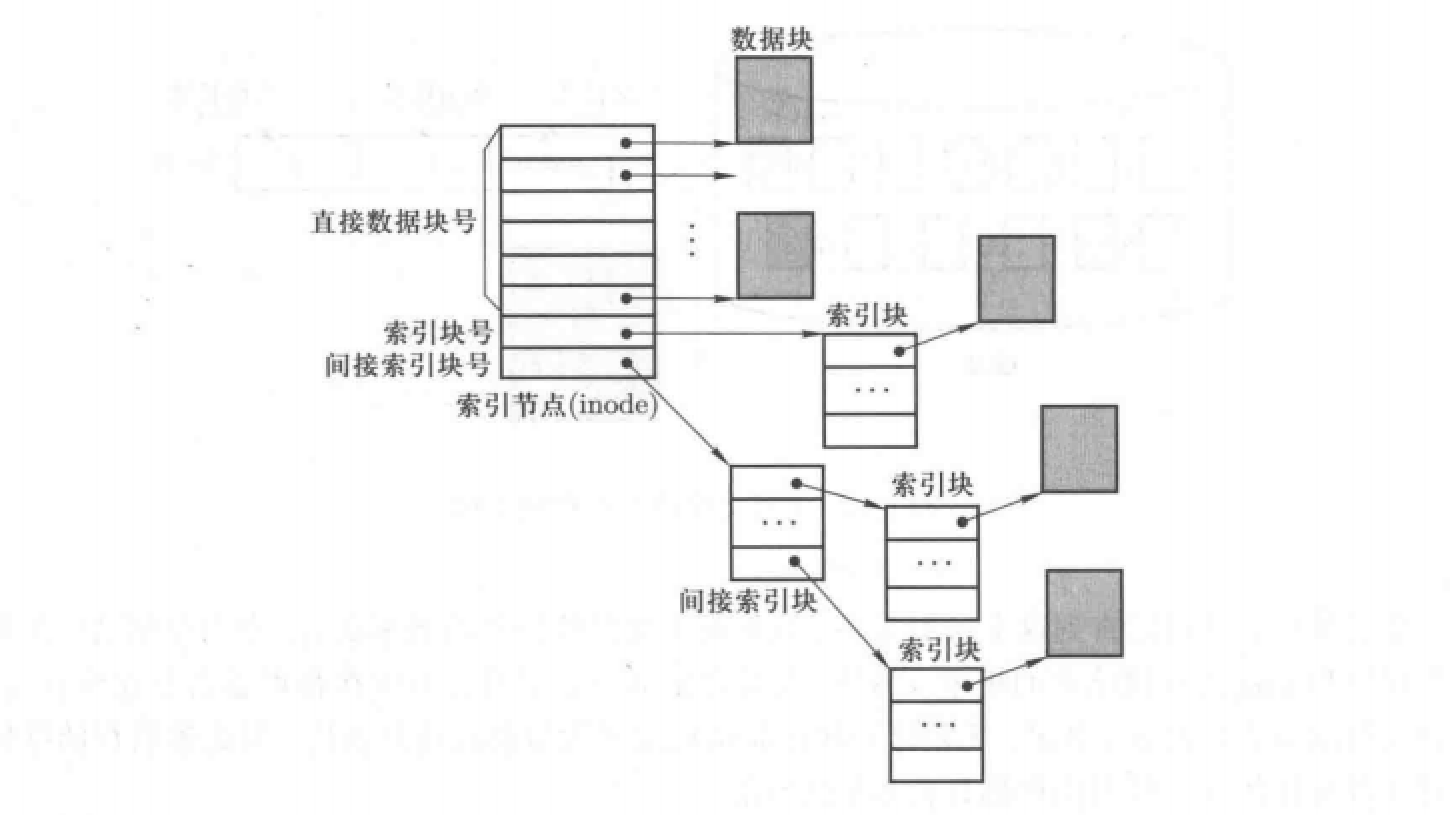
视图介绍:考虑到文件大小的因素。对于小文件可以直接使用直接数据块号;中文件使用一阶索引;大文件使用多阶间接索引。这个模式类似内存管理中介绍的多级页表。
这种存储结构就是现在实际操作系统使用的。
承上启下
通过前面4层抽象,我们已经可以通过文件完成磁盘的读写操作。
但是前面我们是直接告诉了文件的位置,而后获取到inode。在实际情况下,我们需要根据文件名在文件表里查询以找到此文件,这个过程就是第五层抽象——文件系统的建立。
第五层抽象:将磁盘抽象为一个文件系统
不论对磁盘如何抽象,最终到用户眼中就是一棵目录树,这个树就是一个文件系统。

目录树即文件系统就是对磁盘块的进一步抽象,与文件抽象不同,文件抽象是指如何将一个文件映射到多个盘块,而文件系统的抽象是把所有的盘块都放到这个目录树中,从而在用户层面实现一个直观的使用界面。
