(第五节)操作系统--内存管理
写在最前面
本篇文章主要用于记录操作系统学习过程中内存管理的部分内容,学习资料为哈工大李治军老师的课程。
本文中使用的图片大多来自课程视频和配套图书,只为个人学习所用。
内存使用与分段
内存是如果使用的
程序是存储在内存中的,取指-执行是计算机工作的基本原理,CPU工作的同时内存也就跟着使用了。

如图所示,使用内存的步骤就两点:将程序放入内存、设置PC指针使得程序执行
下面就具体介绍一下如何将查询放到内存并进行执行的
程序放到内存只需要将磁盘中的编译完毕的文件读入内存即可。
如下图所示,程序放到内存中即可使用call指令进行调用。

需要关注的是要将程序放到内存中的什么位置呢?
上图中给了两个例子,显然下面的例子是对的,即从内存中取出一段空闲的空间来存放程序。
不过即便是下面的例子也有错误,因为其中的指令:call 40所跳转的位置是错误的,需要进行重定位操作。
重定位:保证对内存地址的正确访问,要进行地址翻译。
前面的例子中提到的call 40 中的40是逻辑地址,在实际使用时需要进行修改,变为物理地址。
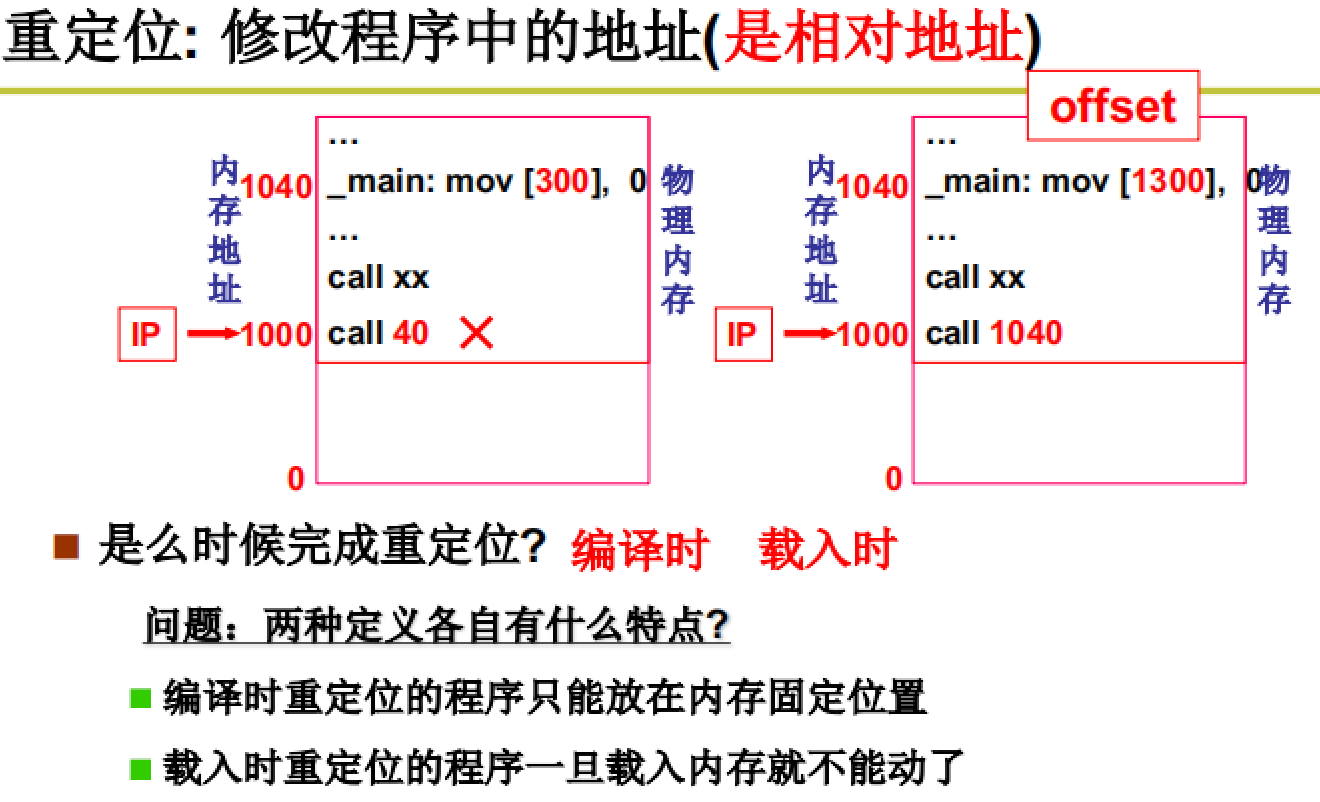
在程序载入时进行重定位操作,因为我们在编译时往往不知道哪一段内存是空闲的。
注:在一些嵌入式系统中可以在编译时进行重定位,因为某些程序载入的位置是固定的。
程序载入后还需要移动:
交换(swap)
如下图所示,进程在使用的过程中可能因为阻塞等原因需要进行移动,这时其重定位地址就会出现问题。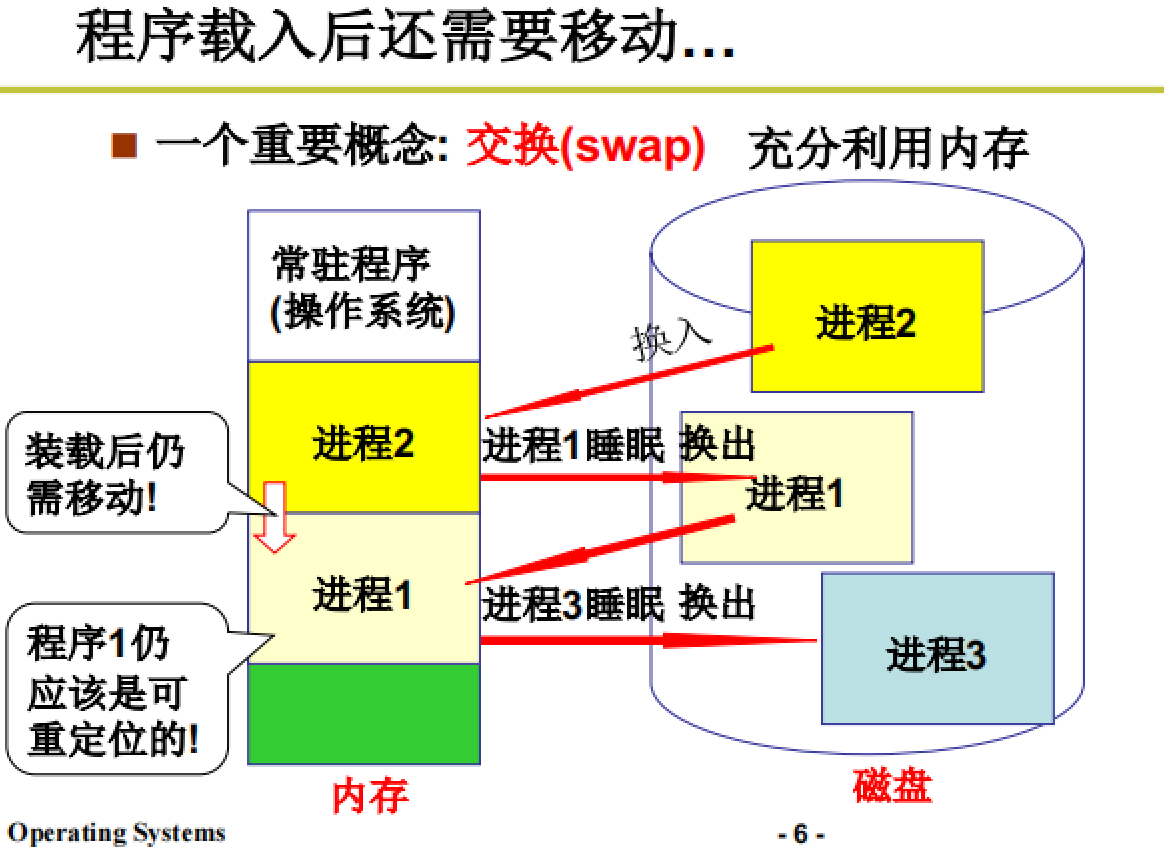
所以:重定位最合适的时机–
运行时重定位(也是我们主要要介绍的)
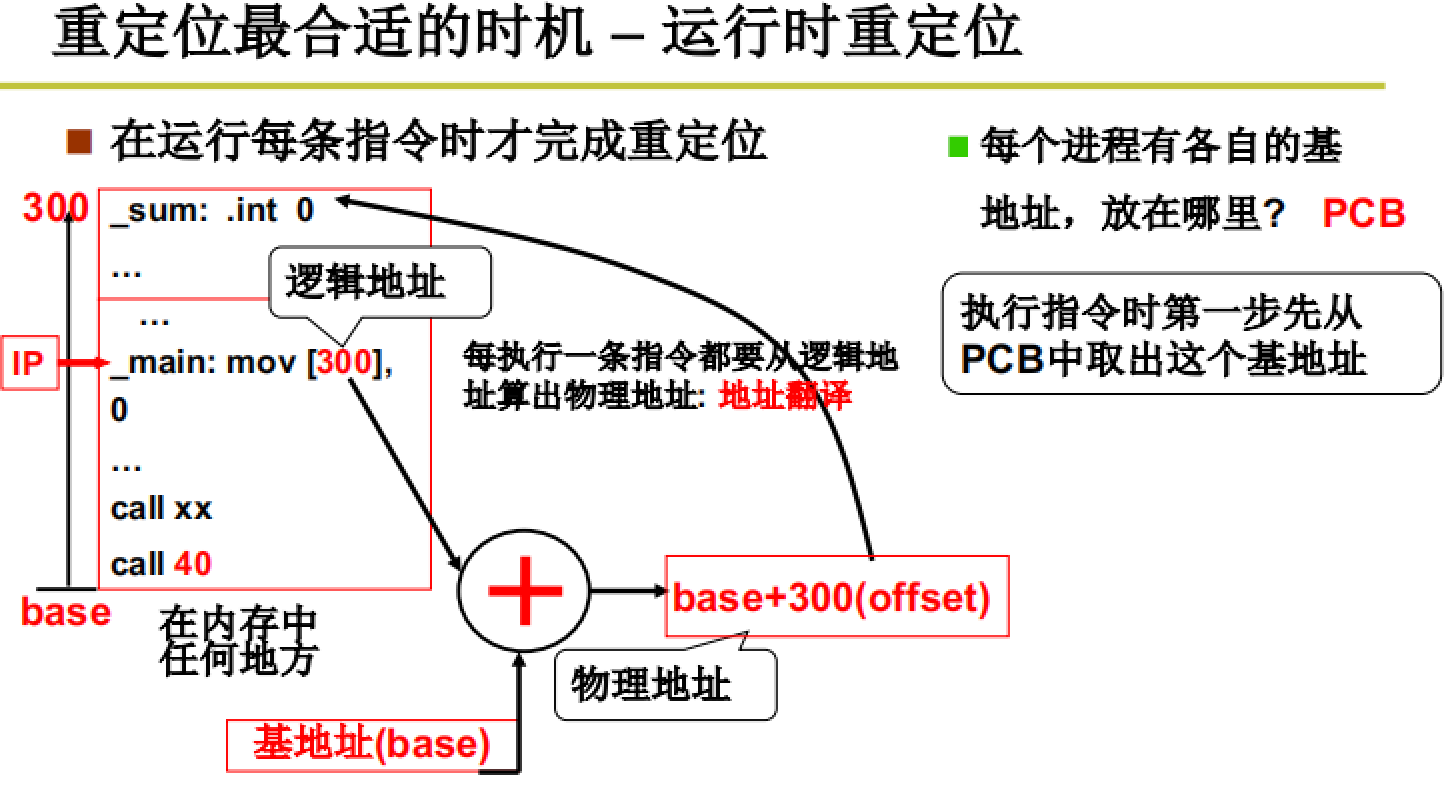
call 40 在内存中是不变的,在运行时根据base地址+offset获得新的物理地址。
而进行地址翻译时最关键的点在于获得base基址。这个基址是存储在PCB中的,在创建进程时就要将申请到的地址基址放到PCB中,并在之后的切换时不断更新基址的值。
而在进行程序的执行时,当涉及到内存地址就要先进行地址翻译,即基地址+offset=物理地址
承上启下:
上文介绍了内存使用的一个直观想法:将程序载入内存并进行地址翻译以执行相关程序。
下面就要在这个直观想法的基础上进行推进,第一个要推进的点:引入分段--将程序一起载入内存吗?
