Python课程学习-ch5 函数和模块
5.1函数的定义与调用
本章思维导图
5.1.1 函数的定义与说明文档
函数的定义:
函数是一段具有特定功能的、可复用的语句组,是一种功能抽象。
定义格式:
1 | def <函数名>(参数列表): |
代码示例:(阶乘)
1 | def fac(n): # 这里函数的参数为形参,不需要给出参数的类型。 |
注:在python的math模块已经有专门的**阶乘函数factorial()**。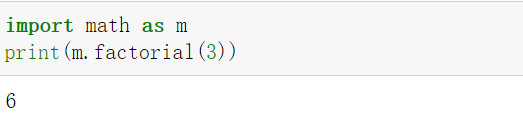
函数的调用:
- 使用函数名进行已有函数的调用
- 函数调用时传入实参,带入运算
- 根据return 决定是否返回结果
说明文档:
在函数声明和函数体之间使用三引号写入说明文档,使用help()进行查看。
示例:
1 | def fac(n): |
结果:
注:也可以使用函数的doc属性查看帮助文档。
5.1.2 函数的返回值
函数的返回值概述:
- 函数不带return,则无返回值,相当于返回None。
- 程序有多个返回值,可以封装为列表进行返回,也可以直接返回。直接返回时以元组的形式。
代码示例: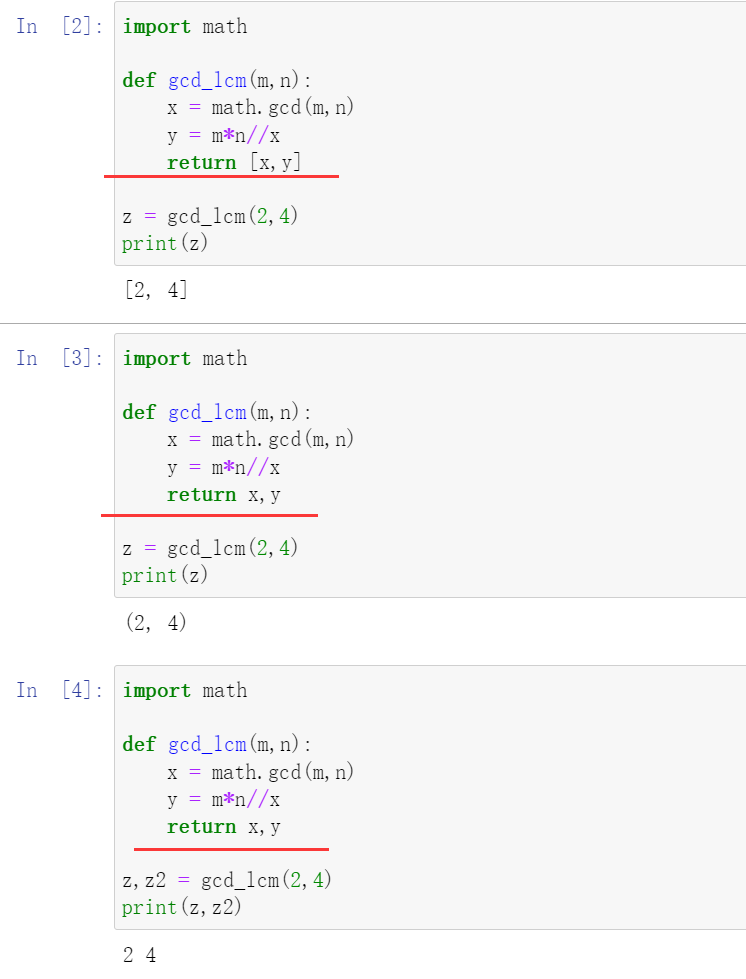
注:使用序列解包依次赋值亦可。
5.1.4 函数的嵌套
函数允许嵌套定义函数;函数调用自己为递归。
代码示例:(二分查找)
1 | def binary_search(target,data,low,high): |
注意事项:递归的次数限制
- python设置了递归的最大次数以防止无限递归。
- 使用
sys 模块进行这个次数的查看与设置。(见代码)
1 | import sys |
结果演示:
5.1.5 函数执行的起点
脚本可以独立运行:
C语言程序的起点时main()函数,而python的脚本程序可以不写main。
每一个python 在运行时,都有一个__name__属性.