从多个文件开始:
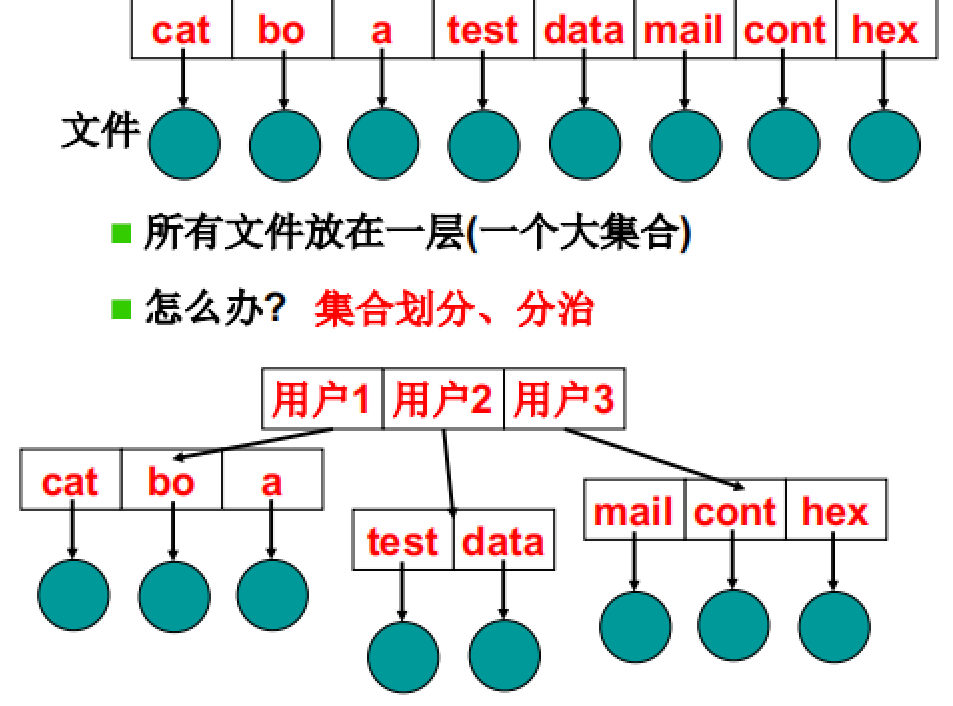
从单层目录到集合划分目录,为了方面用户进行管理和使用。但是仍不能很好解决问题。
引入
目录树
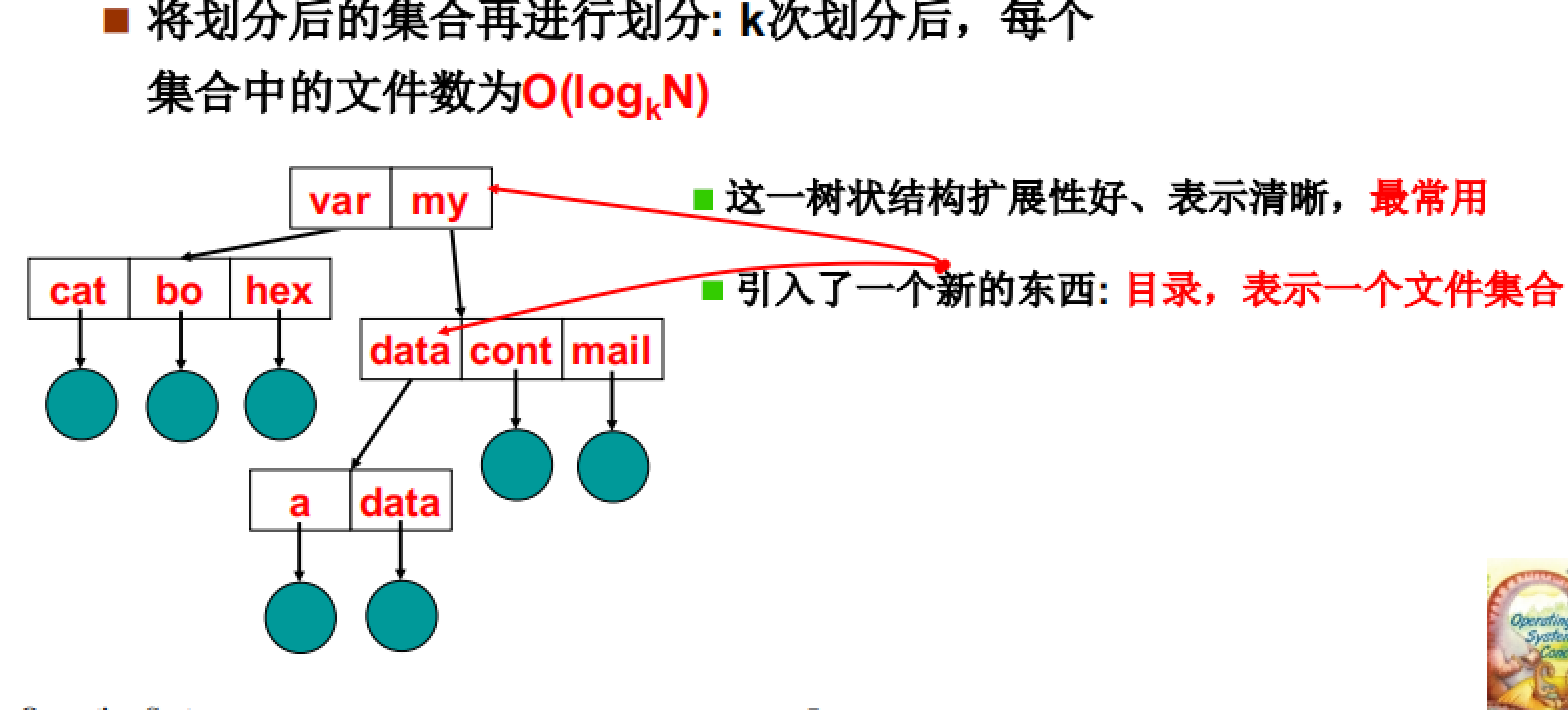
如图所示,目录树是分治思想的体现,经过划分后每一个集合中的文件数会变得很少。并且这种树结构扩展性好、表示清晰。
同时,有了目录树就要引入一个新的概念:目录即文件集合。
目录的实现:
如何通过目录定位到具体的文件是一个关键问题,即通过树根到叶子节点。
如下例:给出/my/data/a,如何得到a文件的FCB。
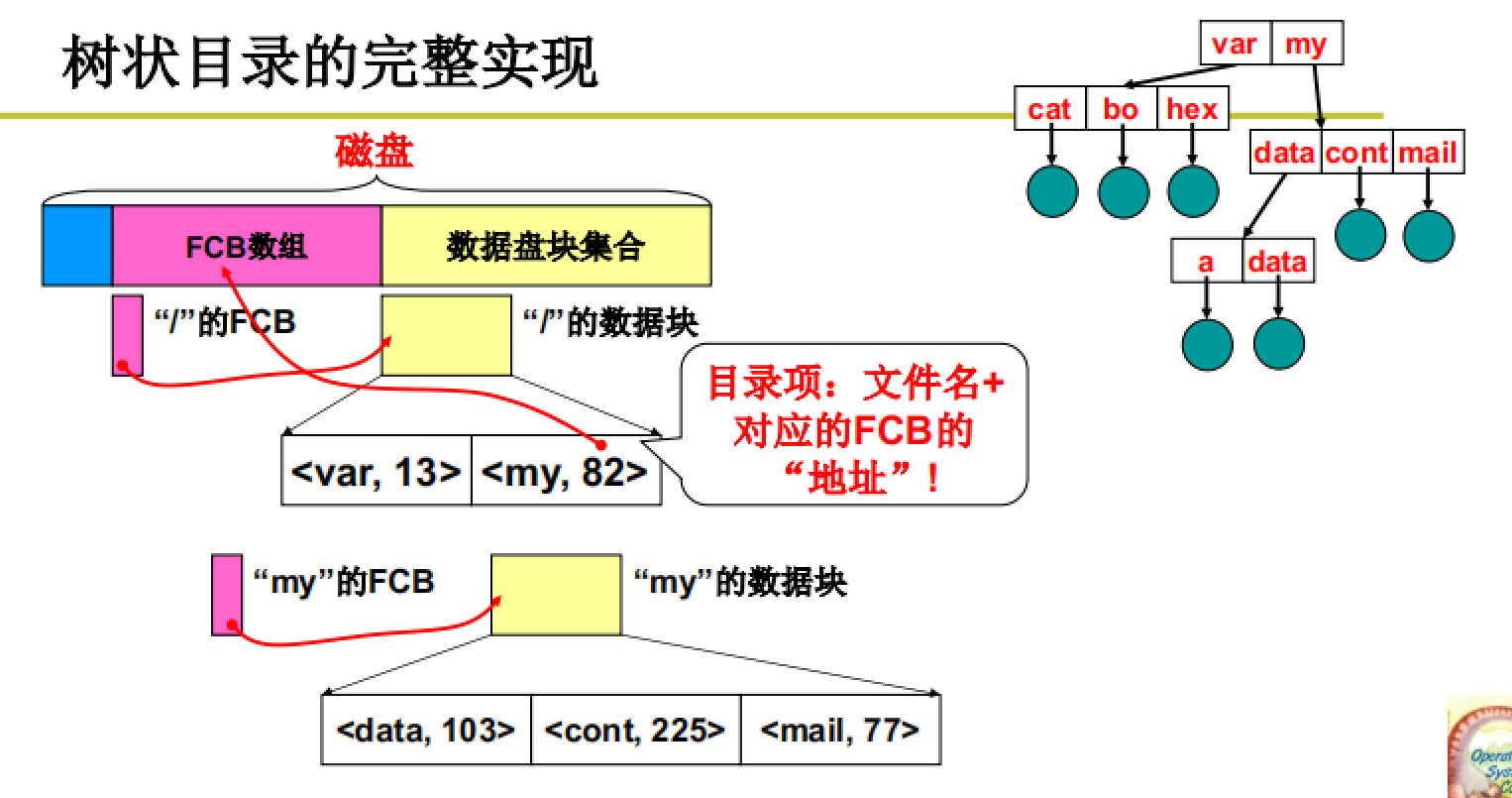