分段思想
如下图所示,程序员眼中的程序是可以分为若干段的。
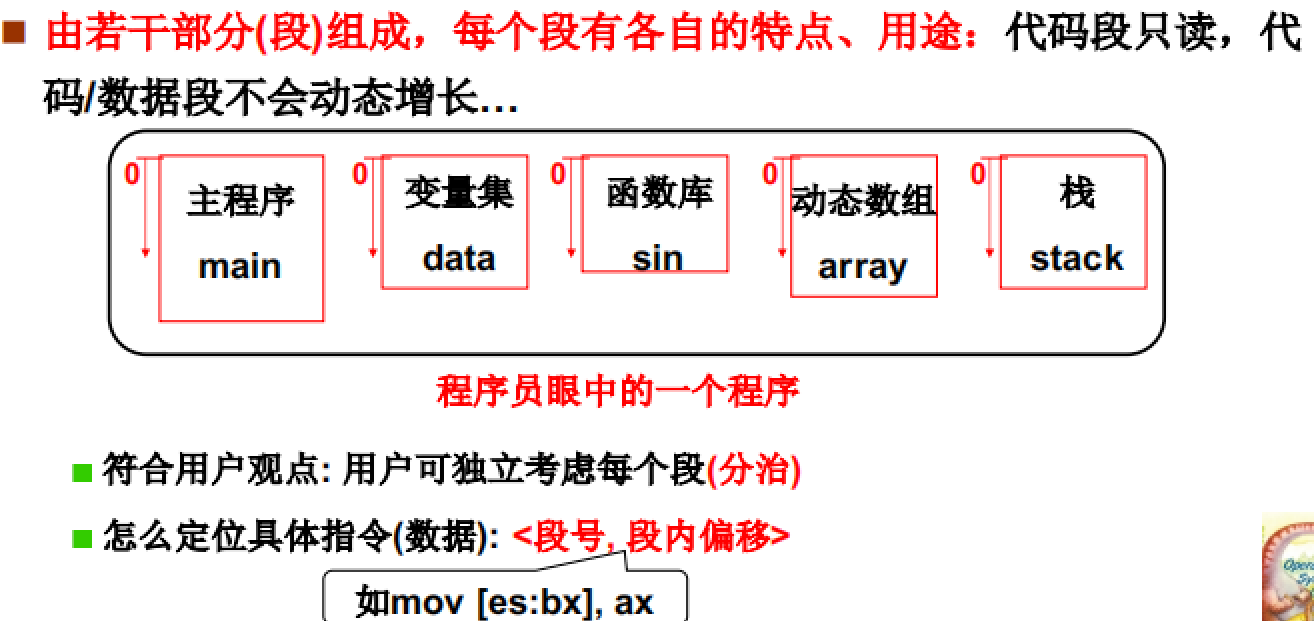
将程序按段分配可以独立考虑每个段的内容,并且每一个段有其各自的特点,如:代码段可读、堆栈段可以动态增长等,需要分开处理。
所以,程序在载入内存时也是分段进行载入的。
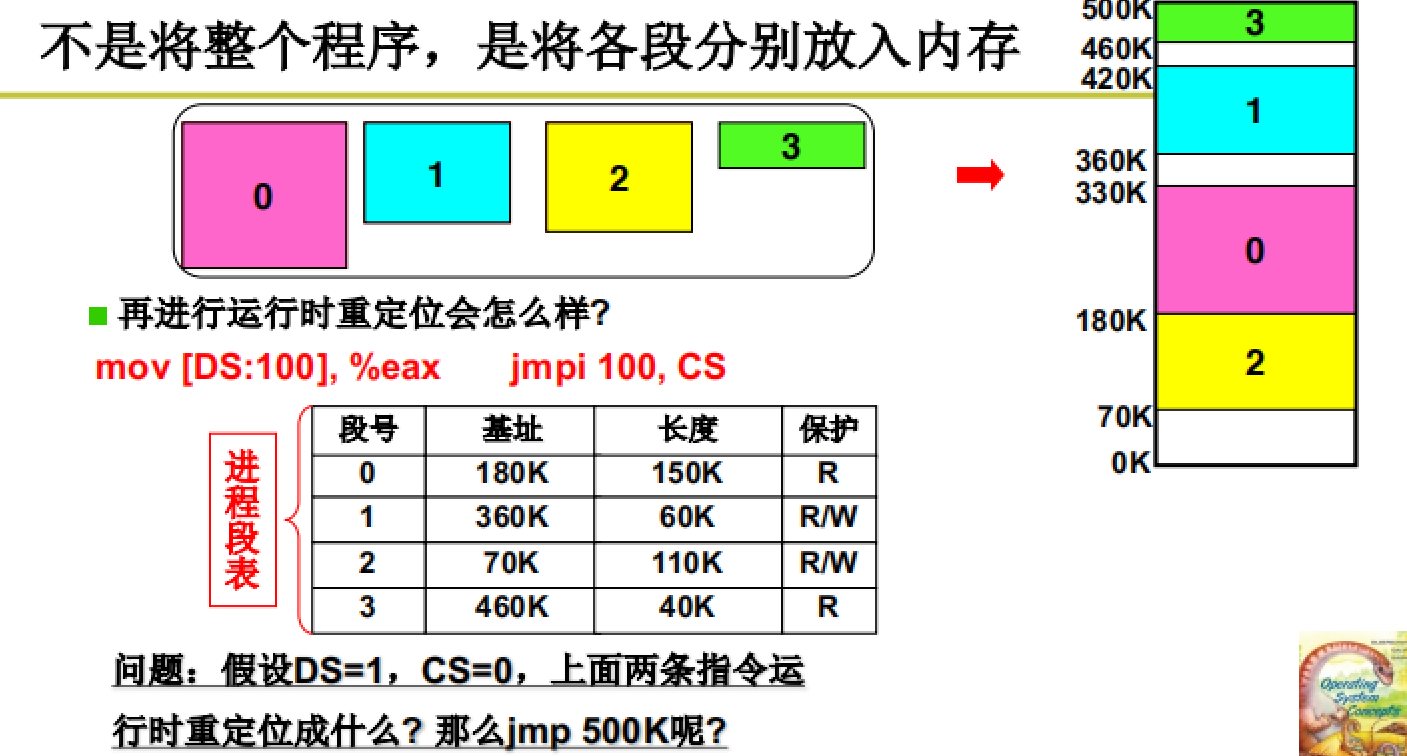
所以在进行寻址时也就不是用单纯的基址了,而是使用段基址。在PCB中就要存放所有段的基址。
strong text
这个用于存储段地址的表叫做LDT表,是每一个进程都要有的。
GDT和LDT
操作系统层面的段地址表叫做GDT,每一个进程独有的段地址表叫做LDT,也就是我们前面讲CPU管理时的映射表.
