读写文本文件
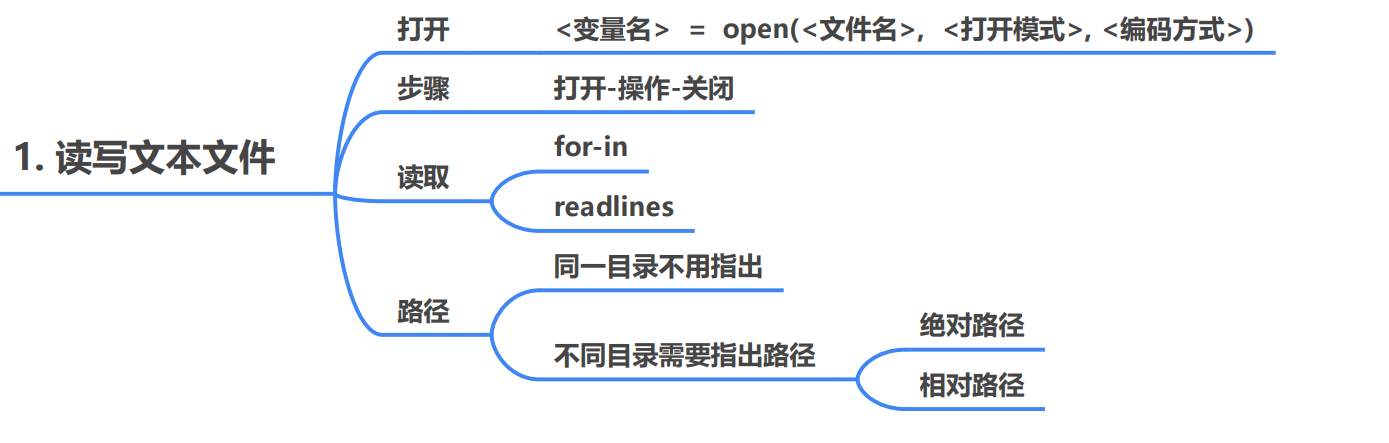
思维导图如下
本节需要掌握的方法 :
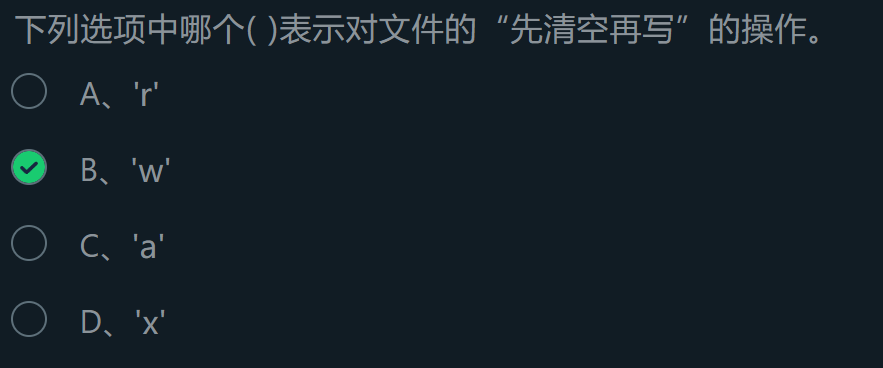
常见的操作模式 :
读取文件
使用open()函数用于文件的读取。
语法格式 :< 变量名> = open(<文件名>,<打开模式>,<编码方式>)
文件处理的步骤 :打开文件 –> 文件操作 —> 关闭文件
代码实例 :
1 2 3 fp = open ("student.txt" ,"r" ) print (fp.read()) fp.close()
注1 :对于中文文件 ,在读入是需要给出编码格式 fp = open("file","r",encoding = 'utf-8)
注2 :如果需要给出文件路径 ,有以下几个方法:
fp = open(‘c:\test\student.txt’,’r’) — 是绝对路径,使用两个\,前面的\为转义字符。
fp = open(‘c:/test/student.txt’,’r’) —是绝对路径
fp = open(‘./student.txt’,’r’) —是相对路径(.代表当前文件夹)
读取文件的几个方法 :
使用fp.read()直接输出全部内容。
1 2 3 fp = open ("student.txt" ,"r" ) print (fp.read()) fp.close()
使用for-in 逐行读取文件内容
1 2 3 4 fp = open ("student.txt" ,"r" ) for line in fp: print (line,end = '' ) fp.close()
使用readlines按行读取文件内容。
1 2 3 4 fp = open ("student.txt" ,"r" ) line = fp.readlines() print (line)fp.close()
注:这种方法是把文本封装为一个列表形式 。(包括换行符)
使用strip()方法把列表结尾的换行符去掉 :
1 2 3 4 5 fp = open ("student.txt" ,"r" ) for line in fp.readlines: line = line.strip() print (line,end = '' ) fp.close()
写入文本文件
在使用open函数打开时指定模式为“w”
直接看一个例子;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 file = ['a.txt' , 'b.txt' , 'c.txt' ] fp1 = [] for fp in file: fp1.append(open (fp,'w' )) for i in range (100 ): if i<50 : fp1[0 ].write(str (i)) else : fp1[2 ].write(str (i)) for fp in fp1: fp.close()
可以使用列表 利用append()方法进行文件的读取。使用时利用下标索引 即可。结束后注意关闭 。
注意 :write()只可以接收字符串参数 ,要使用str()进行转换。
读写二进制文件
使用open()函数时指定模式为’rb',即可读+二进制 模式。
一个例子 :
1 2 3 4 5 6 7 def is_gif (file ): fp = open (file,'rb' ) first4 = fp.read(4 ) fp.close() return first4 == b'GIF8' print (is_gif("./a.gif" ))
上下文管理语句:with(会在执行结束后自动关闭 ,不需要再使用fp.close())
语法格式 :with open(file,'r') as fp:
一个例子 :
1 2 3 4 5 6 def is_gif (file ): with open (file,'rb' ) as fp: first4 = fp.read(4 ) return first4 == b'GIF8' print (is_gif("./a.gif" ))
bytearray()方法
将二进制文件保存为字节数组。
1 2 3 4 5 6 with open ("./a.gif','rn') as fp: byt = bytearray(fp.read()) size = len(byt) for i in range(0,size): char = chr(byt[i])
综合实例:字母出现次数
方法1:使用字符串与列表一一对应
1 2 3 4 5 6 7 8 with open ("a.txt" , 'r' ) as fp: num = [0 ]*26 str1 = fp.read() for i in str1: if i.isalpha(): i = i.lower() num[ord (i)-97 ]+=1 print (num)
方法2:使用字典
改进方法 :字母与次数一一对应,并且降序排序。
1 2 3 4 5 6 7 8 9 10 11 12 fp = open ("a.txt" , 'r' ) str1 = fp.read() dict1 = {} for i in str1: if i.isalpha(): i = i.lower() if i in dict1: dict1[i]+=1 else : dict1[i]=1 print (sorted (dict1.items(), reverse=True , key = lambda e:e[1 ]))
注意 :使用sorted()进行排序时,可以通过key参数指定比较的对象。字典是使用key 进行比较,所以要先转换为元组 再排序。
实例二 :统计单词次数 1 2 3 4 5 6 7 8 9 10 11 12 13 fp = open ("a.txt" , 'r' ) wordfre = {} for i in fp: sword = i.strip().split() for word in sword: if word in wordfre: wordfre[word]+=1 else : wordfre[word]=1 print ("文档里共出现了%d个不同的单词" %len (wordfre),"统计如下:" )print (wordfre)fp.close()