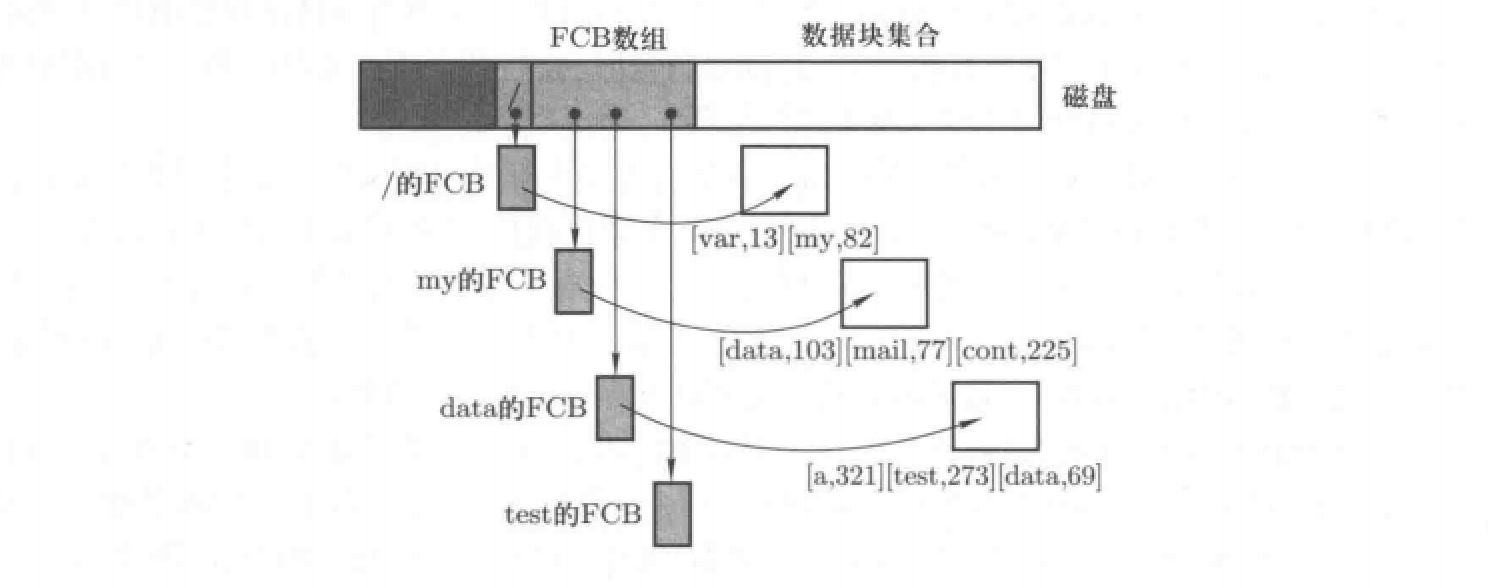
如图所示,树状目录的完整实现是通过FCB数组和数据盘块集合实现。其中FCB数组存放着磁盘中所有文件的FCB,而一个文件的FCB中又保存着这个文件逻辑地址与磁盘块的映射,换句话说,找到了FCB就可以进入磁盘获取到该文件。
所以进行目录解析的流程如下:
- 首先获取到
“/”根目录的FCB,这个FCB是磁盘初始化时就有的,且在FCB数组的第一个位置。 - 通过根目录的FCB中存储的物理盘号信息可以定位到具体的磁盘块进而读写其中内容,此例中我们假设其中的信息为
[var,13]和[my,82]等,其代表着var和my两个目录的FCB在FCB数组的索引号。 - 使用路径信息进行匹配,进入
