(第四节)操作系统--多进程之线程切换(3部分)
写在最前面:
前面讲到,计算机在执行一个进程时,可能会涉及到IP操作等导致该指令无法继续执行,而是会切换到其他进程。关于多进程之间的切换是本篇文章的核心内容。
进程=资源+指令执行序列。其中资源对应着内存,也就是映射表。
在进行进程切换时需要对资源和指令序列同时进行切换,这个过程很复杂。所以,可以将资源和指令执行分开,即一个资源+多个指令执行序列构成一个进程,这样在切换是只需要进程pc的切换即可。
线程:保留了并发的优点,避免了进程切换代价。
所以:本篇文章内容主要是
以线程之间的切换也就是指令序列的切换为主,这样做可以让我们摒弃资源切换的复杂步骤,更加清晰的把握多进程切换的核心要点。
当然,资源的切换也会进行介绍,不过要放到后面内存管理部分。
线程的介绍及其价值
什么是线程
线程(英语:thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
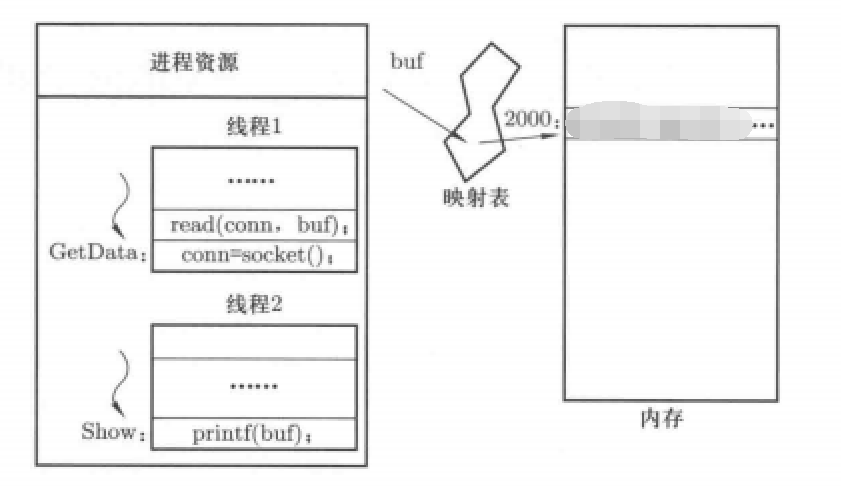
如图所示,同一个进程中有多个线程,其共享资源,可以进行切换执行。