与字母不同的是,这里要使用sword = i.strip().split()把原字符串以空格为分隔符号组成一个列表,其元素是一个个单词字符串。strip()方法是消除头尾两边 指定的字符,默认为空格和换行 。
扩展:输出次数最多的三个单词
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 fp = open ("a.txt" , 'r' ) wordfre = {} for i in fp: sword = i.strip().split() for word in sword: if word in wordfre: wordfre[word]+=1 else : wordfre[word]=1 print ("文档里共出现了%d个不同的单词" %len (wordfre),"统计如下:" ) print (wordfre) print (sorted (wordfre.items(), key=lambda e:e[1 ], reverse=True )) print ("出现次数最多的三个单词为:" ) wordl = [] for wd, num in wordfre.items(): wordl.append((num, wd)) wordl.sort(reverse=True ) for wd in wordl[:3 ]: print (wd) fp.close()
上代码是使用字典存储字母次数。dict.items()会返回一个列表 ,列表里的元素是一个个元组 。sorted(dict.items,key=lambda e:e[1])以值为依据 进行排序。结果返回一个新的列表。
第三方库:单词处理 jieba库
jieba是优秀的中文分词第三方库
三种不同的模式 :
精确模式:把文本精确的切分开,不存在冗余单词
全模式:把文本中所有可能的词语都扫描出来,有冗余
搜索引擎模式:在精确模式基础上,对长词再次切分
常用的函数 :
jieba.cut(s):精确模式,返回一个可迭代的数据类型。jieba.cut(s,cut_all=True):全模式,输出文本s中所有的可能单词jieba.cut_for_search(s):搜索引擎模式,适合搜索引擎建立索引的分词结果jieba.lcut(s):精确模式,返回一个列表,建议使用 jieba.lcut(s,cut_all=True):全模式,返回一个列表,建议使用 jieba.lcut_for_search(s):搜索引擎模式,返回一个列表,建议使用 jieba.add_word(w):向分词词典中增加新词w
代码实例:
1 2 3 4 import jieba as jprint (j.lcut("中国是一个伟大的祖国" ))print (j.lcut("中国是一个伟大的祖国" , cut_all=True ))print (j.lcut_for_search("中国是一个伟大的祖国" ))
看结果 :
worldcloud库
wordcloud 库把词云当作一个WordCloud对象
wordcloud.WordCloud()代表一个文本对应的词云
可以根据文本中词语出现的频率等参数绘制词云
绘制词云的形状、尺寸和颜色均可设定
以WordCloud对象为基础,配置参数、加载文本、输出文件
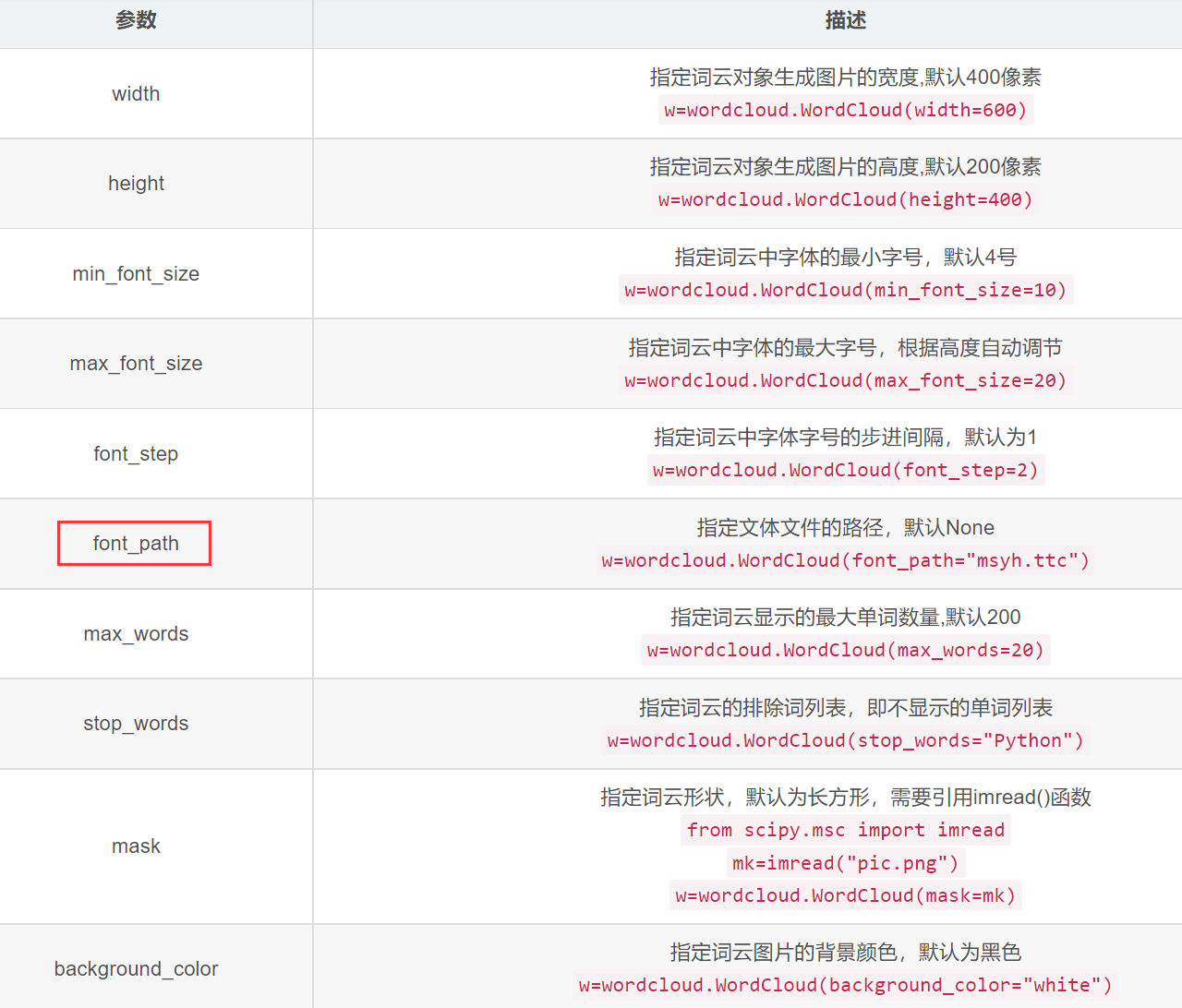
具体参数如下 :(配置对象参数)
输入方法 :w.generate(file):向词云对象里加载文本
输出方法 :w.to_file(filename):将词云输出为文件
一个实例 :
1 2 3 4 5 6 7 8 9 10 11 12 13 import jieba as jimport wordcloud as wtxt = open ("./2022政府工作报告.txt" , 'r' , encoding='utf-8' ) txt1 = txt.read() list1 = j.lcut(txt1) txt2 =" " .join(list1) w = w.WordCloud(font_path='msyhbd.ttc' ) w.generate(txt2) w.to_file("2022.jpg" )
结果 :
使用jieba库分好词语后可以通过join进行连接,在进行词云。
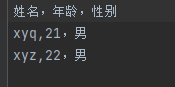
实训:三国演义词云 读取csv文件 csv文件的格式 :
使用open函数进行csv文件的读取
看代码 :
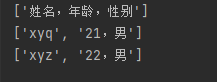
1 2 3 4 5 6 with open ("a.csv" , 'r' , encoding='utf-8' ) as fb: ls = [] for i in fb: i = i.replace("\n" , "" ) ls.append(i.split("," )) print (ls)
结果 :
注意点 :for in 一行行读取字符串,并去除换行符 。split(",")以逗号为分隔符进行字符串的分割,返回一个列表 。
使用csv模块进行:
看例子 :
1 2 3 4 5 import csvwith open ("a.csv" , 'r' , encoding='utf-8' ) as fb: csver = csv.reader(fb) for row in csver: print (row)
结果 :
使用csv模块进行写入:
看代码 :
1 2 3 4 5 6 7 8 9 10 11 12 import csvwith open ("a.csv" , 'w' , encoding='utf-8' ) as csver: csver_w = csv.writer(csver) with open ("b.txt" , "r" , encoding='utf-8' ) as fb: for line in fb.readlines(): line_list = line.strip("\n" ).split(" " ) csver_w.writerow(line_list) with open ("a.csv" , 'r' , encoding='utf-8' ) as csver: csver_r = csv.reader(csver) for row in csver_r: print (row)