所以在进程创建时,将程序分段载入内存,并将每一个段的基址存放在PCB中的LDT表,并通过这个表进行寻址。
承上启下:
前面我们介绍了操作系统使用内存的原理。还介绍了程序的分段机制,通过段基址和偏移获取物理地址。
下面我们接着进行介绍:在经过编译后程序被分为多个段,但是要写入内存还要在内存空间中找到一个空闲的区域。如何去找呢?这就是我们下面的内容。
内存分区与分页
内存分区
操作系统初始化时将内存进行分区,采取的分区策略是可变分区。在实际中,通过一些核心数据结构来管理可变分区。

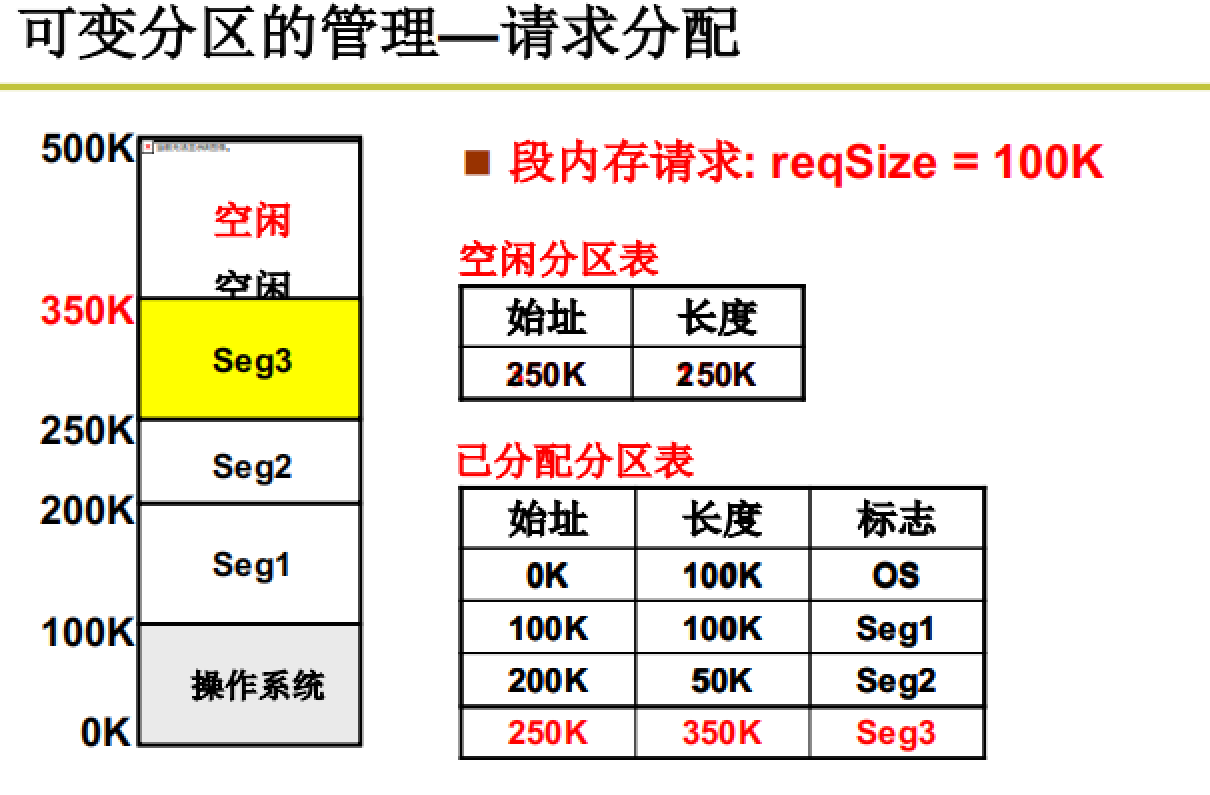
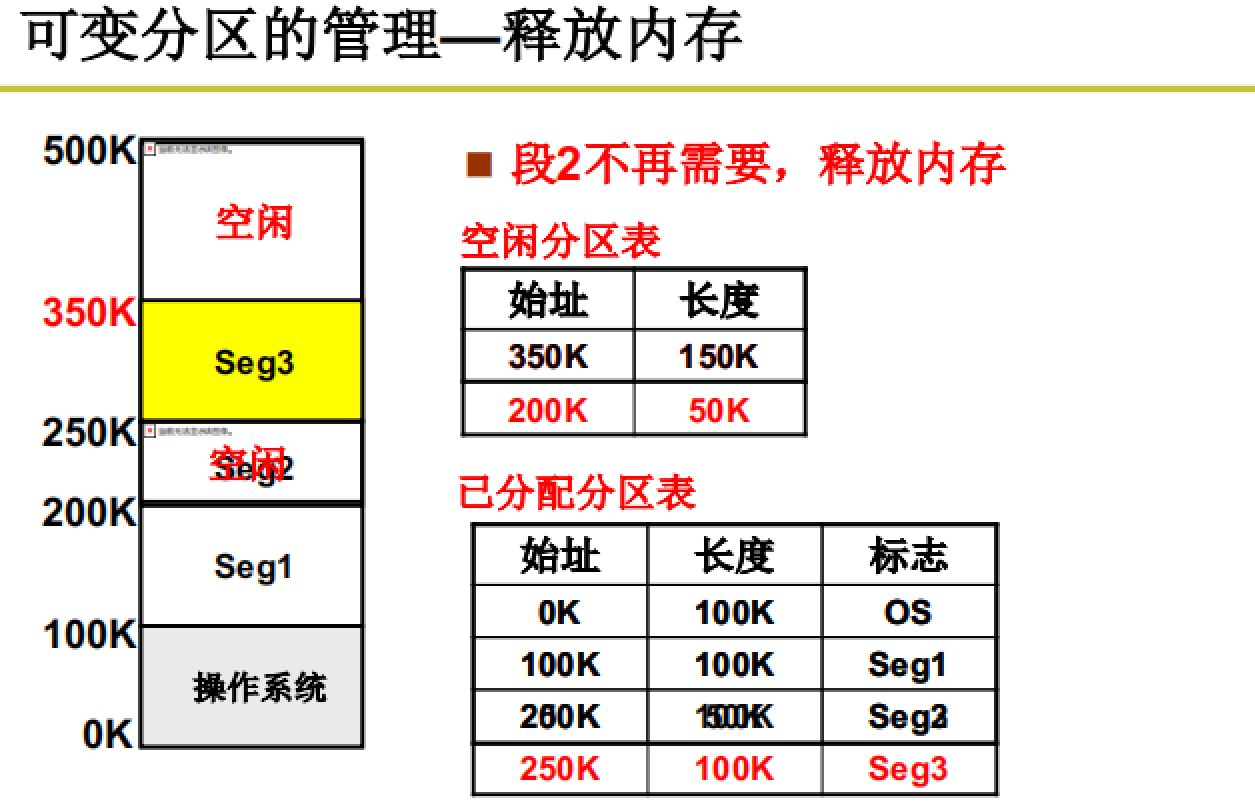
通过空闲分区表和已分配分区表来记录内存区域信息。
通过一些算法来适配区域申请。
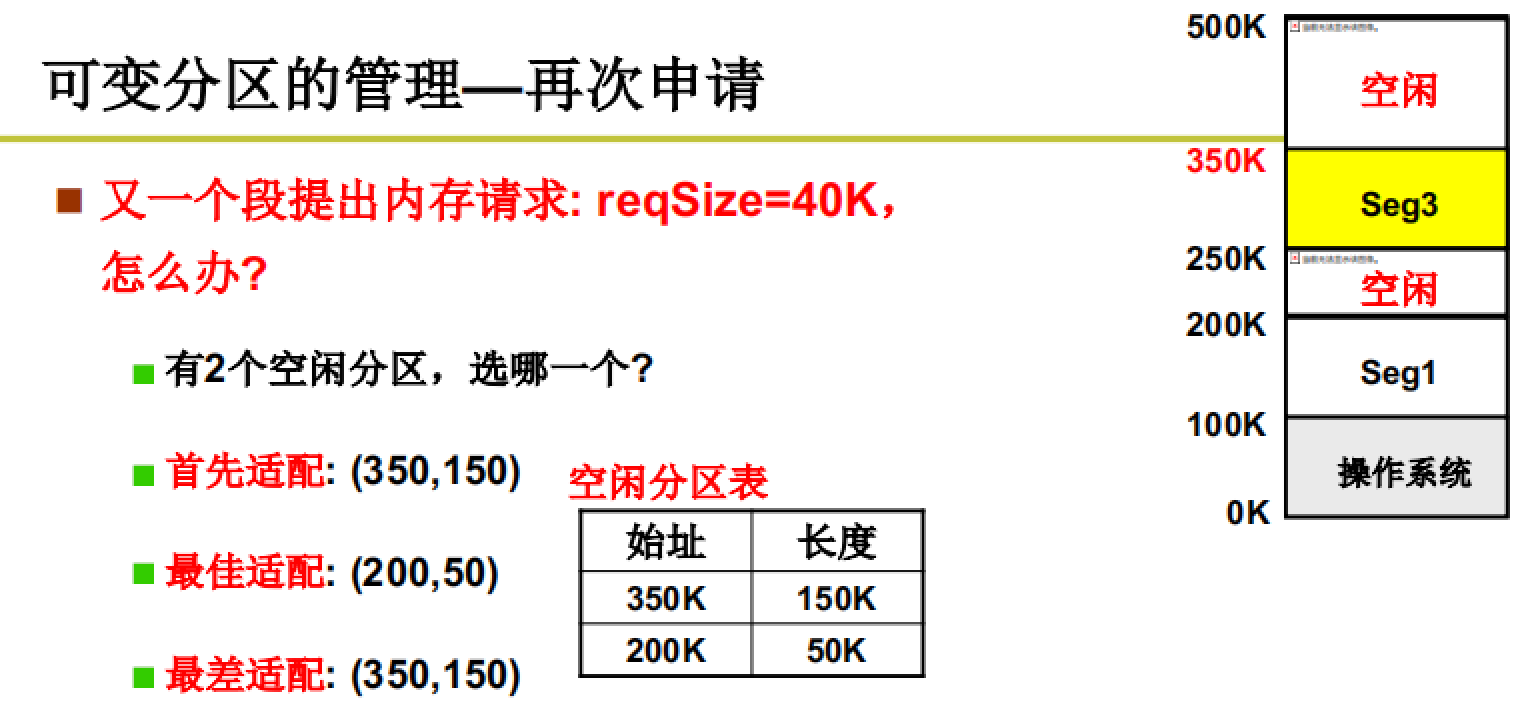
不同的适配算法都有各自的优缺点,比如:首先适配的复杂度较低,而最佳适配的复杂度高且分割后剩余的区域较小等,但是他们没有对错,都是对的,只是要根据具体情况来进行选择。(操作系统中的很多算法都无对错之分)
例如下面这个例子:

承上启下:
上文我们介绍了操作系统对于内存的分区处理以及适配算法。
但是内存的分区机制导致内存效率较低,所以我们引入分页机制来解决这个问题。
注:分页机制是对于物理内存来说的,而分区机制是对于虚拟内存来说的,二者各有用处,而将段页合并是下一节的基本内容。