线程与进程的对比(不同)?

上表详细比较了线程与进程的区别。
如何选择使用线程还是进程呢?
很简单,判断需要完成的任务是否需要独立的资源空间。如下面这个例子:

这一题的答案是C。对于需要存放账号、密码等安全性较高的任务需要开辟单独的存储空间,也就要使用进程。
一个多线程的例子
线程的切换不仅仅可以帮助我们理解进程切换的本质,线程本身也很有价值。
线程本身是否有用呢?我们用一个例子来看一下。
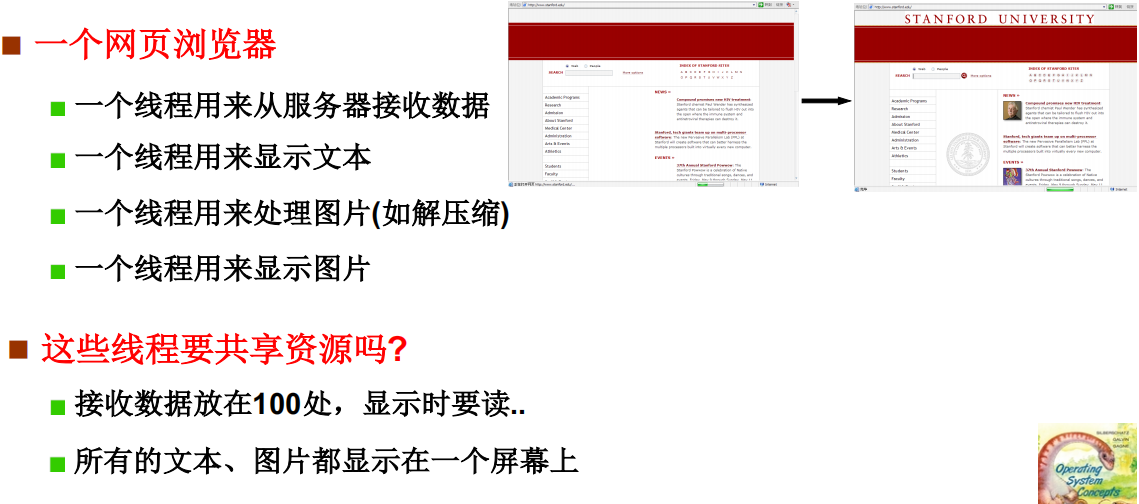
一个浏览器网页需要很多线程配合实现功能:文件下载、文本显示、图片显示等功能不是顺序执行的,而是交替执行的。从而可以实现右侧示例的功能。
同时一个网页的多个线程可以共享资源,因为本身就是为了此网页的显示,共享资源不会导致安全问题。
如果将这几个线程隔离还可能会导致内存的浪费和代码执行效率的降低。
下图给出了这个多进程浏览器的代码轮廓:

用户级线程
用户级线程是指
由用户程序自己管理的线程,该线程对操作系统透明,即操作系统完全不知道这些线程的存在。