在使用open 打开文件后再使用csv模块 选择写入还是读取模式。
序列化模块
定义引入:
序列化 :把变量从内存变成可存储、可传输的过程。序列化后的内容可以写入磁盘或者传输。
反序列化 :把序列化内容重新读入内存的过程。
模块:pickle
实现变量的序列化
基本操作:
p.dumps()把任意对象序列化为一个bytes,然后可以把这个bytes写入文件夹。p.dump()把对象序列化后写入一个file-like Object。p.loads()将bytes反序列化出对象。p.load()将file-like Object 反序列化出对象
例子 :
1 2 3 4 5 6 7 8 9 import pickle as pfp = open ("a.txt" ,"rb" ) mydict = dict (name="xyq" , age=21 ) pickle_1 = p.dumps(mydict,fp) print (pickle_1)
结果如下 :
反序列化实例 :
1 2 3 4 5 6 7 8 9 10 11 import pickle as pfp = open ("a.txt" ,"wb" ) mydict = dict (name="xyq" , age=21 ) p.dump(mydict,fp) with open ('c.txt' ,'rb' ) as fp: data = p.load(fp) print (data)
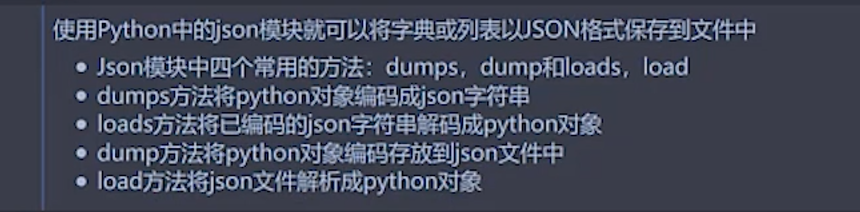
模块:json
定义介绍:
json是现在流行的跨平台的数据交换格式 。
例如 :jupyter配置文件就是json文件。
现在已经成为异构系统之间 交换数据的事实标准 。
python数据类型和json类型对应关系 :
json模块介绍:
模式方法 :
注意 :dumps是编码字符串,而dump是写入文件。前者有接收值,后者直接操作。//字典或者列表可以转换。
代码实例 :
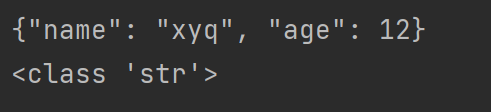
1 2 3 4 5 6 7 8 9 10 import jsondict1 = {"name" :"xyq" , "age" :12 } json_str = json.dumps(dict1) print (json_str)print (type (json_str))dict2 = json.loads(json_str) print (dict2)print (type (dict2))
看结果 :
也就是说,json.dumps将一个python的字典 转换为了一个字符串 ,但是还是字典的样式 。而后json.loads将json字符串 转为了python字典 。具体的转换原理见下实训 。
文件目录操作
思维导图:
os模块和os.path
这个模块是主要访问操作系统功能的模块
几个基本功能:
1 2 3 4 5 6 7 8 9 import osprint (os.name) print (os.stat("./b.txt" )) os.rename("b.txt" , "os2.txt" ) print (os.path.exists("./a.txt" )) print (os.path.isfile("os.txt" )) print (os.path.split("os.txt" )) print (os.path.splitext("os.txt" ))
结果 :
与操作目录有关的功能:
创建目录 :
os.listdir("目录"):列出当前目录的内容os.makedir("./xyq"):在指定位置创建一个目录os.makedirs("./xyq/name"):在指定位置创建多级目录
删除目录 :
os.rmdir("./xyq"):删除目录,要求此目录为空os.removedirs("./xyq/xyz"):删除多级目录
判断目录 :
os.pathisdir("./a.txt"):判断是否为目录
os模块实训 将一个文件file1重命名为file2(考虑健壮性)
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import os, os.pathfile1 = input ("输入要重命名的文件:" ) file2 = input ("输入重命名后的文件:" ) file_list = os.listdir("." ) if file1 in file_list: while (file2 in file_list): choice = input ("有重名,是否继续(Y/N):" ) if choice == "Y" or choice == "y" : file2 = input ("输入新的名字:" ) else : break else : os.rename(file1, file2) print ("命名成功!" ) else : print ("文件不存在。" )
结果 :
几个注意点 :os.listdir获取当前目录的文件,返回一个列表 。用于判断是否有重命名文件 。while else 进行重复输入。else语句是当while语句顺利执行后 执行。
遍历目录的三种方式
输出目录下的所有文件和目录
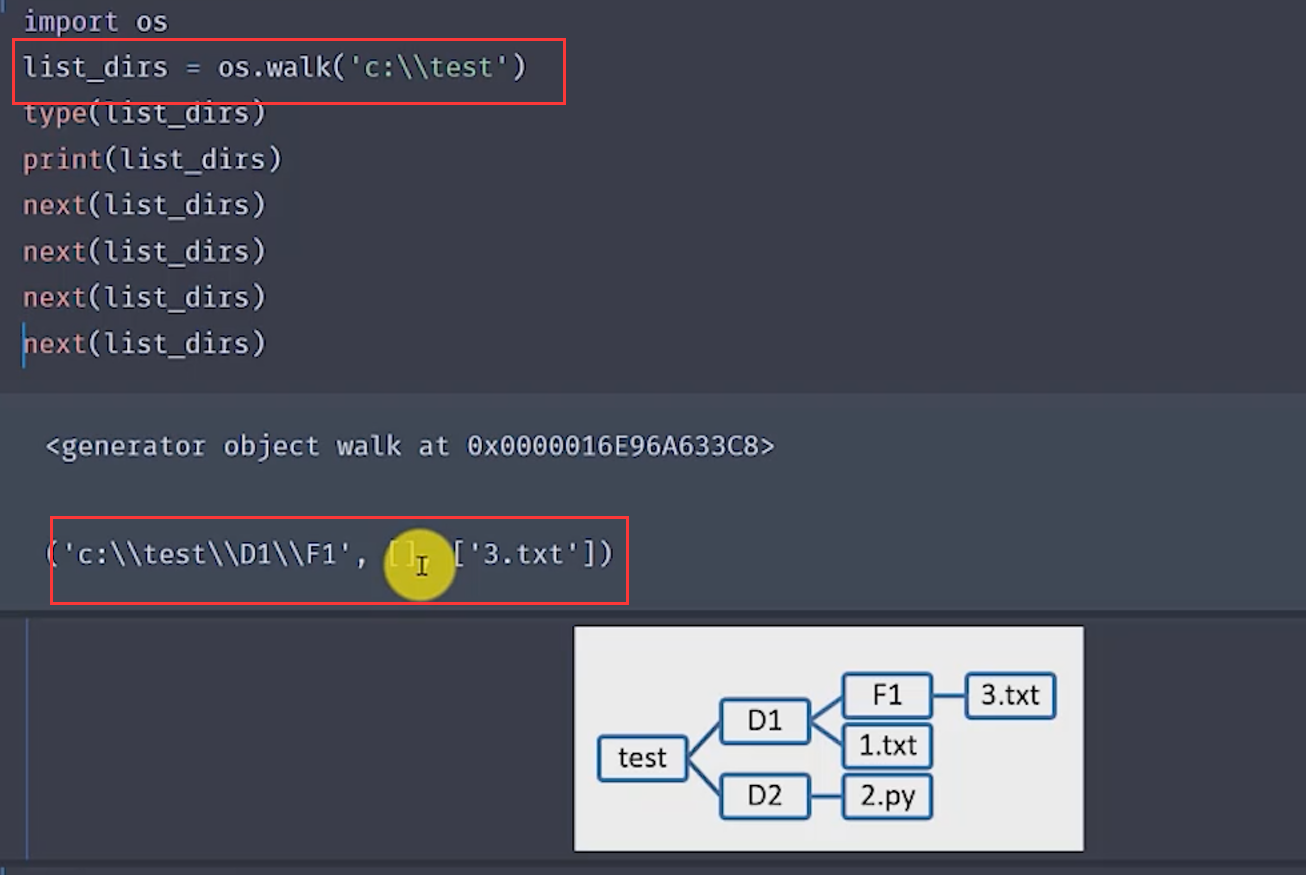
第一种方法 :os.walk()函数
返回值是一个生成器 。返回值是一个三元组 。
看一个例子 :
可见,使用walk函数返回一个生成器 ,需要通过next()进行输出。三元组 :当前目录,目录下的目录,目录下的文件。
看一个例子:输出目录
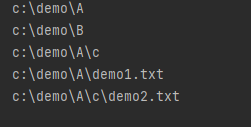
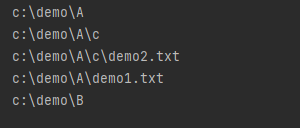
1 2 3 4 5 6 7 8 9 10 11 12 13 import osdef visit (path ): if not os.path.isdir(path): print ("目录不存在" ) return list_dir = os.walk(path) for root, dir1 , file1 in list_dir: for d in dir1: print (os.path.join(root,d)) for f in file1: print (os.path.join(root, f)) visit("c:\\demo" )
结果 :注意点 :os.path.join()输出根目录。walk返回的元组的元素,其中第二、三个是列表 ,可以进行for in 。
一个例子:计算指定路径下文件字节数,除去指定的路径
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import osfrom os.path import join, getsizedef visit (path ): if not os.path.isdir(path): print ("目录不存在" ) return list_dir = os.walk(path) for root, dir1 , file1 in list_dir: print (root, "consumes" , end=' ' ) print (sum ([getsize(join(root, name)) for name in file1]), end = " " ) print ("bytes in" , len (file1), "non-dir files" ) if "B" in dir1: dir1.remove("B" ) visit("c:\\demo" )
结果 :注意 :os.path.getsize获取文件的字节数。列表生成器 将多个文件的字节数放到列表。
第二个方法:深度遍历策略
看代码 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import osfrom os.path import join, isdir, isfiledef visit (path ): if not os.path.isdir(path): print ("目录不存在" ) return list_dir = os.listdir(path) for name in list_dir: path1 = join(path, name) if isfile(path1): print (path1) elif isdir(path1): print (path1) visit(path1) visit("c:\\demo" )
看结果 :
深度优先遍历的关键在于如果发现目录就会直接进入 ,而不是输出别的文件。
广度遍历策略:
看代码 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import osfrom os.path import join, isdir, isfiledef visit (path ): if not os.path.isdir(path): print ("目录不存在" ) return dirs = [path] while dirs: current = dirs.pop(0 ) list_dir = os.listdir(current) for name in sorted (list_dir): path1 = join(current, name) if isfile(path1): print (path1) elif isdir(path1): print (path1) dirs.append(path1) visit("c:\\demo" )
看结果 :
广度优先的关键在于使用了队列 (利用列表的方法进行模拟)。
异常处理
思维导图:
Python中的异常类
定义引入:
语法错误 :在解析代码时出现的错误。当代码不符合Python的语法规则是,会报错SyntaxError。运行时错误 :语法正常,但是在运行时出现错误,但是是非致命的,即为异常。
什么是异常 ?异常是因为程序出错而在正常控制流以外采取的行为,当Python检测到一个错误时,解释器就会指出流无法进行。
具体介绍:Python中的异常类
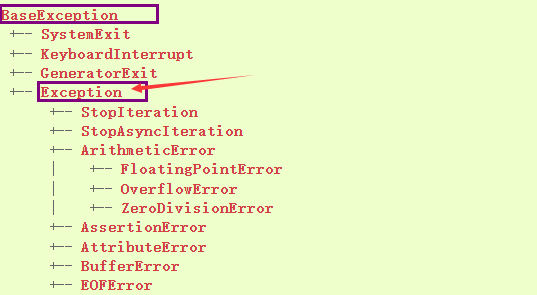
python所有的错误都是从BaseException类派生的。常见的错误类型和继承关系如下:https://docs.python.org/zh-cn/3.8/library/exceptions.html
捕获和处理异常
为了提高程序的健壮性和人机交互的友好性,需要对异常进行捕获和处理。
在Python中,我们可以将那些在运行时可能会出现状况的代码放在try代码块中,在try代码块的后面可以跟上一个或多个except来捕获可能出现的异常状况。FileNotFoundError ,指定了未知的编码会引发LookupError ,而如果读取文件时无法按指定方式解码会引发UnicodeDecodeErIor,我们在try后面 跟上了三个except 分别处理这三种不同的异常状况。最后我们使用finally代码块来关闭打开的文件,释放掉程序中获取的外部资源,由于finally块的代码不论程序正常还是异常都会执行到(甚至是调用了sys模块的exit函数退出Python环境,finally块都会被执行,因为exit函数实质上是引发了SystemExit异常) ,因此我们通常把f inally块称为“总是执行代码块”,它最适合用来做释放外部资源的操作。
如果不愿意在finally代码块中关闭文件对象释放资源,也可以使用上下文语法,通过with关键字指定文件对象的上下文环境并在离开上下文环境时自动释放文件资源。
语法格式 :try ...except [as ... ]...语句
try代码 块放置可能出现异常的语句,except代码块 中放置处理异常的语句。通过as语句 把异常对象保存在一个变量中。
一个例子:(文件open)
1 2 3 4 5 6 7 try : f = open ("d.txt" , "r" ) pass except FileNotFoundError: print ("无法打开指定文件!" ) pass
结果 :
注意 :没有报错,而是输出我们的提示语句。
一个例子:else的使用
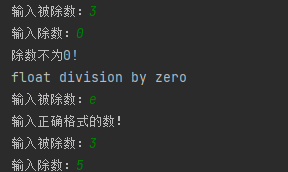