__name__的默认值是__ main__
这个属性的作用就是判断一个脚本程序是直接运行还是作为模块进行调用。
如果不希望直接运行,可以加上以下代码:
1 | if __ name __ == "__ main__ ": |
5.2 函数的参数
本小节思维导图:
5.2.1 位置参数
调用函数时实参和形参的数目和顺序必须严格一致。
例如下例(二分查找):
当实参与形参数目不一致时会报错。
5.2.2 默认值参数
如果大部分参数是某个值,可以设置为默认值参数,简化函数的调用。
代码实例:
1 | def printinfo(name,age=18): |
结果: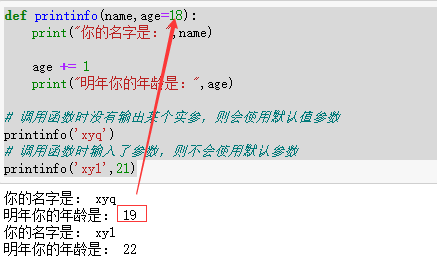
注意事项:
- 默认值参数在定义时必须放在正常参数的后面。即默认值参数右边不要有非默认值参数。
- 非默认值参数必须传入实参。
- 在调用时不可以对实参进行赋值。如:
printinfo(age = 19) - 默认参数必须是不可变对象,如:int,str,tuple等。如果是list,dict会发生数据错误。

5.2.3 可变参数
对于参数不确定的情况,可以使用可变参数的方式。
代码实例:
1 | def f(a,b,*c): |
结果:
使用*c 的方式定义可变参数,在调用时,会把传入的实参封装为一个元组。可以使用for in 循环进行使用。
5.2.4 关键字参数
**kw接收参数并将参数封装为字典。
代码实例:
1 | def student(name,age,**kw): |
结果:
5.2.5 命名关键字
承接上节,当我们需要给定关键字参数具体名字的时候,可以使用:
def f(name,age,* ,city,baba)
代码实例:
注:关键字参数更多的是用于对内置函数或者模块函数的功能进行调整。
5.2.6 综合实例:计算月份平均天数
- 使用位置参数
1 | def month_aver(start,end): |
- 使用可变参数
1 | def month_aver(*avge): |
注意:使用*avge作为可变参数,使用是会把传入的参数封装为元组。
- 使用默认参数
1 | def month_aver(start,end=12): |
注:在函数定义时使用默认参数指定end的值。
- 使用关键字参数
1 | def month_aver(start,*,end): |
注:使用*隔开关键字参数。在调用时指定该参数的值。
5.2.7 函数参数的传递方式
在python里,参数的传递方式采用值传递的方式。
先来看一个例子:
出现上述现象的原因在于:进行参数传递是只是传递的值,而不是内存地址。所以在函数里改变此变量不会对主函数有影响。
再来看一个例子: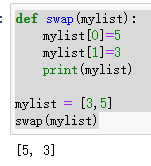
这里发现在函数里改变列表的值也会对主函数有影响。这是因为对于列表、字典这些可变序列在传递时传入的是内存地址。