内存分页(物理内存)
可变分区的问题:
内存碎片
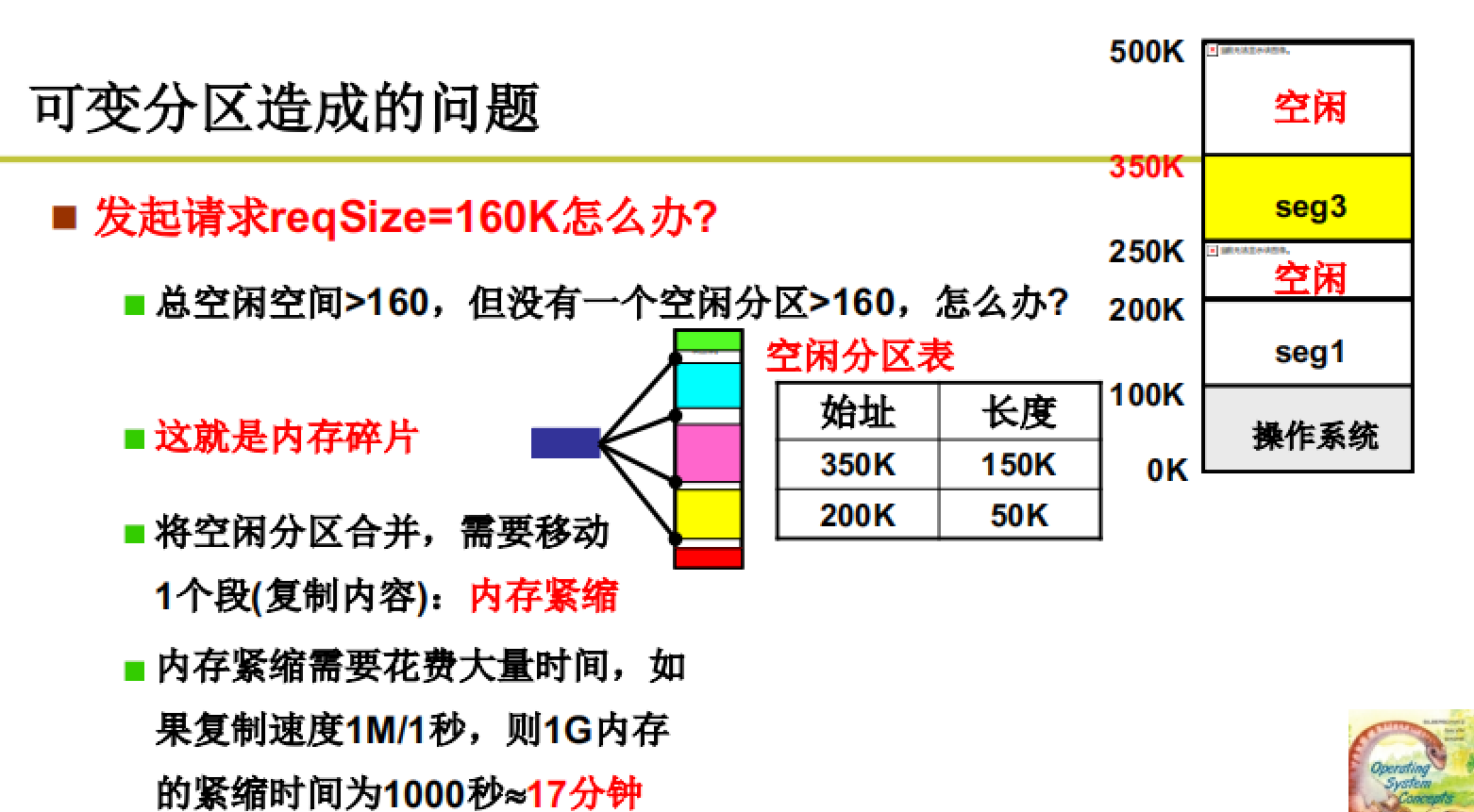
由于采取可变分区机制以及多次的段请求,导致内存中的碎片区域越来越多,最终导致即使剩余的空闲区域大于申请区域也无法完成分配,因为申请的空间必须是连续的。
为了解决这个问题,引入内存紧缩的概念,即将已分配区域连接在一起,将碎片区域合并。但是这种方法也无法从根本上解决问题,因为内存紧缩对资源的消耗很大,往往在紧缩过程中涉及到的进程无法执行,表现用户眼里就是死机。
问题的解决:
申请区域离散
既然无法将碎片合并,那就将申请的区域打散为多个基本单元,并在内存中取这些内存单元去分配,这就是内存的分页机制。

将内存平均分割为多个基本单元,也就是页,一般将4k大小区域为一个页。这种方法可以很好解决碎片区域问题,因为即便是这些碎片区域也是由页构成。
页已经载入内存,接下来就要进行寻址
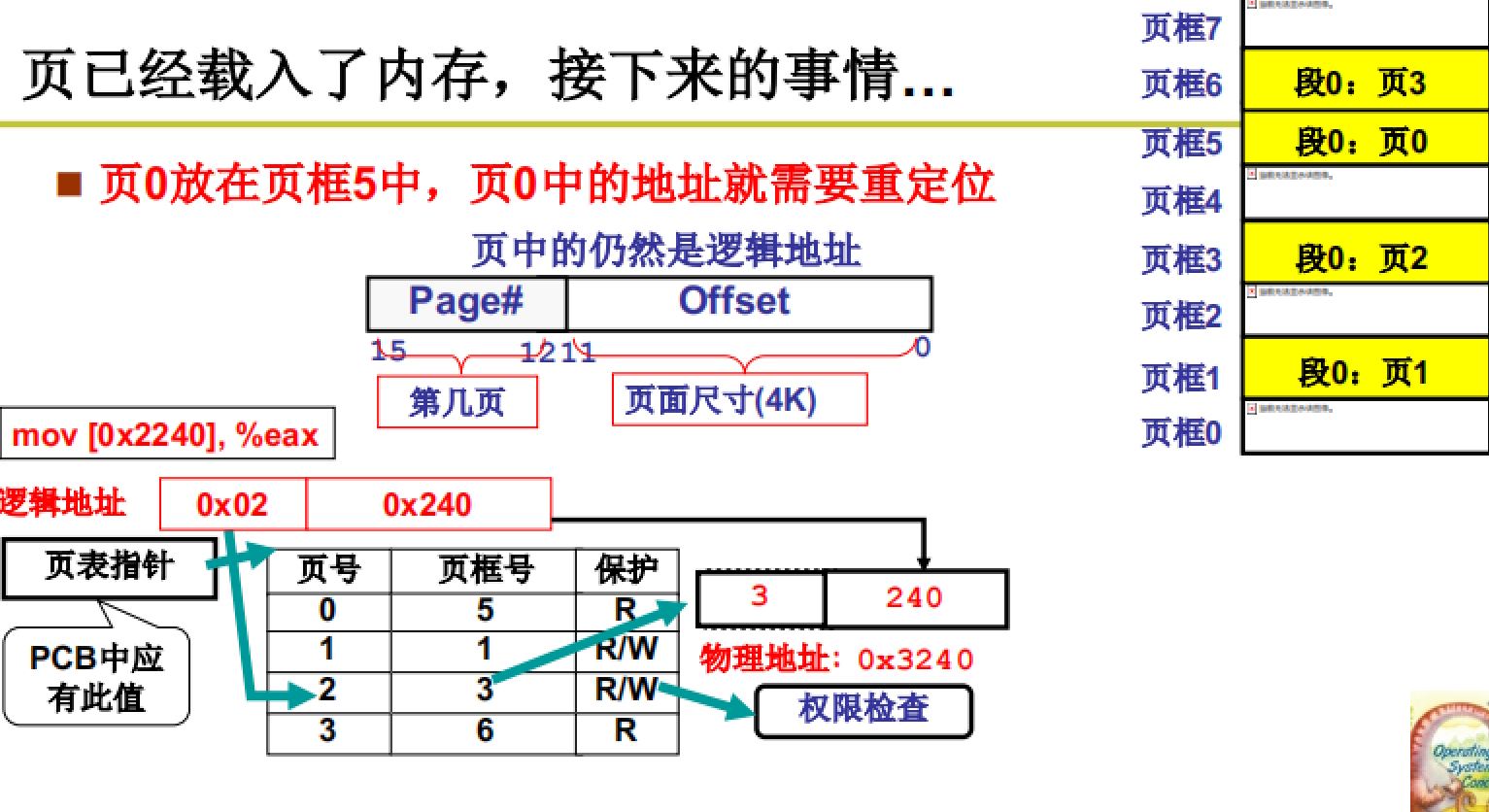
如图所示,通过页表对地址进行重定位。页表中存储着页号以及其对应的页框号。
在重定位的过程中,地址除以4k也就是右移12位即可得到页号,而后查询页表获取页框号最终得到物理地址。
页表与PCB关联且通过MMU自动进行运算。
承上启下:
前面介绍了内存的
分页机制,可以有效解决内存碎片的问题。