前面我们介绍了一个多线程浏览器的示例,其中给出了线程切换的流程。主要涉及到:yeild()和create()这两个核心函数,一个进行切换,一个进行创建。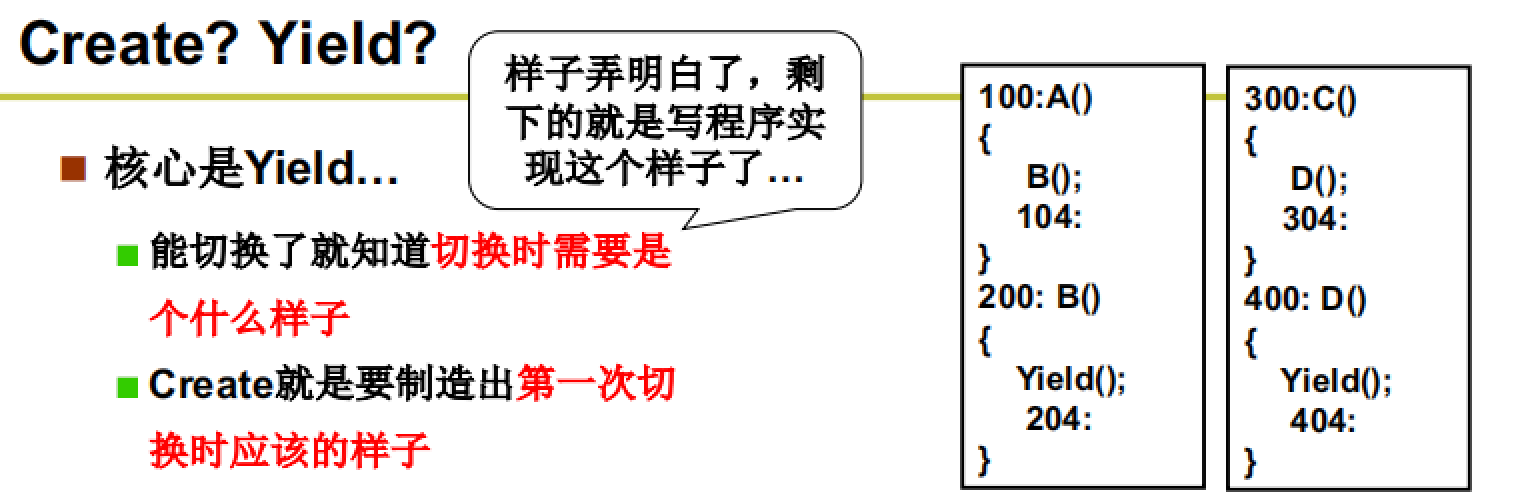
用户级线程的切换
Yield()是完成线程切换的核心函数。下面我们以一个实际的例子来一步步分析这个函数的实现与其中的注意事项。
第一步:两个执行序列和一个栈

如图所示,函数A和B属于线程1,函数C和D属于线程2。两个线程中的所有函数共用一个栈。
我们先来分析一下上述程序的执行流程:
- 首先执行
函数A,其中调用了函数B,所以先将104压栈之后跳转到B函数位置; - 然后执行
B函数,此函数需要调用Yield()进行线程切换,不过在此之前要先将204压栈,然后跳转到函数C; - 之后执行
函数C,其调用了函数D,所以先将304压栈而后跳转到函数D; - 再之后执行
函数D,此函数也是调用了Yeild()进行线程切换,所以先将404压栈,而后跳转到204位置。
到这里,继续执行就会出现问题:当执行完毕204代码后需要返回,按照正常的流程来看,B函数执行完就要返回A函数了,但是这里却是返回了D函数的404位置。