5.3 lambda表达式
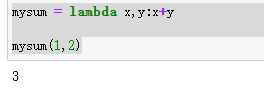
是一种匿名函数,可以把一些简单的函数利用这种简化方法进行实现。
5.4 变量的作用域
概述:

5.4.1 全局变量
在函数之外定义的变量,在程序执行全过程有效。
先看下面这个例子:
在1函里可以打印外部变量n的值,但是在2函数却报错了。原因在于一旦在函数里对某个变量进行操作,就会认为这个变量是局部变量,需要先定义。
5.4.2 局部变量
在函数里定义,仅在函数内部起作用。函数退出时自动销毁。
看个例子: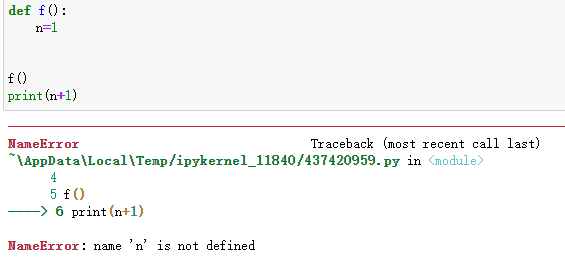
无法在函数之外获取局部变量。
5.4.3 二者之间的关系
一般情况下,局部变量和全局变量没有关系,就算他们的名称相同也不会相互影响。
global关键字
在函数内使用 global a 即可声明a为全局变量,在函数外也可以进行输出。

在函数内声明了全局变量,这个变量与外部先定义的变量就会指向同一个存储空间。
globals()和locals()访问全局变量和局部变量。

5.5 函数的高级特性
先放一个思维导图:

5.5.1 函数生成器
定义引入
生成器:一种惰性运算,需要一个元素时,才会产生对应元素,节省了存储空间。
先来看一个例子:斐波那契数列
1 | def fib(m): |
上例运行截图如下:
1 | def fib(m): |
上例运行截图:
对比分析:
上面两个例子的运行结果一样,但是具体的执行流程是不同的。前者是直接调用函数,而后执行完成;后者是函数生成器,根据迭代次数动态的进行调用。
再来看一个例子:生成器的执行流程

流程如下:
指定g为一个生成器 —> 进入for 循环 开始第一次循环—>执行fib 函数并运行到yield b 返回其值—> 输出其值而后执行打印语句—> 第二次循环,会从yield b语句下面的语句开始执行,直到再次返回yield b返回。
注意点:
1、使用 yield 关键字定义一个函数生成器。
2、生成器是惰性运算,需要获取其值时才会进行函数的调用与执行。
3、在函数生成器里,函数运行到yield后进会返回,下一次调用会接上次进行。
5.5.2 高阶函数
定义引入:
高阶函数:参数也可以是函数。
第一个高阶函数:map()
理解:映射
函数介绍:
简单理解就是将可迭代对象里的元素依次作用于函数,返回一个map对象(惰性运算)
看一个例子:
1 | def fun(x): |
运行结果:
可见,map函数就是将第二个参数里的值依次拿出参与参数1的运算并返回结果。
注:前面我们学习了lambda表达式,可以将一个简单函数简写,所以上例也可以这样写:l = list(map(lambda x:x**2,[1,2,3,4]))
map把运算规则进行了抽象,例如: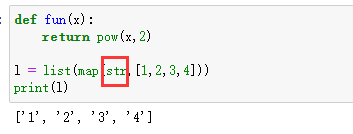
通过str将列表里的元素转换为字符形式。