my的PCB,从而定位到my的磁盘块,在其中保存着my目录下文件的FCB地址 - 最终根据my目录下的内容定位到a文件的FCB,从而完成目录解析。
具体的解析流程如下图:
磁盘读写的流程总结
经过上文5层抽象的学习,我们已经对磁盘管理有了较为清晰的认知。下面我们将对磁盘读写的内容进行全面整理:包括
磁盘读写的流程、每一个流程涉及到的代码与各个代码之间的调用关系。通过整理,我们可以整合前文知识,更加深入的理解文件系统和磁盘管理,也可以将这部分内容与操作系统的其他模块结合起来。
磁盘读写的具体流程
下面我们将以一个
open的例子来介绍磁盘管理的具体流程:
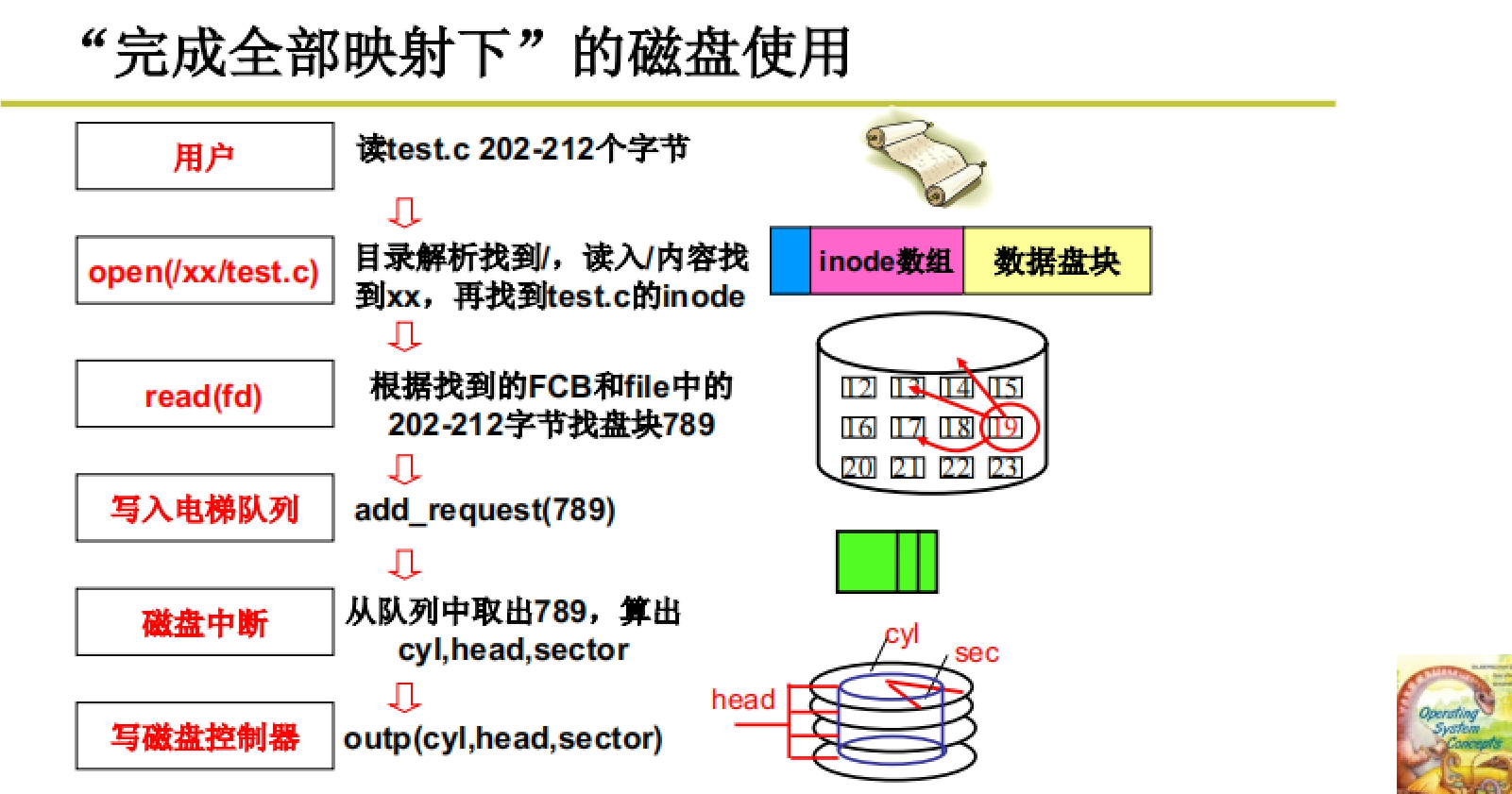
- 操作系统在安装时会将磁盘格式化,成为如下图的结构:

- 系统在启动时会把磁盘根目录文件找到,并把其inode写入内存作为1号进程的资源