原因很简单:因为两个线程共享一个栈,导致返回地址在栈中出现混乱。
解决方法:不同线程使用不同的栈空间。
第二步:从一个栈到两个栈

如上图所示,线程1和2使用不同栈,并使用TCB这个全局的数据结构进行信息存储,类似于进程中的PCB。
先不要看上图中的红字,我们来分析一下函数的执行流程:
- 前面的步骤与第一步一致,直到函数D执行Yield()进行线程切换。
- 会先进行栈的切换,而后跳转到204位置。
- 之后执行204位置代码,执行完毕后返回。
又出现问题了:本来按照程序的执行流程,在执行完毕B函数后需要返回函数A。在第一步中由于栈的共享导致返回了404位置,这里使用不同栈进行处理,结果却导致再次返回204位置。
原因很简单:在B函数调用Yield()时会先将204压栈存储,所以会导致重复执行。
解决方法:去除Yield()函数中的jmp指令,只进行栈的切换。
到这里,线程之间的切换也就是yield()函数也就介绍完毕了,我们做出以下总结:
- 用户级线程的切换就是在切换位置上
调用Yield()函数。 Yield()函数完成的基本工作就是找到下一个线程的TCB,然后根据当前线程的TCB和下一个线程的TCB完成用户栈的切换。- 在切换到新的栈后通过