第二个高阶函数:reduce
理解:化简
函数介绍:1reduce(func,iterable)
- 两个参数:func为函数、iterable为可迭代对象
- 作用:对序列中的第1、2个元素进行操作,得到的结果再与第三数据用func函数运算,最后得到一个结果。
直接看例子: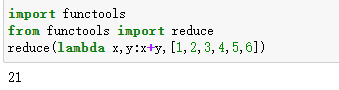
注:
1、reduce函数不是内置函数,需要进行functools模块的导入
2、此函数不需要返回值,而是直接输出结果。
第三个高阶函数:filter()
理解:过滤
函数介绍:filter(func or none,iterable) ---> filter object
- 两个参数:参数func为函数,iterable为可迭代对象
- 作用:函数依次作用于每一个元素,然后根据返回值是True还是False决定是否保留该元素。
- 返回值:filter 对象(属于惰性计算)
看一个例子:
1 | L1 = [1,2,3,4] |
运行结果: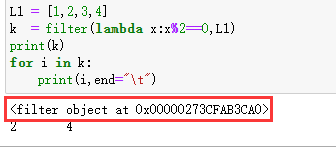
filter函数可以用于对列表进行过滤操作,输出其值不符合条件的元素。
5.5.3 偏函数partial
使用偏函数固定某个函数的参数值。
1 | import functools |
注意点:
1、partial函数需要导入functools模块才可以使用。
2、其作用就是将一个已有的函数变成一个某些参数固定的新函数。
3、此函数多用于日志。
5.5.4 修饰器(装饰器)
为现有的函数或类添加新的功能。
装饰器的执行流程
1 | def my_prety(func): |
运行结果:
分析上述代码:通过@my_prety标识my_prety为装饰器函数,当函数执行到这一句时就会去调用my_prety函数。这一句话的作用等价于:ordinary = my_prety(ordinary)。也就是说在调用执行ordinary函数时会调用后面的函数,这个函数以ordinary为参数。
深入理解装饰器函数
1 | def w1(func): |
结果如下:
对于原函数有参数的情况,闭包函数(也就是inner)也要有参数,并且为应对不同函数的参数数目不同的情况,可以使用可变参数和关键字参数。
5.6 模块化编程
老规矩,先放上思维导图:
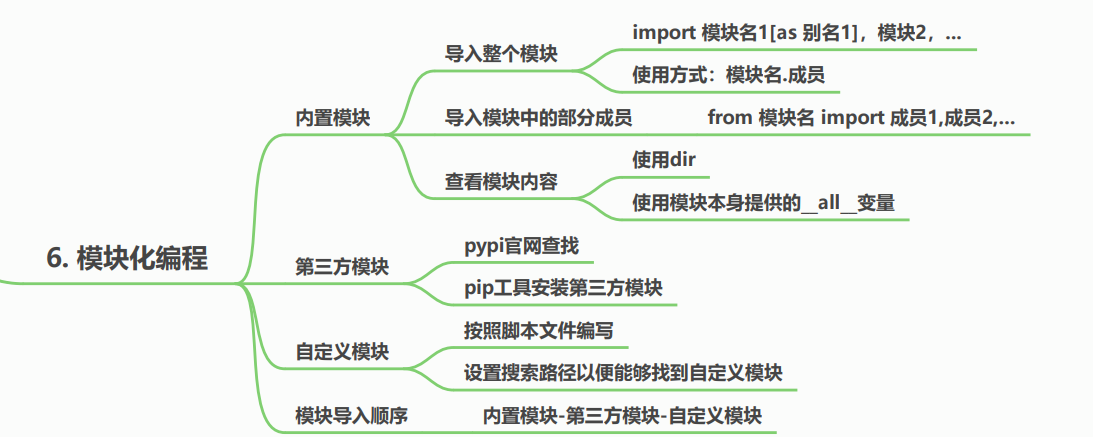
5.6.1 内置模块
Python安装完毕后,就可以使用的模块
下面介绍几种模块的导入方法:
- 导入整个模块
语法格式:import 模块名1,模块名2
代码示例:
注:使用as进行模块的别名
- 导入模块的某些成员
语法格式:from 模块1 import 成员1,成员2
代码示例:
- 模块的查看方法
(1) 使用dir()函数进行查看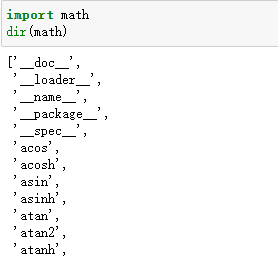
注:使用dir查询得到的为一个列表,可以使用for in 进行遍历。如下例: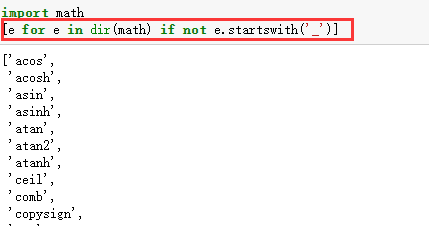
(2) 使用__all__属性进行查看
代码实例: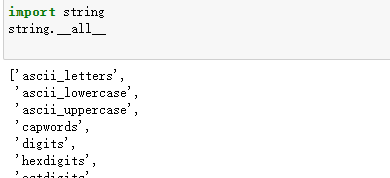
注:不是所有的模块都有__all__属性的。
5.6.2 第三方模块
第三方模块的查找:https://pypi.org/
模块的下载:pip install xxxx
Anaconda :Python的发行版本,内置很多第三方库。
5.6.3 自定义模块
自己编写完成的脚本可以直接作为模块进行使用。
使用import 进行导入即可。
来看一个例子:
- 先定义两个脚本文件main.py和prac.py


- 使用import main 将main.py作为模块导入prac.py。
运行结果如下:
可见,在prac中可以使用main里的函数,这里main就相当于模块。
- 删除main文件里的name属性判断
结果如下:
这里执行prac,发现会先执行main模块里的操作,再进行本程序操作。这是因为prac将main当做了一个直接执行的文件了。
通过上述例子我们可以直观的看到__name__属性的作用:用于区分一个文件是模块还是直接执行文件。
其原理也很简单,如果在程序中加上此代码,就会在执行此文件前进行判断,当其作为模块被导入时,__name__ 属性不会等于main,不满足判断条件,也就不会直接执行了。
5.7 Pyinstaller 打包
将py脚本打包成为exe文件。
下载方法:pip install pyinstall
使用方法:pyinstaller -F 脚本位置
通过pyinstaller -h 查看帮助文档。
5.8 练习补充
内容来自实训和测试
测试–函数部分
1、len(dict)是作用于key.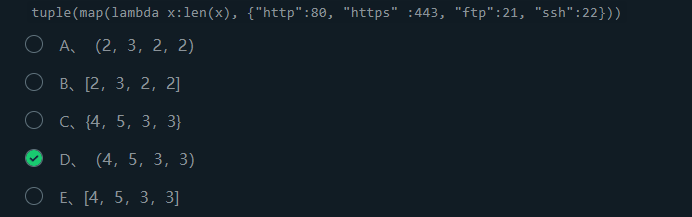
2、sort方法的扩展
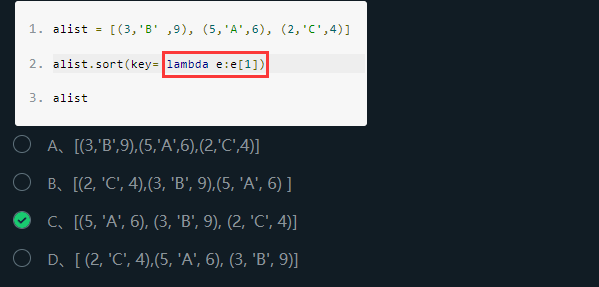
使用lambda表达式指定比较对象。
3、列表的可变性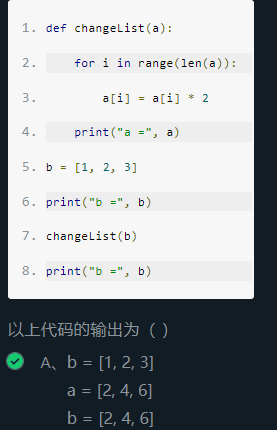
传递列表时传递的是存储位置,一变皆变。
实训作业
1、最大公约数与最小公倍数
使用辗转相除法进行求解。
1 | #gcd为求最大公约数的函数 |
2、整数的回文判断
先化为字符串再判断。
1 | def is_palindrome(num): |
3、求解素数
1 | def is_prime(num): |
4、莱布尼兹公式计算Π值
莱布尼兹公式:π = 4/1 − 4/3 + 4/5 − 4/7 + 4/9 − 4/11…
1 | def estimate_pi_by_leibniz(n_terms = 1000): |
通过-1的n次方获取正负.