但是分页机制也有弊端:对于现在以GB为单位的内存空间来说,以4k为基本单元进行划分,所得到的页表就会很大。而下面要介绍的多级页表和快表就是在面对大页表问题是提出的解决方法。多级页表和块表加上前面讲到的内容就可以构成一个可以较为高效工作的分页机制。
多级页表和快表
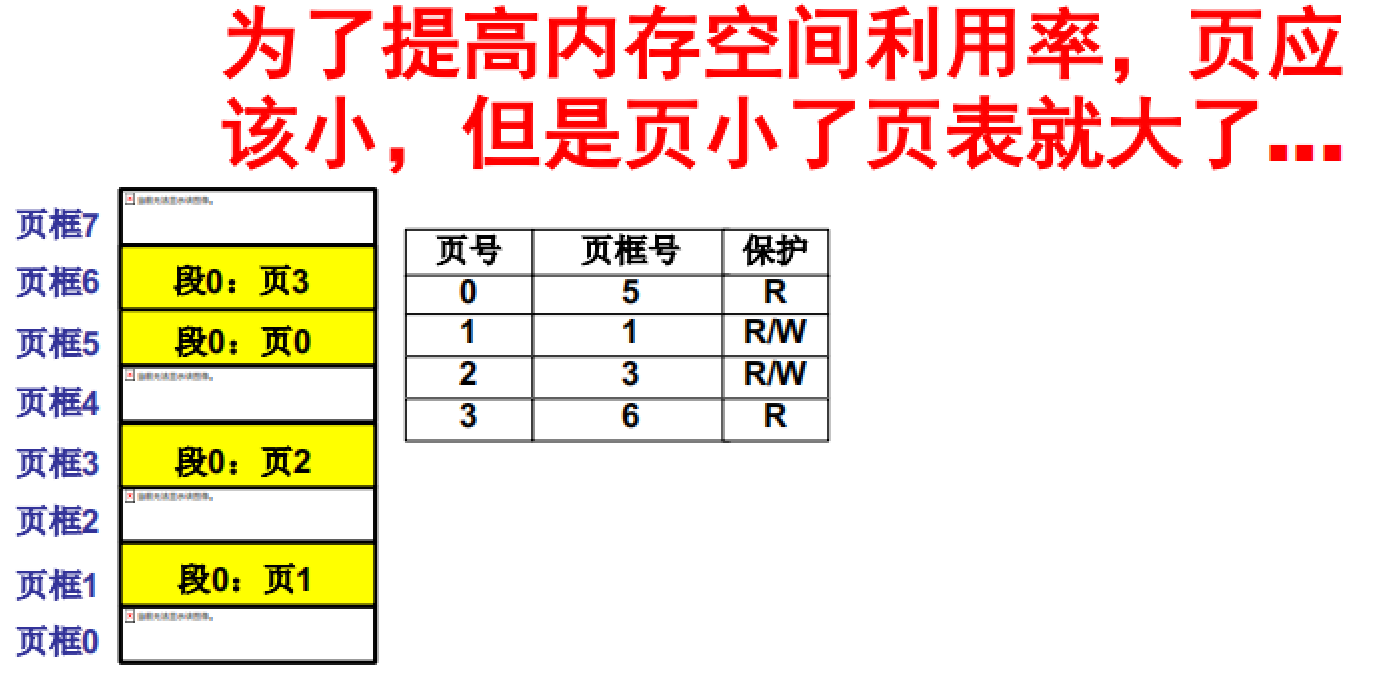
如图所示,页小空间大导致页表太大。 具体有多大呢?看下面的例子。
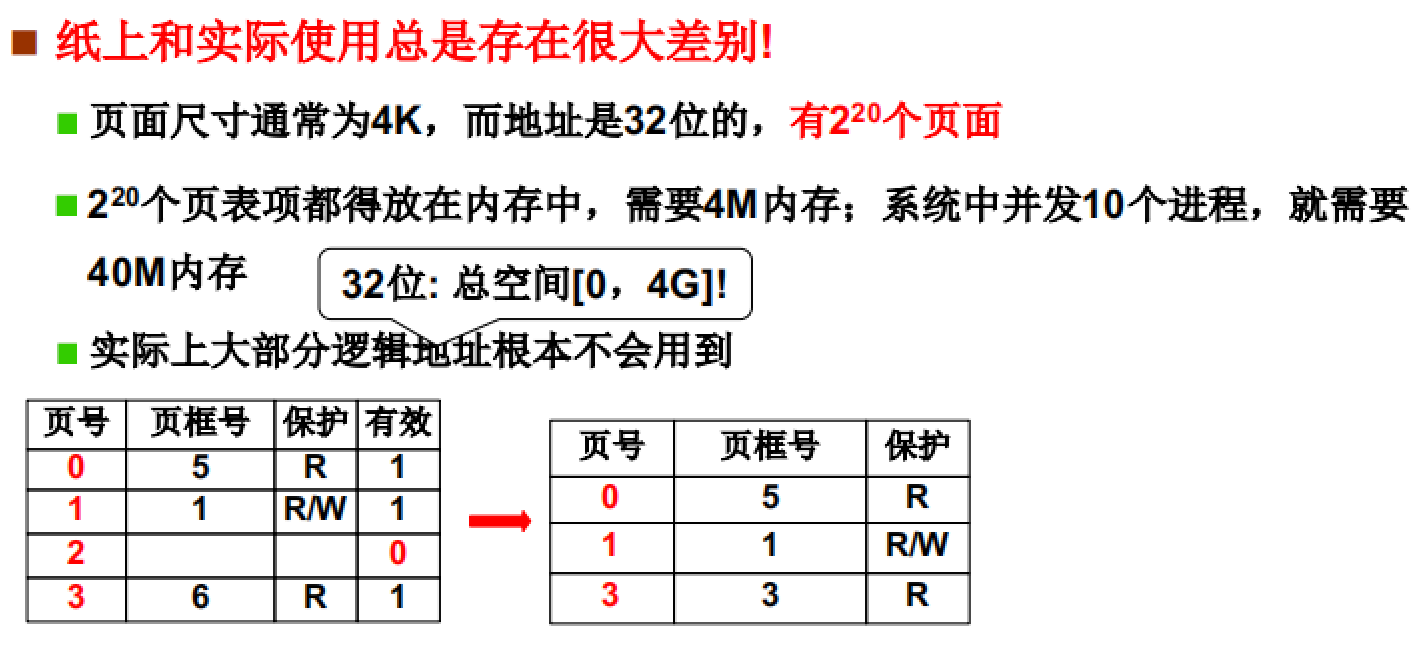
如图所示,每一个进程都要有对应的页表。根据32位地址和4k单元计算,一个页表的含有2^20个页表项,也就是4M(一个页表项大小为4B)。
如果运行多个进程,单单是页表存储空间就要占据很大一部分,造成空间的极大浪费。
但是在实际情况下,很多逻辑地址都是使用不到的。因为一般程序的代码段、数据段等都不会太大,很难达到4G的上限.
那么该如何进行改进呢?
第一种尝试:只存放用到的页

如图所示,我们将页表中不使用的页表项删除,得到一个较小的页表。但是尽管这种方法可以减少页表对于内存的浪费,却会造成程序执行的速度大幅度降低。
为什么会降低呢?因我们需要根据页号查询页框号以获取物理地址,这时如果页表中的页号不连续,就要依次对这些内存进行比较,而多次的内存访问会降低速度。
所以得出结论:第一种尝试失败,必须保证页表中页号的连续,这样只需要一次即可获取到页框号。
那么怎么样可以即连续有占用内存少呢?