- 用户创建的进程会继承这个根目录的FCB(
fork()创建进程是以复制父进程实现的) - 用户启动一个进程,调用
open(/my/data/a)打开一个文件:本质是将a文件的inode写入内存,并返回一个文件句柄fd。(会根据文件路径进行目录解析) - 用户根据此句柄进行文件操作。如
read(fd,buf,count),会根据fd找到当前文件字符流的pos,之后根据pos和文件inode中存储的索引信息可以找到pos对应的物理盘块的盘块号 - 调用
bread(block)读磁盘高速缓存,如果内容已在则直接读到内存buf;没在就获取一个空闲的高速缓存并将block信息写到bh - 发起磁盘读写请求req,根据
block计算得出扇区号,并将req加入到电梯队列,而后进程睡眠 - 磁盘控制器处理完毕上一个磁盘请求会产生磁盘中断,这时就很根据调度算法从电梯队列中取出这个请求req,并将
扇区号换算为CHS地址,利用out指令将CHS发送到磁盘控制器。 - 磁盘操作完毕再次进行中断,此时a文件的字符流数据已经存放到bh高速缓存,唤醒的进程将此内容复制到buf即可完成read。
最后,不论是这里的磁盘管理,还是第七节的IO设备管理,其执行流程是一致的,无非是在inode处进行分支,一个通过映射表定位到磁盘一个通过函数实现数据的显示。究其根本还是对于文件的使用,所以对于文件和文件系统理解十分重要,文件视图也当之无愧的成为操作系统的第二个核心视图。
注:关于文件系统和磁盘管理的内容还有部分未学习——磁盘读写过程中各个环节具体代码的实现。后续会继续补充。现在主要是要了解文件视图的框架和思想,可以将读写的流程说个大概。