1 2 3 4 5 6 7 8 9 10 11 12 13 14 while True : try : a = float (input ("输入被除数:" )) b = float (input ("输入除数:" )) c = a/b except ZeroDivisionError as e1: print ("除数不为0!" ) print (e1) except ValueError: print ("输入正确格式的数!" ) else : break pass
结果 :
else 的代码块是在未捕获到异常后执行的。
一个例子:含有finally语句
1 2 3 4 5 6 7 8 9 10 11 try : infile = input () fb = open (infile, 'r' ) line = fb.readlines() print (line) except FileNotFoundError: print ("未找到文件" ) except UnicodeError: print ("解码错误" ) finally : pass
不论前面是否执行,最后都会执行finally代码块。
提醒:各个语句的执行顺序
try except else finally 混合使用的规则 :
先后次序 :try > except > else > finallytry语句 至少需要配对一个except 或者 finall 如果有else 必须要一个except
raise语句
通过这个关键字可以引发抛出异常。
1 2 3 4 5 6 7 8 class RaiseError (ValueError ): pass def fun (a,b ): if b == 0 : raise RaiseError("分母不可为零" ) fun(3 ,0 )
结果 :
在使用前需要先定义一个RaiseError类。
排查异常和记录异常
程序员不可能捕获所有的异常,一旦这些异常被解释器捕获,就会使得程序结束。sys模块和logging模块帮助我们记录排查异常。
sys模块的使用
使用sys.exc_info获取最近引发的异常。特别适用于except代码块。三元组 :(type,value/message,traceback)
一个例子 :
1 2 3 4 5 6 7 import systry : a = 3 /0 except : tuple = sys.exc_info() print (tuple )
结果 :
logging模块的使用
帮助我们记录错误信息,还可以把错误信息记录到日志文件。(日志级别为ERROR)
一个例子 :
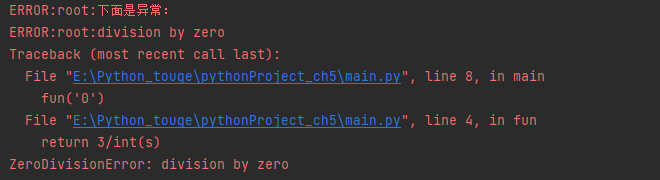
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import loggingdef fun (s ): return 3 /int (s) def main (): try : fun('0' ) except Exception as e1: logging.exception(e1) logging.error("下面是异常:" ) if __name__ == '__main__' : main()
结果 :
扩展积累 实训作业
使用csv模块进行一列的读取
1 2 3 4 5 6 7 8 9 10 11 import csvdef readcsv (): with open ("book.csv" ,'r' ,encoding='utf-8' ) as fb: data = csv.reader(fb) list1 = [row[0 ] for row in data] for i in list1: print (i) if __name__ == '__main__' : readcsv()
使用列表生成式进行列的获取。每一次for in都是返回一个列表 。
使用csv模块读取一行
1 2 3 4 5 6 7 8 9 10 11 import csvdef readcsv (): with open ("book.csv" ,'r' ,encoding='utf-8' ) as fb: data = csv.reader(fb) for i,row in enumerate (data): if i != 0 : print (row) if __name__ == '__main__' : readcsv()
使用emumerate方法获取索引。
将csv文件导入字典
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import csvdef readcsv (): with open ("book.csv" ,'r' ,encoding = 'utf-8' ) as fb: list1 = [] list2 = [] data = csv.reader(fb) for i,low in enumerate (data): if i == 0 : list1 = low x = low[0 ] y = low[1 ] else : dict1 = {x:low[0 ],y:low[1 ]} list2.append(dict1) print (list2) if __name__ == '__main__' : readcsv()
有一个非常非常需要注意的地方:使用dict1[xx] = xx进行赋值时,这个值是存储在一个位置的,也就是说就算你在前面将这字典导入了列表,后面赋予新的值后原来列表里的值也会随之改变 。所以只能新建字典。