多级页表就可以。这也是我们的第二种尝试。
多级页表
多级页表可以用书的
章目录和节目录来类别思考。
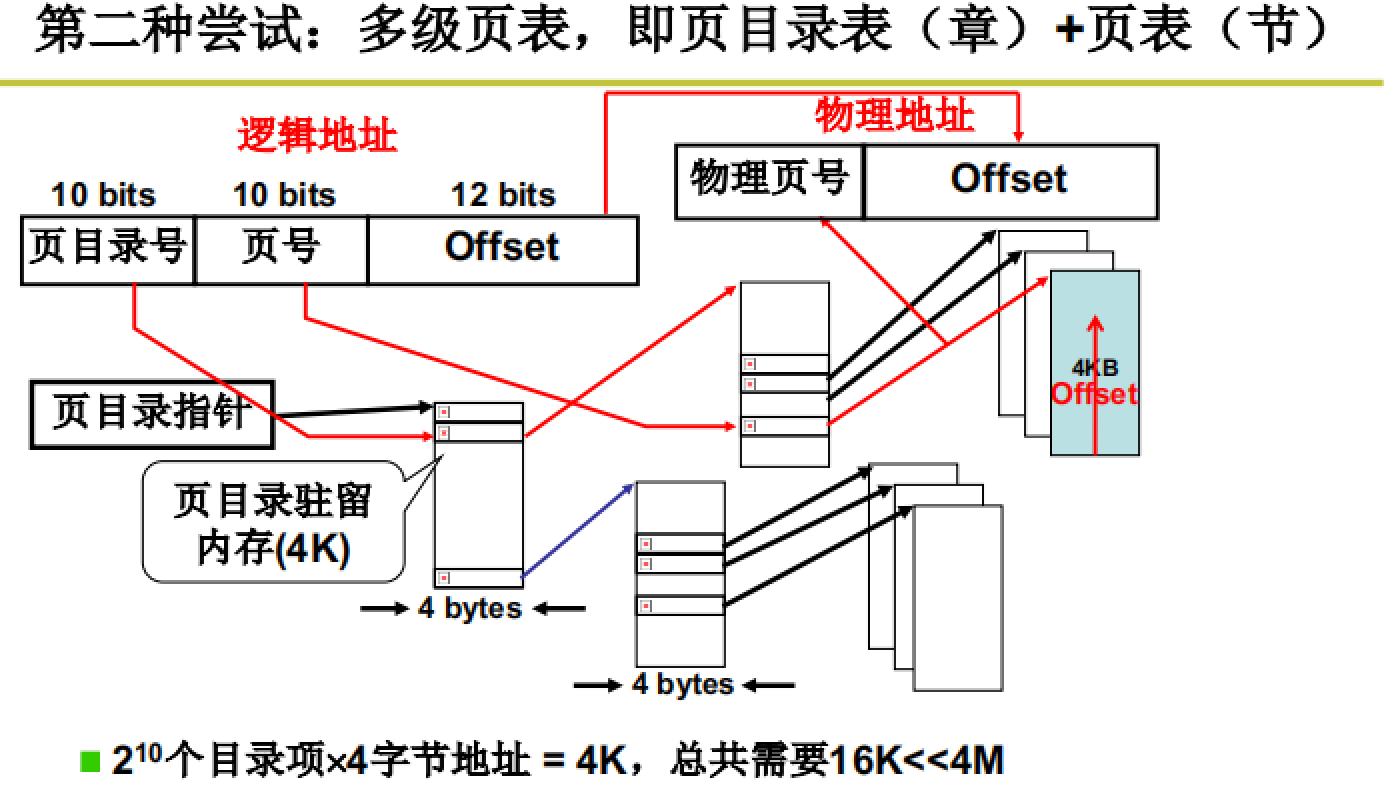
如图所示,32位地址分为页目录号、页号、偏移三部分,通过页目录号找到目标区域、通过页号在此区域得到正确的页框号,最终与偏移一起得到物理地址。
这种方法既可以保证页表的大小,又可以保证查询的速度。xxxxxxxx xxxxxxxxxxxx
承上启下:
又有问题:多级页表的多次跳转,会造成访问次数的增加,时间效率会变低。当然即便如此也要比前面提到的不连续存储要快很多。
为了解决这个问题:引入快表。
快表
也可以类比我们看书,当目录很多很复杂时,我们可以记住某个章节的页数,下次直接查看即可。

如图所示,使用TLB寄存器保存一些常用的地址页数,并借助硬件实现一步得出查询结果(多个数据一起比较)。
TLB的实现与优化


如图所示,通过设置合适的TLB条目数以保证其命中率。
承上启下:
前面我们介绍了内存的分页机制和分段机制,二者各有优缺点。
下面我们要介绍的就是如何将这两种机制结合,取其精华用于实际的内存管理。
段、页结合的实际内存管理机制
程序员希望用段(便于管理),物理内存希望用页(保证内存的空间使用效率)
段、页如何结合
段页结合的中转点:
虚拟内存
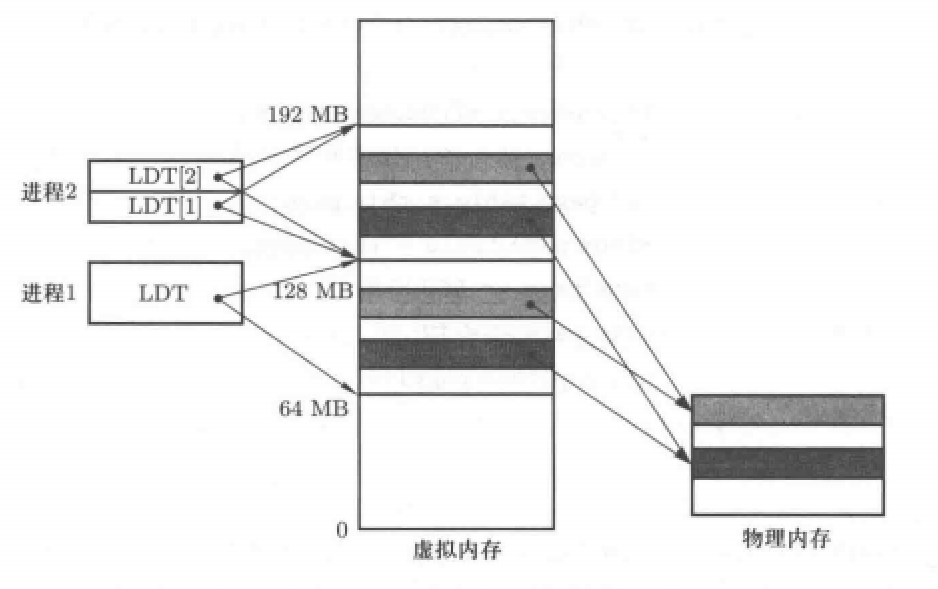
如图所示,通过虚拟内存作为中转,实现段页的结合。
段面向用户、页面向硬件:将程序放到内存
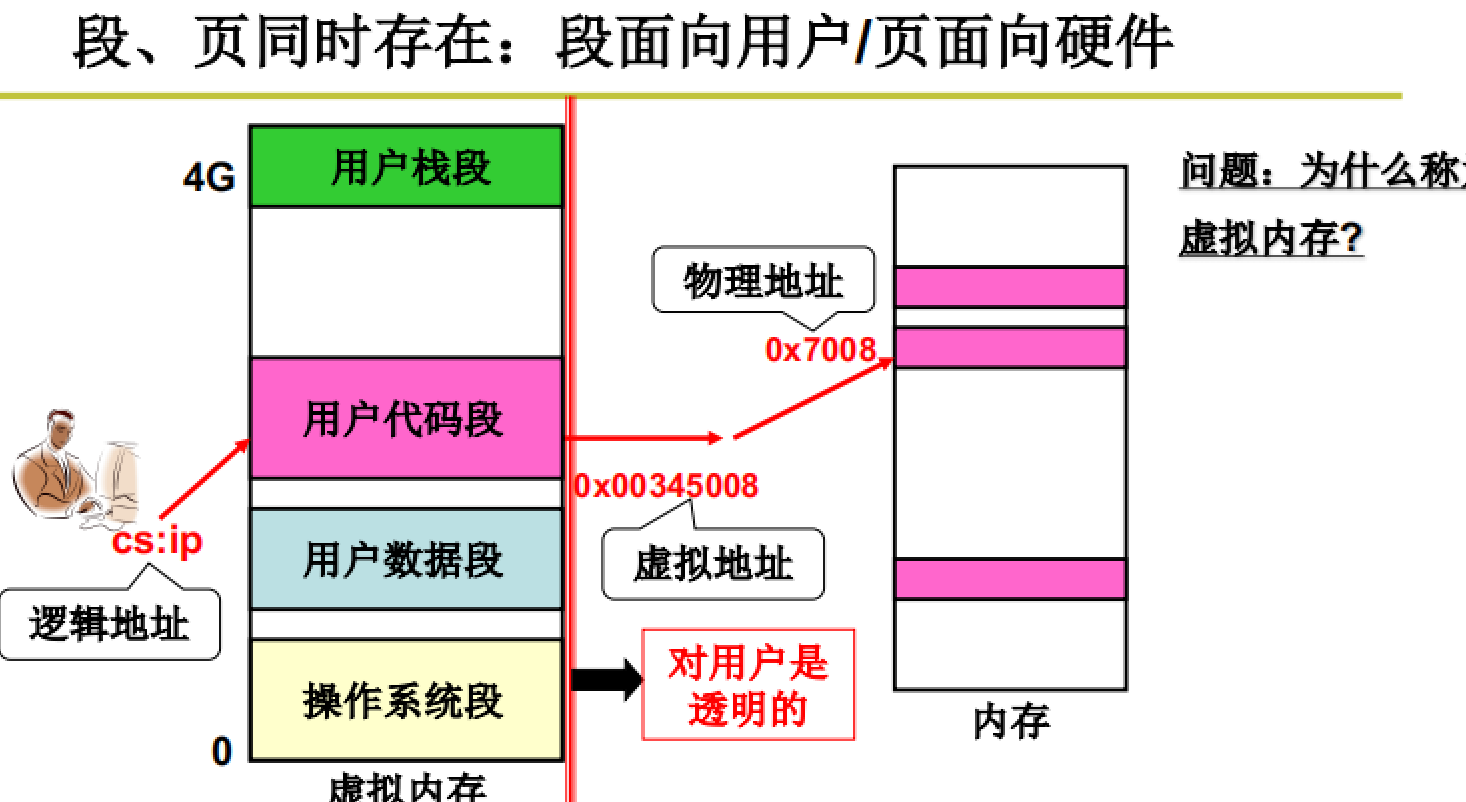
如图所示,使用虚拟内存进行段划分并面向用户使用;而后将虚拟内存中的各个区域映射到物理地址的各个页上。
段页同时存在的重定位操作:保证程序的正确执行
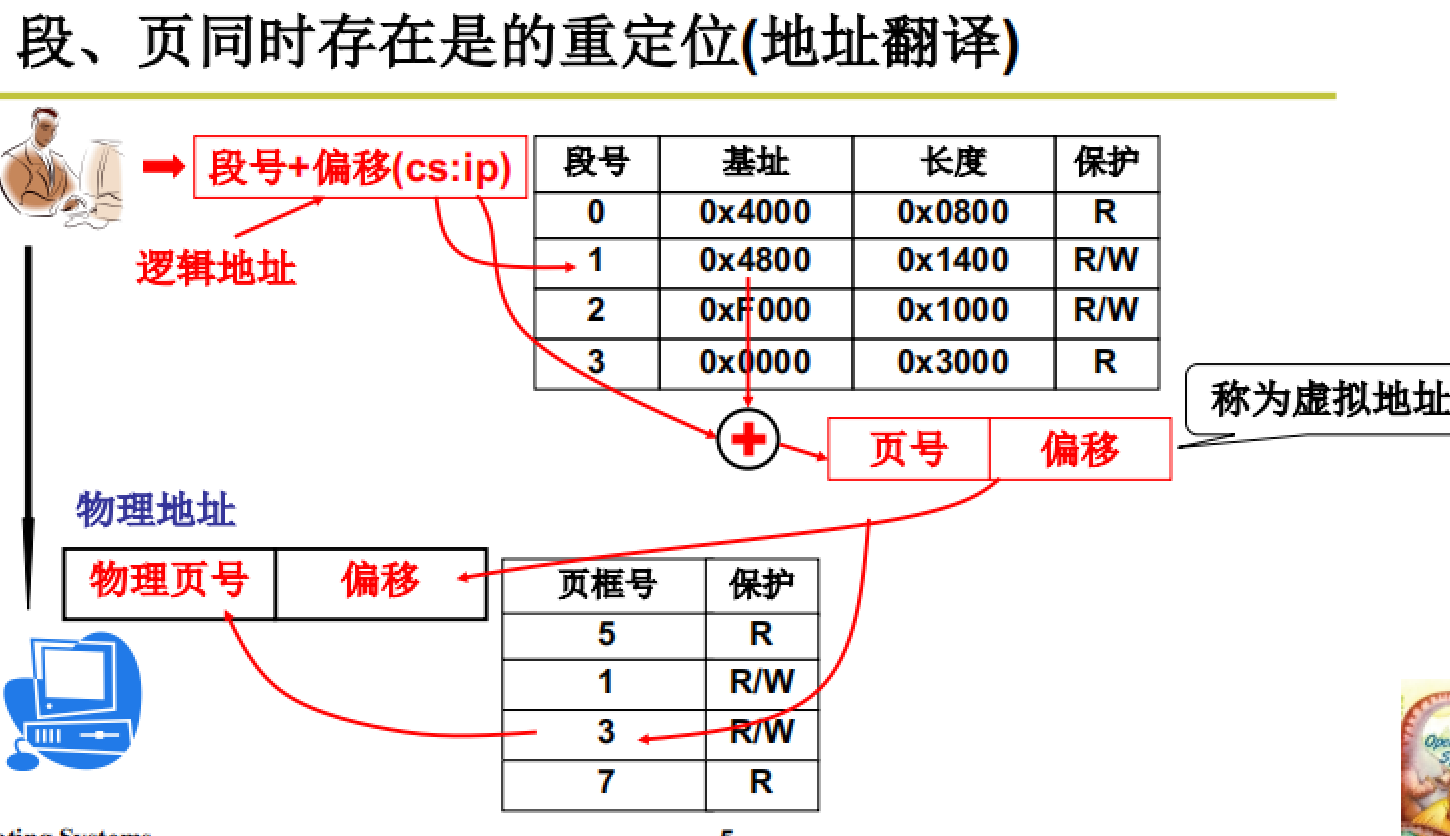
如图所示,重定位操作的大体流程:通过查询段表将逻辑地址转换为虚拟地址;而后通过页表将虚拟地址转换为实际物理地址。
内存管理的流程
流程框架建立:
先通过拓扑建立内存管理的流程,包括:程序载入和程序执行(地址翻译),而后通过代码进行实现。

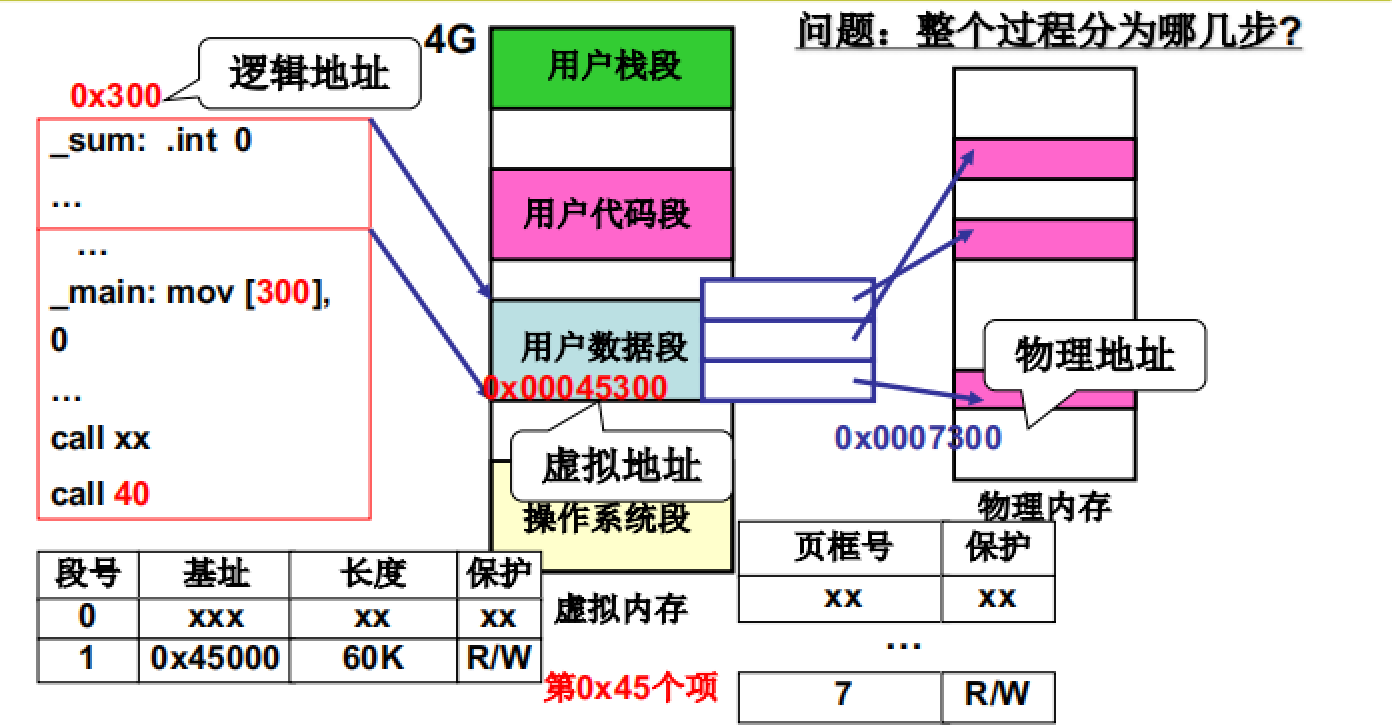
如图所示,内存管理的流程:
- 先对虚拟地址进行分区操作,而后通过适配算法得到空闲区域分配给进程
- 建立段表(LDT)完成虚拟内存与程序段之间的映射
- 将虚拟内存中的各个分区均分成多个页,并与物理内存中的空闲页框绑定。
- 建立页表来记录虚拟内存页和物理内存页框之间的映射关系
- 前面4步已经完成了程序的载入,这一步要完成程序的执行。
在介绍代码实现之前,我们先来看一下如何执行载入内存中的程序