Yield函数的“}”来进行PC指针的切换,而不是使用jmp进行。
用户级线程的建立
Creat() 实现线程的建立:栈、TCP等数据结构的创建

如图所示,Creat()的作用:为TCB和栈申请空间并将其关联,同时在栈中压入程序的初始地址,实现第一次切换时的正确执行。

将进程切换和建立等内容组合即可实现一个完整的浏览器页面显示功能。
用户级线程与核心级线程的简单比较
前面我们介绍了的用户级线程的切换和建立,主要涉及到Yield()和Creat()两个函数。
但是,用户态线程有一个很大的缺陷,如下图所示:
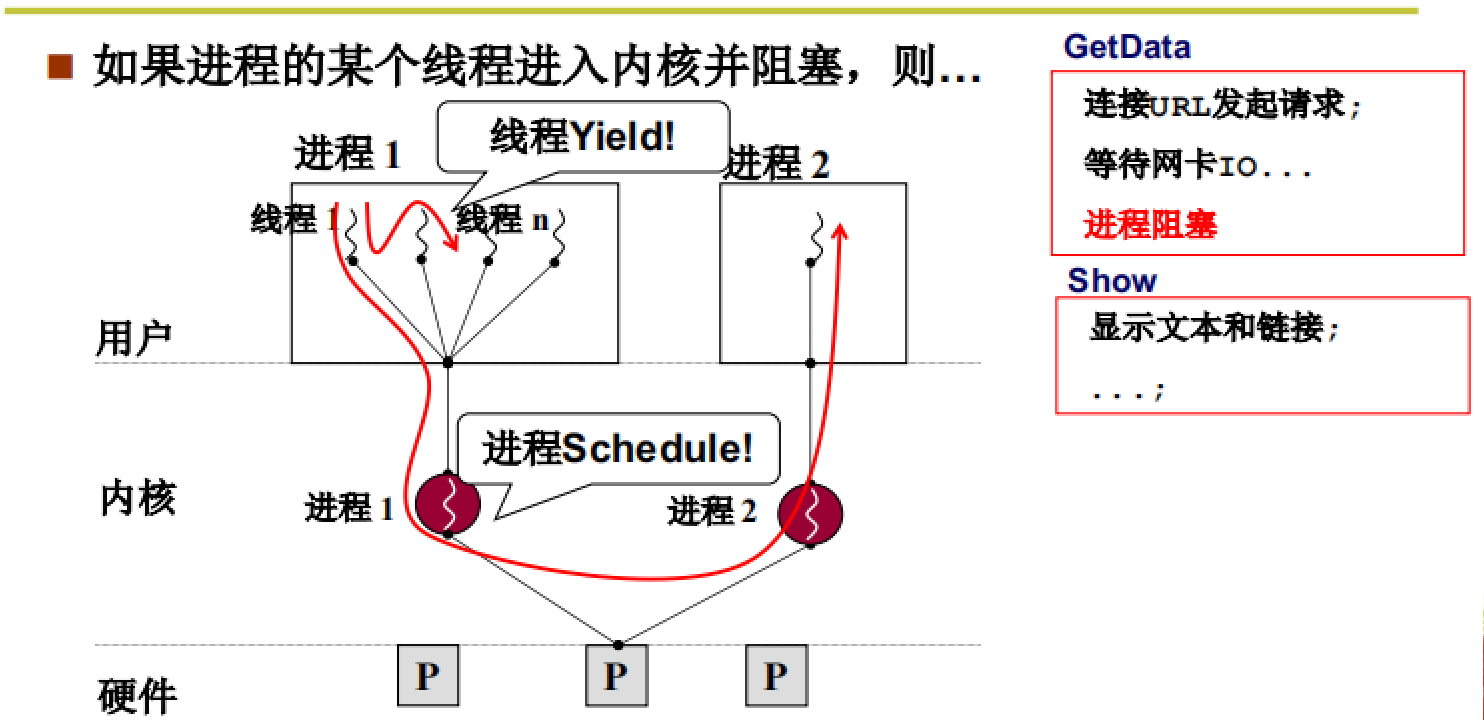
因为用户态线程对于操作系统来说是透明的,但是在线程功能的具体执行时最终还是要到硬件层次,也就是要进入操作系统内核。所以一旦某一个线程进入内核时发生阻塞,这时操作系统并不会切换到其他线程(因为操作系统并不知道用户态线程)而是会切换到其他进程,这就导致了线程并发的无效。
为了解决上述问题,就要使用核心级线程,具体如下所示:
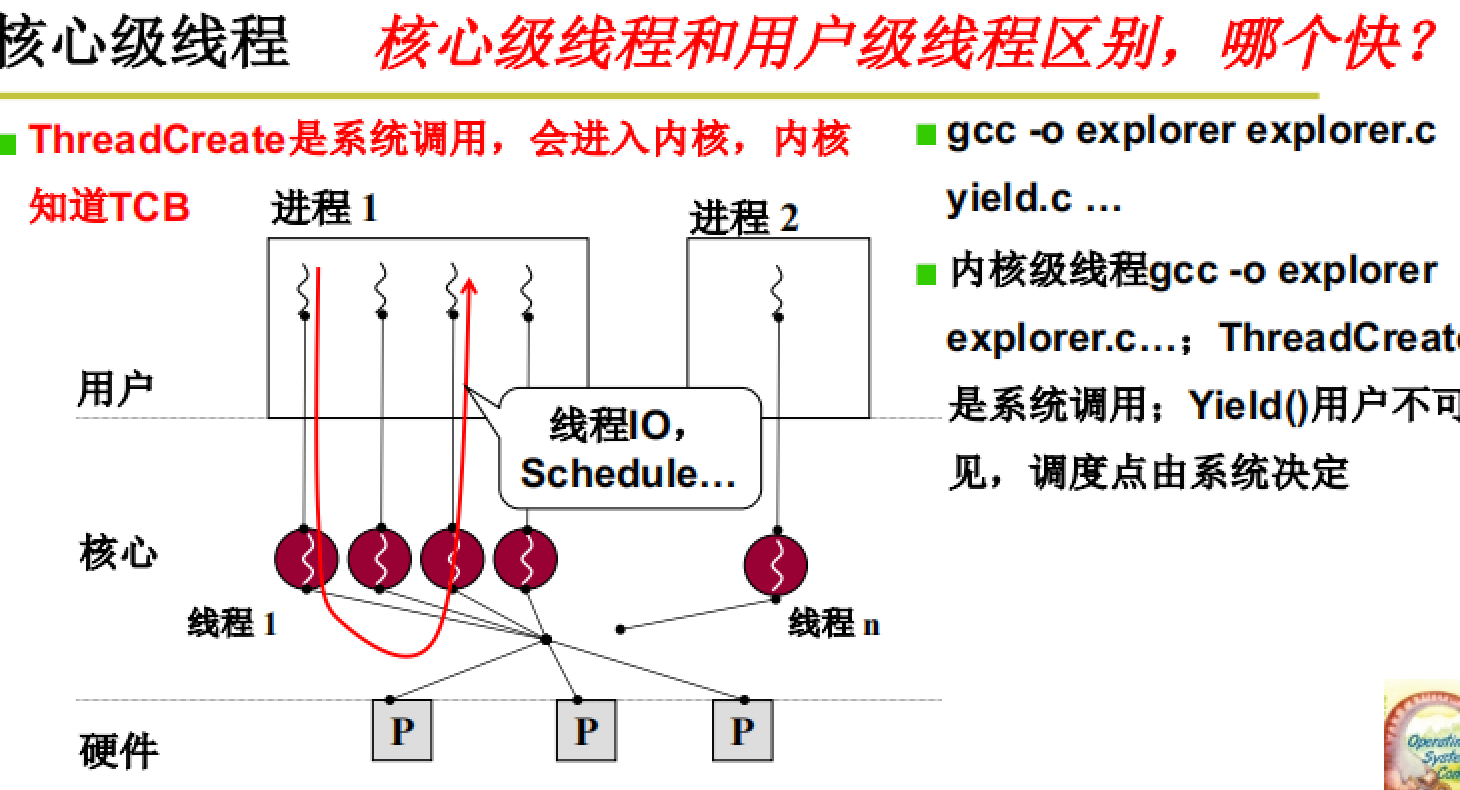
线程之间的切换不再使用Yiled()而是使用Schedule,调度点由系统决定。具体原理和实现下一步部分介绍。
内核级线程
内核级线程的引入
内核级线程的优点:适用于多核处理器结构

如图所示,内核级线程可以支持多核处理器。(多个核心,一个MMU和Cacha)
而多进程和用户级线程并不支持多核处理器。原因如下:
- 进程涉及到资源的分配,每一个进程都有其独立的内存空间,而多核处理器是共享MMU的,所以不适用于多进程。
- 用户级线程对于操作系统内核来说是透明的,也就是TCB等数据结构无法被操作系统获取,当然也就没办法切换。
核心级线程的特点:一套栈

要清楚两个概念:
- 每一个核心级线程都有对应的内核栈,线程的切换也是基于内核栈的切换;
- 切换后执行的代码仍是用户态,也就是要用到用户栈。
用户栈和内核栈的管联
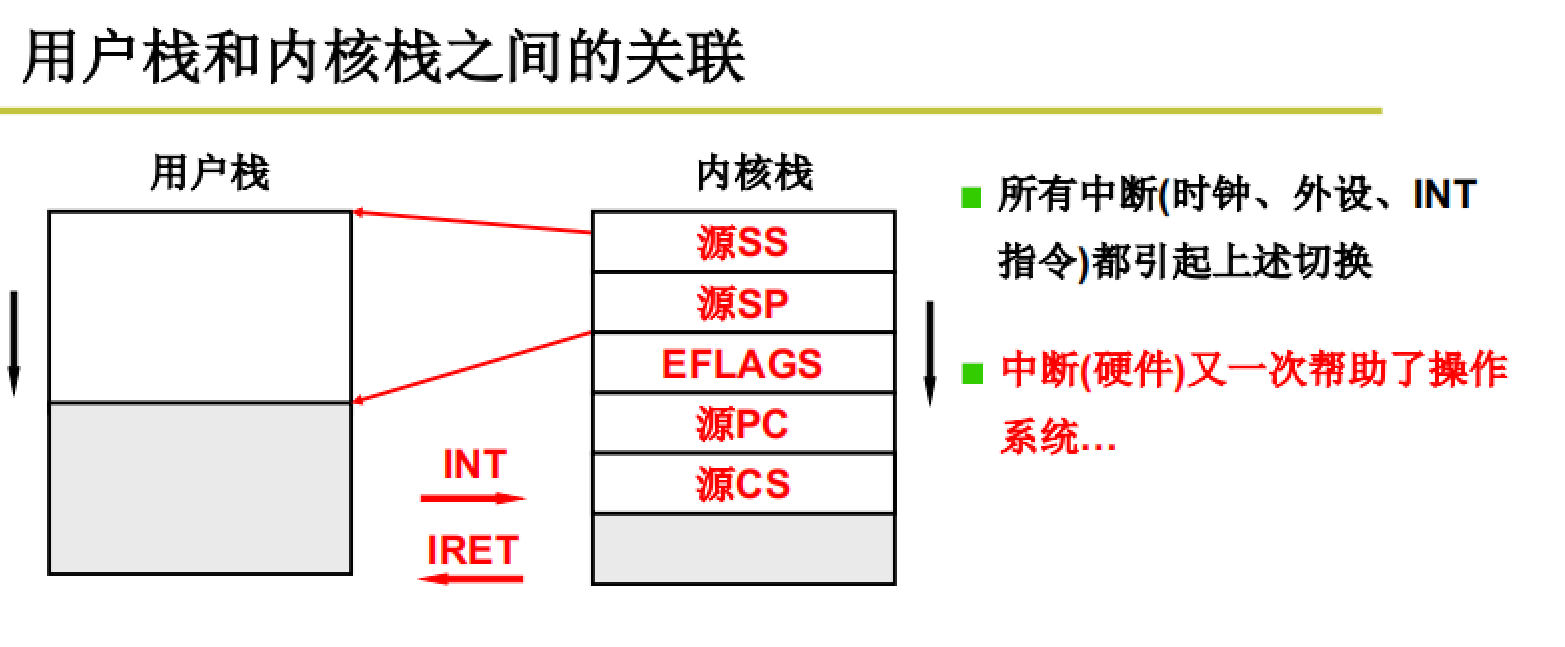
二者通过中断和返回可以进行切换,具体流程下面介绍。
用户级线程、进程、内核级线程三者之间的关联与区别