素数导入文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from math import sqrtdef is_prime (n ): """判断素数的函数""" assert n > 0 for factor in range (2 , int (sqrt(n)) + 1 ): if n % factor == 0 : return False return True if n != 1 else False def store (): files = ["a.txt" ,"b.txt" ,"c.txt" ] fp = [] for file1 in files: fp.append(open (file1,"w" )) for i in range (1 ,10000 ): if i <= 99 and is_prime(i): i = str (i) fp[0 ].write(i) fp[0 ].write("\n" ) elif 100 <=i<=999 and is_prime(i): i = str (i) fp[1 ].write(i) fp[1 ].write("\n" ) elif is_prime(i): i = str (i) fp[2 ].write(i) fp[2 ].write("\n" )
注意点 :写入内容为字符串 ,所以要使用str()进行转换。write("\n")写入换行符 。
将字符串转换为字典(与前面的csv文件变成字典类似)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import jsondef main (name ): fb = open (name,"r" ,encoding='utf-8' ) list1 = [] list2 = [] for line in fb: list1.append(line.strip().split(" " )) for i,low in enumerate (list1): if i == 0 : x = low[0 ] y = low[1 ] else : dict1 = {x:low[0 ],y:low[1 ]} list2.append(dict1) print (list2) fb.close() if __name__ == '__main__' : name = input () main(name)
注意点 :for i,low in enumerate(list1)可以对列表中的元素进行索引后选择需要的行。line.strip().split(" ")可以将每一行字符串变成一个列表。
json字符串的转换
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 from typing import List from enum import Enum""" 全局标量定义来表示符合 JSON 所规定的数据类型 (学生可以使用字典结构表示此结构) 其中: BEGIN_OBJECT({) END_OBJECT(}) BEGIN_ARRAY([) END_ARRAY(]) NULL(null) NUMBER(数字) STRING(字符串) BOOLEAN(true/false) SEP_COLON(:) SEP_COMMA(,) """ BEGIN_OBJECT = 1 BEGIN_ARRAY = 2 END_OBJECT = 4 END_ARRAY = 8 NULL_TOKEN = 16 NUMBER_TOKEN = 32 STRING_TOKEN = 64 BOOL_TOKEN = 128 COLON_TOKEN = 256 COMMA_TOKEN = 512 END_JSON = 65536 json_index = 0 def token_parse (json_str: str , json_index: int ) -> (tuple , int ): """ 完成词法解析,返回token :param json_str: 输入的json字符串 :param json_index: json字符串的位置 :return: 返回已处理好的token和json字符串的位置 """ def read_num (json_index: int ): """ 处理数字 :param json_index: json字符串的位置 :return: 返回处理数字后的token序列 """ rem = json_str[json_index: json_index + 2 ] return (NUMBER_TOKEN, rem), json_index + 2 def read_str (json_index: int ): """ 处理字符串 :param json_index: json字符串的位置 :return: 返回处理字符串后的token序列 """ k = 0 num = json_index while json_str[num+1 ] != '"' : num += 1 k += 1 rem = json_str[json_index+1 : json_index + 1 + k] return (STRING_TOKEN, rem), json_index + 2 + k def read_null (): """ 处理null :return: 返回处理null后的token序列 """ rem = json_str[json_index: json_index + 4 ] return (NULL_TOKEN, rem), json_index + 4 def read_bool (s: str ): """ 处理true,false :param s: json字符串 :return: 返回处理true,false后的token序列 """ if s == 't' : rem = json_str[json_index: json_index + 4 ] return (BOOL_TOKEN, rem), json_index + 4 else : rem = json_str[json_index: json_index + 5 ] return (BOOL_TOKEN, rem), json_index + 5 if json_index == len (json_str): return (END_JSON, None ), json_index elif json_str[json_index] == '{' : return (BEGIN_OBJECT, json_str[json_index]), json_index + 1 elif json_str[json_index] == '}' : return (END_OBJECT, json_str[json_index]), json_index + 1 elif json_str[json_index] == '[' : return (BEGIN_ARRAY, json_str[json_index]), json_index + 1 elif json_str[json_index] == ']' : return (END_ARRAY, json_str[json_index]), json_index + 1 elif json_str[json_index] == ',' : return (COMMA_TOKEN, json_str[json_index]), json_index + 1 elif json_str[json_index] == ':' : return (COLON_TOKEN, json_str[json_index]), json_index + 1 elif json_str[json_index] == 'n' : return read_null() elif json_str[json_index] == 't' or json_str[json_index] == 'f' : return read_bool(json_str[json_index]) elif json_str[json_index] == '"' : return read_str(json_index) if json_str[json_index].isdigit(): return read_num(json_index) def tokenizer (json_str: str ) -> list : """ 生成token序列 :param json_str: :return: """ json_index = 0 tk, cur_index = token_parse(json_str, json_index) token_list = [] generate_tokenlist(token_list, tk) while tk[0 ] != END_JSON: tk, cur_index = token_parse(json_str, cur_index) generate_tokenlist(token_list, tk) return token_list def generate_token (tokentype: int , tokenvalue: str ) -> tuple : """ 生成token结构 :param tokentype: token的类型 :param tokenvalue: token的值 :return: 返回token """ token = (tokentype, tokenvalue) return token def generate_tokenlist (tokenlist: list , token: tuple ) -> list : tokenlist.append(token) return tokenlist def parse_json (tokenlist: list ): def check_token (expected: int , actual: int ): if expected & actual == 0 : raise Exception('Unexpected Token at position %d' % json_index) def parse_json_array (): """ 处理array对象 :return: 处理json中的array对象 """ global json_index expected = BEGIN_ARRAY | END_ARRAY | BEGIN_OBJECT | END_OBJECT | NULL_TOKEN | NUMBER_TOKEN | BOOL_TOKEN | STRING_TOKEN while json_index != len (tokenlist): json_index += 1 token = tokenlist[json_index] token_type = token[0 ] token_value = token[1 ] check_token(expected, token_type) if token_type == BEGIN_OBJECT: array.append(parse_json_object()) expected = COMMA_TOKEN | END_ARRAY elif token_type == BEGIN_ARRAY: array.append(parse_json_array()) expected = COMMA_TOKEN | END_ARRAY elif token_type == END_ARRAY: return array elif token_type == NULL_TOKEN: array.append(None ) expected = COMMA_TOKEN | END_ARRAY elif token_type == NUMBER_TOKEN: array.append(int (token_value)) expected = COMMA_TOKEN | END_ARRAY elif token_type == STRING_TOKEN: array.append(token_value) expected = COMMA_TOKEN | END_ARRAY elif token_type == BOOL_TOKEN: token_value = token_value.lower().capitalize() array.append({'True' : True , 'False' : False }[token_value]) expected = COMMA_TOKEN | END_ARRAY elif COMMA_TOKEN: expected = BEGIN_ARRAY | BEGIN_OBJECT | STRING_TOKEN | BOOL_TOKEN | NULL_TOKEN | NUMBER_TOKEN elif END_JSON: return array else : raise Exception('Unexpected Token at position %d' % json_index) def parse_json_object (): """ 处理json对象 :return:处理json中的json对象 """ global json_index expected = STRING_TOKEN | END_OBJECT key = None while json_index != len (tokenlist): json_index += 1 token = tokenlist[json_index] token_type = token[0 ] token_value = token[1 ] check_token(expected, token_type) if token_type == BEGIN_OBJECT: obj.update({key: parse_json_object()}) expected = COMMA_TOKEN | END_OBJECT elif token_type == END_OBJECT: return obj elif token_type == BEGIN_ARRAY: obj.update({key: parse_json_array()}) expected = COMMA_TOKEN | END_OBJECT | STRING_TOKEN elif token_type == NULL_TOKEN: obj.update({key: None }) expected = COMMA_TOKEN | END_OBJECT elif token_type == STRING_TOKEN: pre_token = tokenlist[json_index - 1 ] pre_token_value = pre_token[0 ] if pre_token_value == COLON_TOKEN: value = token[1 ] obj.update({key: value}) expected = COMMA_TOKEN | END_OBJECT else : key = token[1 ] expected = COLON_TOKEN elif token_type == NUMBER_TOKEN: obj.update({key: int (token_value)}) expected = COMMA_TOKEN | END_OBJECT elif token_type == BOOL_TOKEN: token_value = token_value.lower().capitalize() obj.update({key: {'True' : True , 'False' : False }[token_value]}) expected = COMMA_TOKEN | END_OBJECT elif token_type == COLON_TOKEN: expected = NULL_TOKEN | NUMBER_TOKEN | BOOL_TOKEN | STRING_TOKEN | BEGIN_ARRAY | BEGIN_OBJECT elif token_type == COMMA_TOKEN: expected = STRING_TOKEN elif token_type == END_JSON: return obj else : raise Exception('Unexpected Token at position %d' % json_index) array = [] obj = {} global json_index if tokenlist[0 ][0 ] == BEGIN_OBJECT: return parse_json_object() elif tokenlist[0 ][0 ] == BEGIN_ARRAY: return parse_json_array() else : raise Exception('Illegal Token at position %d' % json_index) if __name__ == "__main__" : raw_data = input () jlist = tokenizer(raw_data) try : jdict = parse_json(jlist) print (jdict) except BaseException as result: print (result)
具体解析:
1 2 3 4 5 6 7 8 9 10 11 12 13 JSON 解析器从本质上来说就是根据 JSON 文法规则创建的状态机,输入是一个 JSON 字符串,输出是一个包含JSON各个部分的字典。一般来说,解析过程包括词法分析和语法分析两个阶段。词法分析阶段的目标是按照构词规则将 JSON 字符串解析成 Token 流,举个例子: 比如有如下的 JSON 字符串:{"name":"小明","age":14} 生成Token流为: [(1, '{'),(64, 'name'),(256, ':'),(64, '小明'),(512, ','),(64, 'age'),(256, ':'),(32, 14),(4, '}'),(65536, None)] 可以看出字符串中的每一个部分,都用一个数字进行表示,其中这些数字分别代表不同含义,用来标识JSON字符串中不同的部分,例如:(1, '{')中‘1’表示JSON对象开始的部分,在程序中用BEGIN_OBJECT代表。 通过词法分析阶段得到Token 流后,需要对Token 流进行语法分析。语法分析的目的是根据 JSON 文法检查上面 Token 序列所构成的 JSON 结构是否合法。比如 JSON 文法要求非空 JSON 对象以键值对的形式出现,不能是一些非法形式。比如:‘{"name":"小明","age":14,’,(由于大括号没有封闭,所以结构非法)。这时候我们采用递归下降的方法逐一处理每一个Token,判断他们的结构是否合法,并组成字典结构。 上文的TOKEN流最终成为如下的字典结构: {'name': '小明', 'age': 14} 注意:输入的是JSON字符串,类型为str,输出为字典结构,类型为dict,看起来很像但并不一样
注意 :不是字典 。我们要做的就是将这个字符串转换为对于的python格式。
测试
写入文件
读入文件
文件指针:
os模块