要想执行程序,就只需要将程序放到CPU中即可,这一点在CPU管理时已经讲过。所以,这里我们提到程序执行更加需要关注的是:地址翻译。(代码中涉及到地址的地方都要进行地址翻译才可以得到实际物理地址,也只有物理地址才可以被实际操作)
在段页结合的内存管理机制下,地址翻译也就是重定位需要分两步进行:
- 首先完成
逻辑地址到虚拟地址的转换。这个例子中逻辑地址为:CS:40,通过查询LDT表获取到代码段的基址,而后与偏移相加得到虚拟地址。 - 将
虚拟地址与物理地址进行转换。虚拟地址已经知道,将其除以页大小即可得到页号,而后查询页表即可得到页框号,将其与偏移加和得到实际物理地址。
注:在实际的计算机中,我们只需要给LDTR和CR3寄存器分别赋值为LDT表初始地址和页表初始地址,MMU就会在遇到地址时自动完成地址翻译。
内存管理的代码实现
具体代码实现:从fork()开始
这里主要关注与内存管理相关的代码,其他有关CPU管理的部分不涉及。

上图所示代码就是fork()创建进程时的核心函数,通过copy_process()完成PCB的创建、内核栈的分配和初始化、内核栈与PCB的关联等。同时,通过copy_mem()完成进程空间的分配。
我们来分析一下代码,主要是copy_mem()函数:
先来看一下这个copy_mem函数的具体代码:
代码部分1:虚存分割与段表建立

分析上图代码:先定义一个变量、而后为这个变量赋值、之后通过set_base()函数为LDT表写入内容。所以不难看出,这个函数就是为了申请段空间而后建立段表。
代码中nr指的是进程号,即为每一个进程分配64M大小空间,并根据进程号依次分配。分配后可以得到如下图的虚拟内存视图:
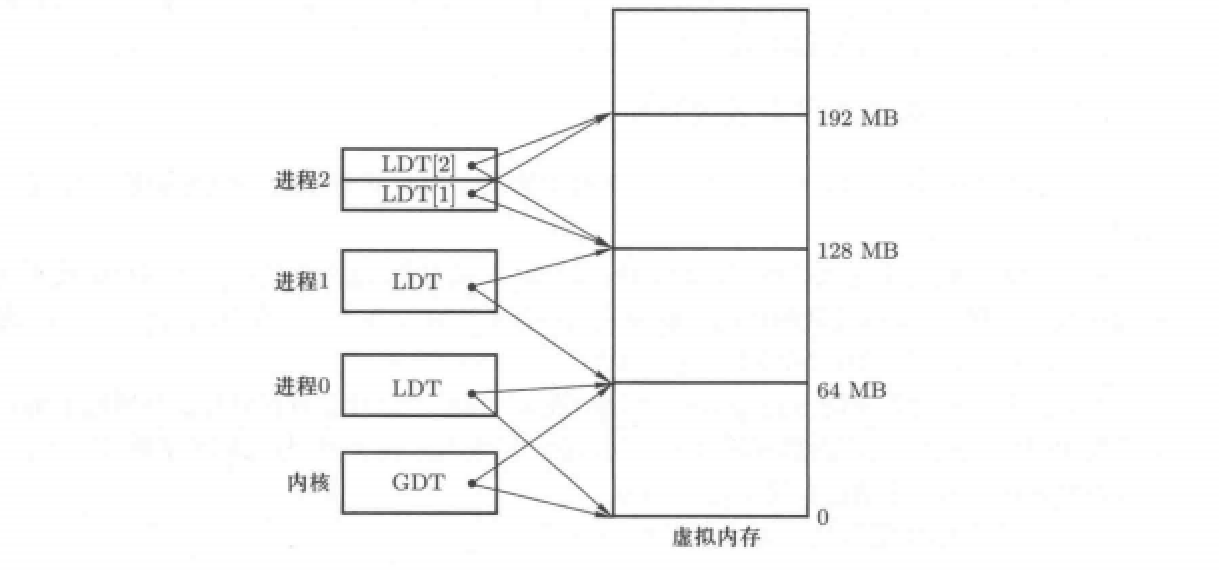
当然,上图所示是最简单的虚拟内存分割方法,在实际中往往采取很多算法进行内存分配,不过这不是我们现在要考虑的,我们只需要知道此函数完成了虚拟内存的分配与段表的建立。
代码部分2:内存分页与页表映射
先来看一下代码:

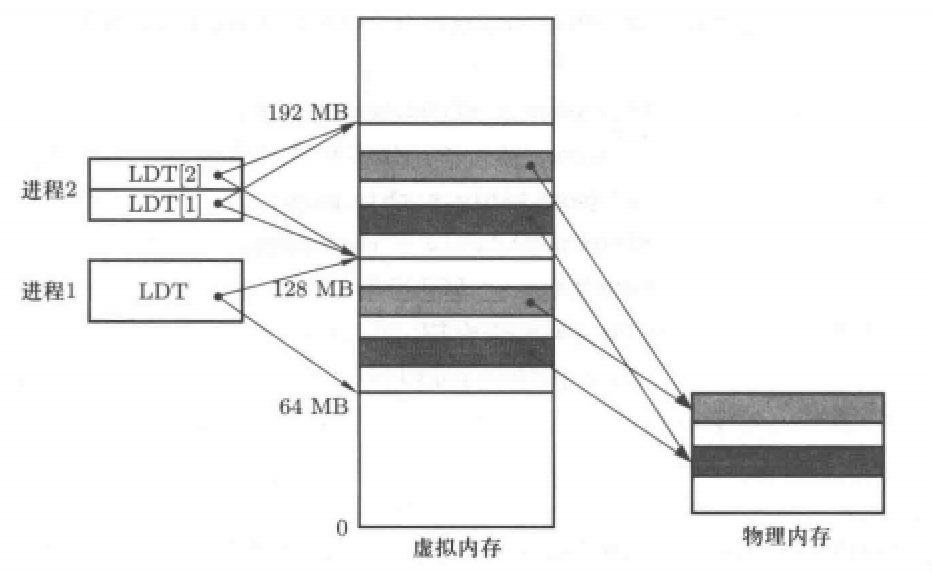
通过代码不难看出为什么这个函数叫做copy_mem(),因为子进程创建时其内存空间是复制父进程的。代码中的get_base(current->led[2])就是为了获取父进程虚存空间与内存页框的映射关系,而后通过copy_page_tables()函数将其复制给new_data_base也就是子进程的页表。
至于如何复制的,这个过程也很简单,有代码如下:

上图代码将父进程页表复制给子进程,主要通过两个for循环实现,外层循环实现页目录的复制、内层循环实现页表项的复制。
具体的流程如下:
- 先获取父进程页目录表的基址。(在操作系统启动时
head.s中有初始化页目录表的代码,其中将页目录表放在内存的0地址处) - 而后要获取页目录号。这一点是通过查询父进程的ldt表获得的,ldt表中存储着32位地址,其中前10位为页目录号,所以代码中使用
from>>20x4得到所需页目录在页目录表的位置,并将其复制给子进程。 - 通过页目录表中存储的地址也就是页表基址与页号即可获取物理内存的页框号,将其填写到子进程页表项中即可。
经过上述过程即可完成子进程内存空间的分配,得到以下内存视图:
代码部分3:父子进程程序的执行
上述代码实现了子进程内存空间的分配与LDT表和页目录、页表的建立。下面我们就要在此基础上执行代码:
我们以
*p= 7为例
假设p的逻辑地址为300h,要完成上述代码,需要以下两步:
- 首先根据逻辑地址完成地址翻译。具体为:查询LDT[2]获取到数据段基址,假设为0x1000000,所以可以得到虚拟地址为0x100300;然后根据这个虚拟地址获取物理地址,具体为:通过前10位得到页目录号,通过中间10位得到页号,通过偏移得到物理地址,当然这个过程
由MMU自动执行获取。 - 获取到物理地址后,即可由数据总线将7发送到此地址处,完成程序.
我们在上述代码基础上继续执行:
父子进程都要执行prinf(p)
程序执行的流程:根据p的逻辑地址翻译后得到物理地址,而后通过地址总线和数据总线完成数据传输,最后进行打印,并且打印的结果都是7.
为什么打印的结果一样呢?因为父子进程定位到的物理地址是一样的,本质还是我们上面介绍的代码实现:通过复制的方式实现子进程内存空间的分配。
继续扩展:
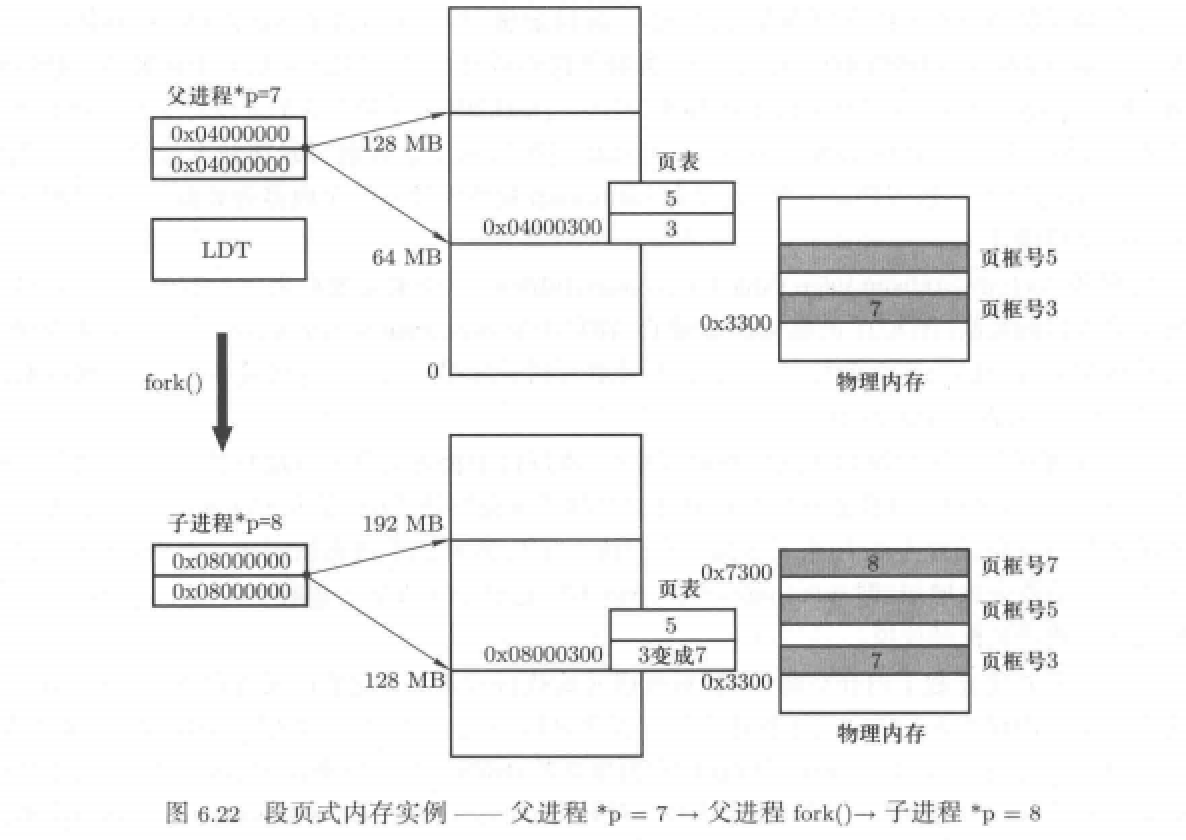
子进程执行*p=8,而后print(p)
这一步有所不同,当然程序执行流程还是那样:先通过p获取到其物理地址,这一步和上一个代码一样,但是在获取后不会直接进行赋值。因为子进程对p的物理页框的权限为只读,所以无法进行赋值。这时就会出现异常中断,此中断会为子进程分配一个新的内存页框并修改页表完成映射。这样程序就会将8赋值为这个新的页框了。
程序执行的内存视图如下:
写在最后
总结:这一篇博客完成了操作系统中内存管理的学习。通过回顾整理的内容,发现内存管理部分就两个部分:
内存空间的分配、内存中程序的执行。其中内存空间的分配为了兼顾用户和计算机需求,采取段页结合的机制,通过虚拟内存作为中转实现逻辑地址和物理地址的转换。而程序执行的关键在于地址翻译也就是重定位,这一步是由MMU自动实现的,但是具体到底层还是LDT表和页目录、页表的查询,因此理解这两个表尤为重要。
下一步计划:进行磁盘、文件系统的学习,如何将磁盘文件放到内存中;同时完成内存管理的实验,通过实际修改代码实现对内存管理的深入理解。