- 引入进程的目标是为了管理CPU,所以三者都是执行一个指令序列,无本质区别。
- 要执行一个指令序列,处理要分配栈和存储数据结构外,还要分配资源
- 进程必须在操作系统内核中创建,因为进程创建要涉及到计算机硬件资源的分配。所以,
进程中的执行序列就是一个内核级线程。
内核级线程的切换
我们以一个例子来看内核级线程的切换

如图所示,当用户程序进行系统调用后,会实现用户栈到内核栈的切换,即将用户栈信息和用户程序信息压栈保存,而后执行内核代码。
当内核级程序阻塞后就会进行线程的切换,如下图所示:
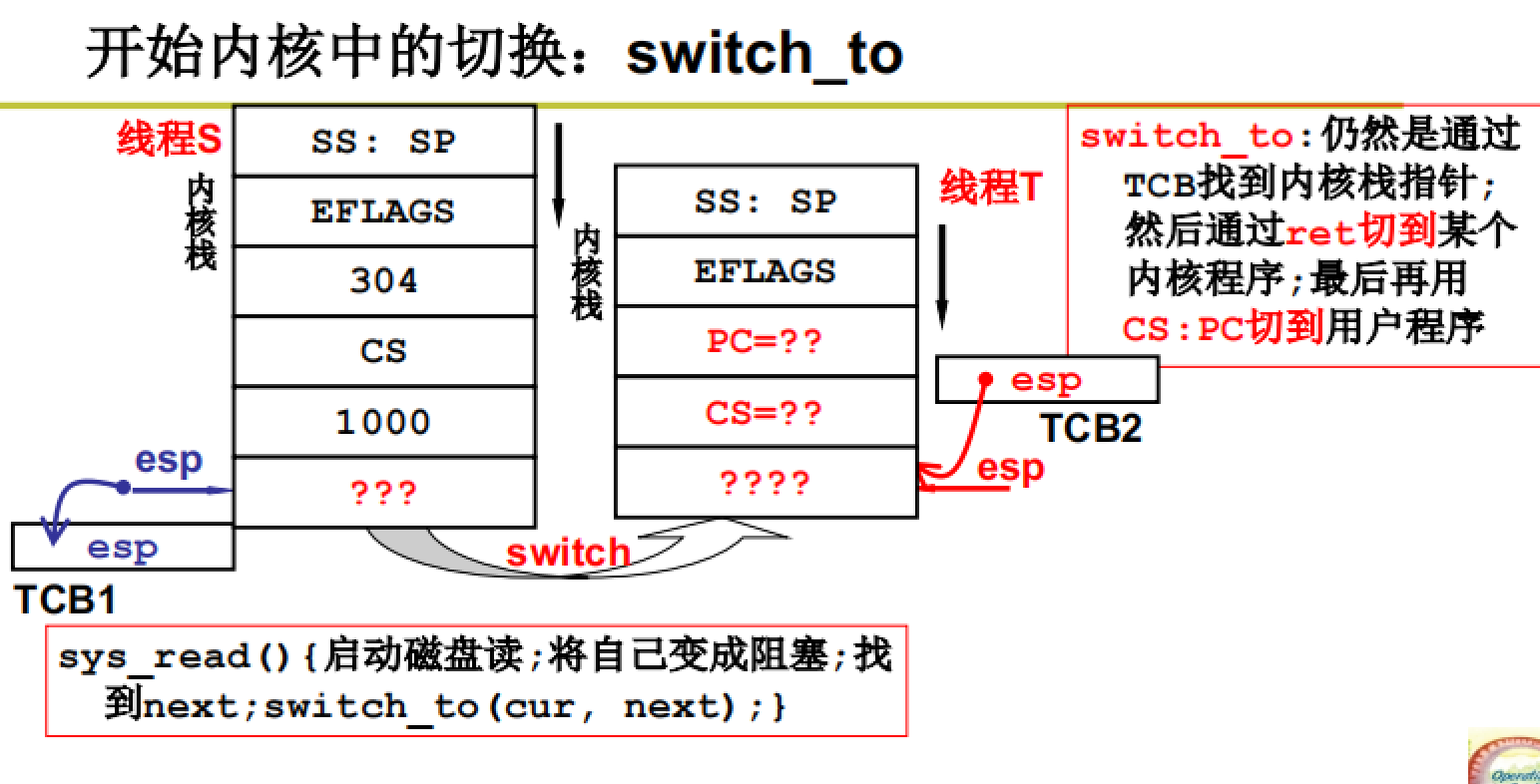
通过switch_it()函数实现内核级线程的切换。其本质是完成内核栈的切换。
我们需要理清上图中一些问号的含义:
最重要的部分是“????”表示一段可以完成返回的代码。通过其可以从内核栈返回用户栈,并执行用户态代码。
内核级线程切换五段论:
前面我们介绍用户级线程切换时主要涉及到三个部分:TCB切换、栈切换、PC指针切换。
内核级进程切换也是依照上三个部分,只是在具体的实现方面更加复杂,可以扩展为5个步骤:
中断进入。在int指令或者其他硬件中断的中断程序入口,需要记录当前程序在用户态的执行信息,包括当前使用的用户栈、程序的执行位置、状态信息等,都要压入内核栈中。调用schedule。当执行中断处理程序时发生阻塞,就会调用schedule切换TCB。具体步骤:先将现TCB状态改为阻塞,而后选取一个新的TCB,使用next指针指向此TCB。内核栈的切换。将当前ESP寄存器中的数据放到现TCB中,而后将next指向的TCB中的EIP信息放到寄存器中。这个步骤与用户态线程切换一致。中断返回。这个步骤是为下一步的用户栈切换做准备,主要是将内核栈中存储的用户态程序的执行现场恢复,也就是我们在中断进入时压入的状态信息返回。用户态切换。使用内核栈信息,将CS:EIP和SS:ESP寄存器信息与用户态程序和用户栈对应即可。
具体的流程可见下图: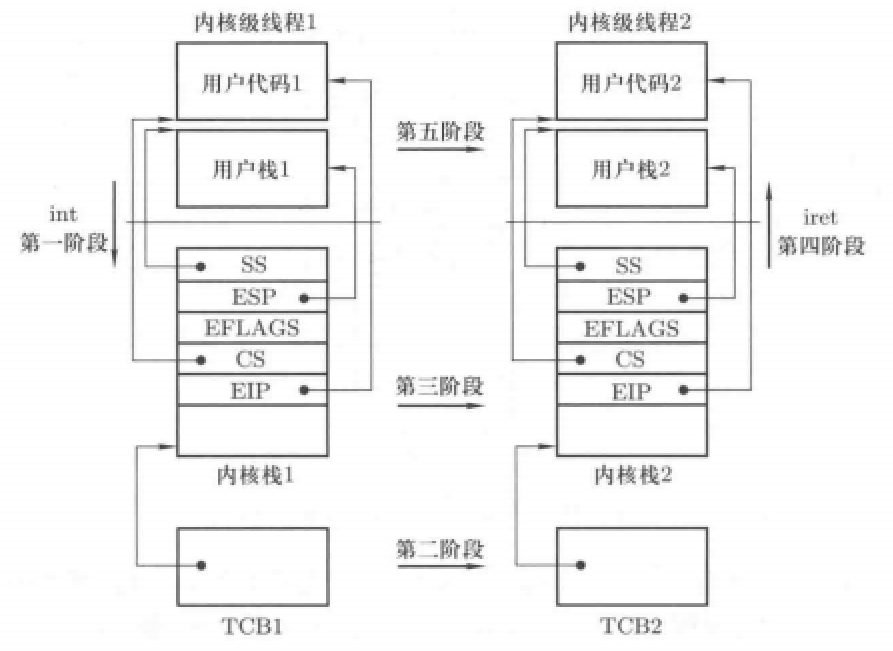
内核级线程的建立
在进行线程切换之前要先进行线程的创建
如图所示,主要涉及到:栈空间的申请和参数的初始化、TCB空间的申请和关联等工作,保证可以实现第一次切换后的正常执行。
用户级线程和核心级线程的对比:




