写在最前面:什么是面向对象程序设计?
7.1 类和对象
思维导图如下:
7.1.1 定义类和创建对象
基本概念:
类是对象的蓝图和模板 ,而对象是类的示例 。
举个例子 :描述就是一个类 ,而猫就是对象 。
类的定义
通过class关键字 进行类的定义
语法格式 :
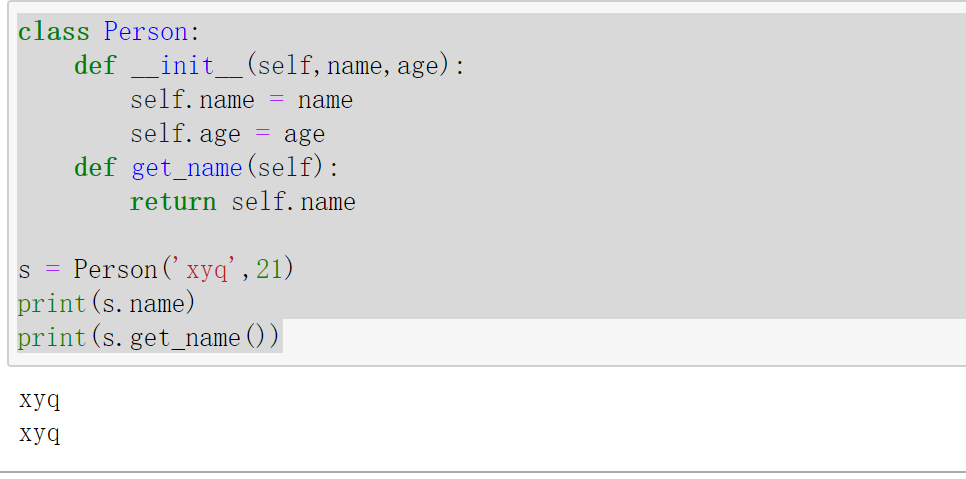
代码实例 :
1 2 3 4 5 6 7 8 9 10 class Person : def __init__ (self,name,age ): self.name = name self.age = age def get_name (self ): return self.name s = Person('xyq' ,21 ) print (s.name)print (s.get_name())
结果演示 :
主要部分介绍 :self参数:self不是关键字 ,而是一个约定俗成的定名。其实这个self就是对象本身 。
2、__init__方法:初始化 。也就是对上代码中的name,age赋初值 。
7.1.2 访问可见性
引入介绍:
面向对象的三大特征 :封装、继承、多态。访问可见性 就是封装的一种体现。所谓封装,就是将私有部分放在里面,不让别人去看,而公有部分可以直接进行访问。
具体介绍:
先看两个定义 :
私有属性:类方法 可以访问,对象 不可直接访问。以两个下划线开头进行标识。
公有属性:可以直接进行访问。
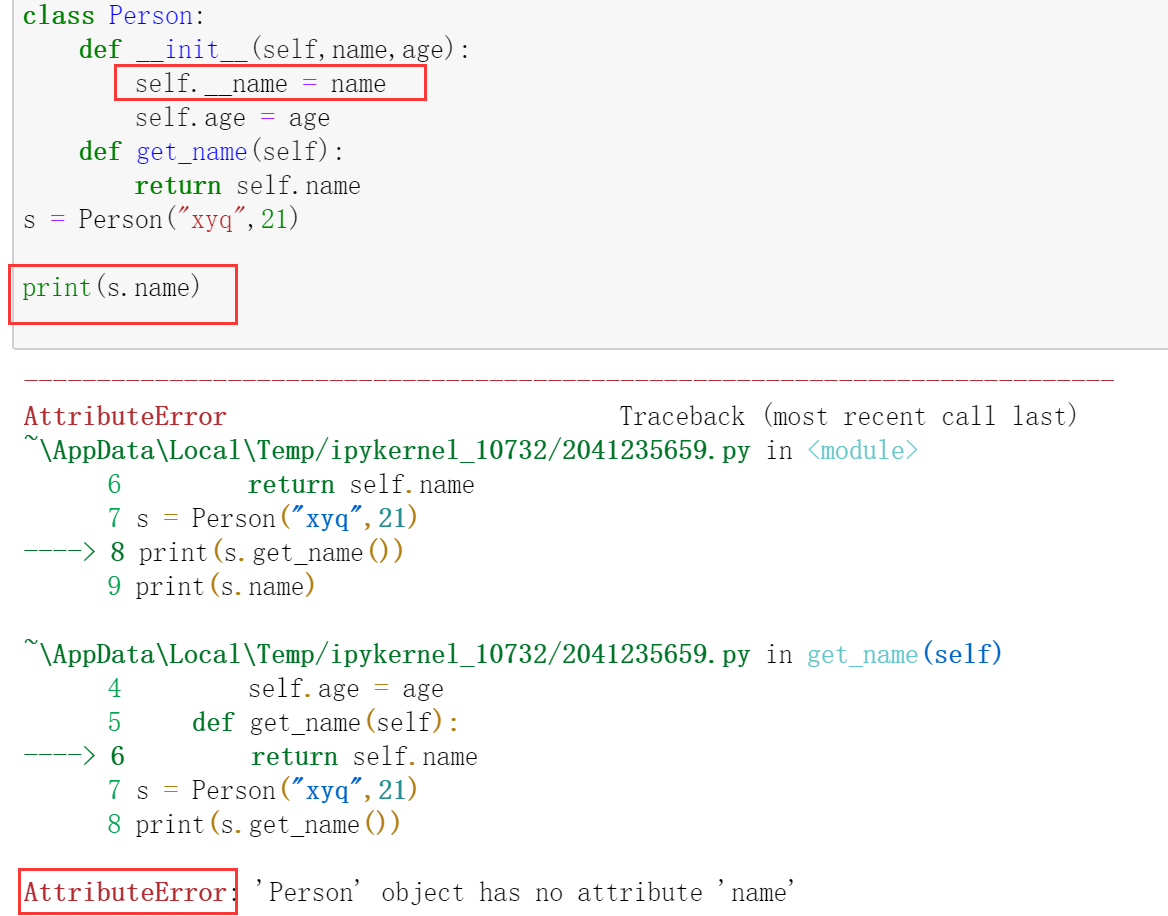
来看一个例子 :
在上例子里,我们将name属性进行了变化,将其变成私有属性 ,则在外部直接使用对象就无法访问 这个属性。print(s.get_name())可以进行访问,这是因为get_name是类里定义 的方法,可以访问私有属性。
再进一步:如何访问私有属性呢?
答案上面已经给出了:在类中定义特定的方法,进行私有属性的访问。
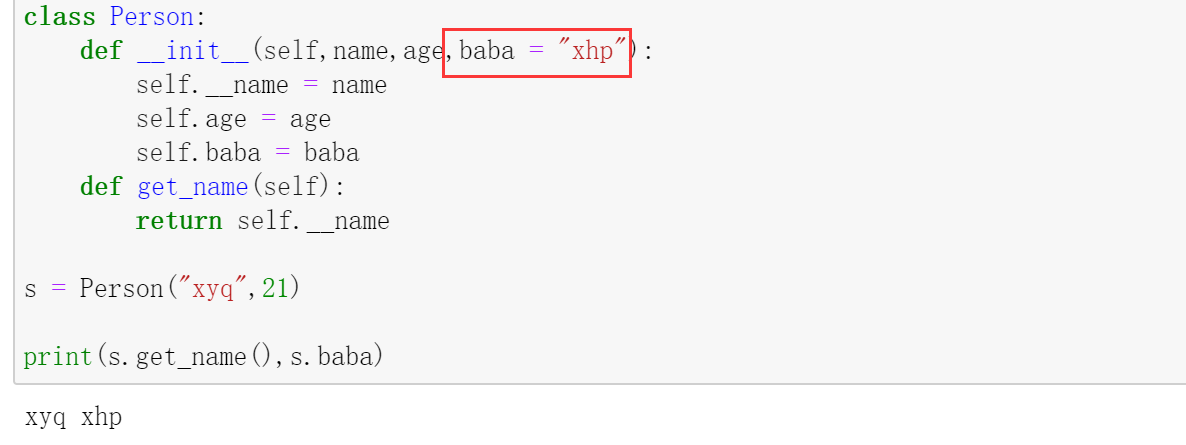
1 2 3 4 5 6 7 8 9 10 11 12 13 class Person : def __init__ (self,name,age ): self.__name = name self.age = age def get_name (self ): return self.__name def set_name (self,name1 ): if len (name1)>2 : self.__name = name1 s = Person("xyq" ,21 ) s.set_name("xyz" ) print (s.get_name())
运行结果 :
我们在类中定义了一个新的方法:set_name(self,name1),其中self为对象本身 ,用于对私有属性进行访问,name1是传递的参数 。
注意点 :外部调用类方法 需要加上对象名前缀 ,内部方法访问属性 ,需要加上self前缀 。
7.1.3 类属性和实例属性
定义引入:
类属性:存储与类空间,所有实例对象共有的。
实例属性:存储在实例空间,是单个实例对象独有的。
注 :实例对象和类有各自独立的存储空间。但是优先级:实例空间>类空间>基类空间。
具体示例:
注意点 :__init__函数里定义的属性为实例属性 ,因为是根据传递的参数来进行赋值的。单独占有空间 ;而实例是一个个通过模具制成的物品,这些物品也是有单独的存储空间 。
7.2 方法
先来思维导图:
7.2.1 构造方法和析构方法
定义引入:
构造方法:即__init__方法,负责对象的初始化 ,也就是对象状态的更新和属性的设置,无返回值 。
析构方法:即__del__方法,负责对象的回收 和内存空间的释放 。
先来构造方法:__init__
这个方法是python的内置特殊方法 。这个方法使用时需要注意以下几点 :
名字不可变,需为init。
不可以有返回值。
只会调用一次,进行对象的初始化
本质 :就是一个函数 ,通过传递的参数实现对实例属性的赋值。(函数的参数相关内容 可以适用)
关键字参数 ,将传递的参数封装为一个字典 。通过kw.get(key)进行属性的赋值。
再来看一下析构函数:__del__
这个函数是程序自动执行的 ,不需要定义。其作用就是当程序结束后将对象的空间进行销毁 。del 对象名删除一个实例时,也是使用了析构函数。
注 :当一个对象被引用时 ,使用del不会销毁此对象的存储空间。
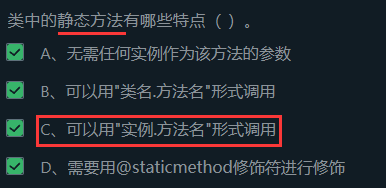
7.2.2 类方法和静态方法
定义引入:
静态方法:即传递的参数与某个对象实例无关 ,通过类名.静态方法(参数...)即可进行调用,不需要对象前缀 。
类方法:在对象初始化之前 进行的方法,是对当前类相关信息的获取。通过对象1 = 类名.类方法()进行对象的获取和初始化。
先来看静态方法:
语法格式 :在函数定义上方使用修饰符 @staticmethod进行标识,而后进行方法的定义。
代码实例 :(三角形验证)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Sanjiao (): def __init__ (self,a,b,c ): self.a = a self.b = b self.c = c @staticmethod def Pand (a,b,c ): return a+b >c and b+c > a and a+c > b [219 :0 ]行数:220 长度:4096 def Get_c (self ): return self.a+self.b+self.c if Sanjiao.Pand(1 ,4 ,4 ): s = Sanjiao(1 ,4 ,4 ) print (s.Get_c()) else : print ("wrong !" )
在上面的代码里,使用到了静态方法,其作用就是在对象建立之前 调用此方法判断数据是否合格。
再来看一下类方法
语法格式 :@classmethod进行标识cls对象名 = 类名.类方法(参数)的方法进行对象的创建。(对象建立时的参数与正常建立时一样,不受类方法的影响)
7.2.2 @property装饰器 作用 :将一个属性 变成方法 进行调用
语法格式 :以@property 进行标识,以属性名作为方法名 进行定义,以对象.方法名=xx进行调用
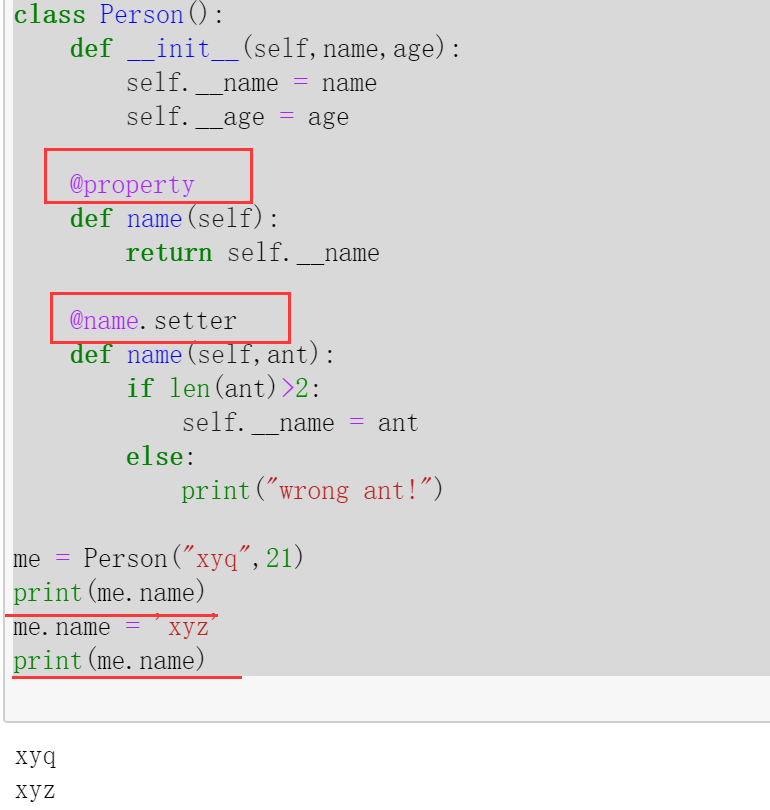
来看一个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Person (): def __init__ (self,name,age ): self.__name = name self.__age = age @property def name (self ): return self.__name @name.setter def name (self,ant ): if len (ant)>2 : self.__name = ant else : print ("wrong ant!" ) me = Person("xyq" ,21 ) print (me.name)me.name = 'xyz' print (me.name)
运行结果 :
注释 :@perproty将name方法定义为了一个属性 ,其作用就是返回__name的值,可以用于获取值 ;@name.setter进行修饰,其作用就是可以通过访问属性的形式进行属性的赋值 。保证程序的健壮性 。
7.3 继承和多态
先放思维导图:
7.3.1 继承
定义引入:
继承的目的是为了实现已有类的扩充 。
父类(基类):被继承的类。
子类(派生类):创建的新的类。
重写:类在继承父类已有的方法后,可以对父类已有的方法给出新的实现版本 ,此操作称为重写。特有的属性和方法 ,所以子类比父类拥有更多的功能 。
看一个例子:
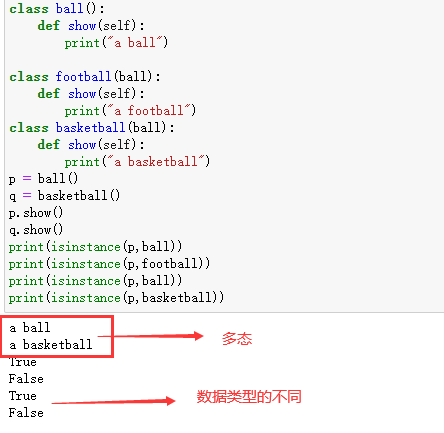
football继承了 ball类,并对ball类中的show方法 进行了重写 。
再看一个例子:
这里在子类中调用了父类的方法 ,其格式为:类名.方法名(self)。一般调用方法是不需要传递self,但是这里需要。
super()使用父类的构造方法
直接上图 :
在子类的构造方法里使用了父类的构造方法 ,其格式为:super().__init__(name),可以把super()看成是父类。父类.__init__(self,name)方法也可以进行调用,不过需要显式的 传递self参数。
7.3.2 MixIn–混入功能
定义介绍:
Mixin :通常是实现某种功能的类 ,用于被其他子类继承,扩充子类的功能。
具体例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class repMixin (): def __repr__ (self ): return ("[%s,%s]" %(self.name,self.age)) class get_set_Mixin (): def __getitem__ (self,key ): return self.__dict__.get(key) def __setitem__ (self,key ): return self.__dict__.set (key,value) class person (repMixin,get_set_Mixin ): def __init__ (self,name,age ): self.name = name self.age = age me = person("xyq" ,21 ) print (me)print (me['name' ],me['age' ])
结果 :
如上例子,person子类继承了两个混合类 ,从而在输出时实现了多种功能。
关于混合类的一个提醒:
Mixin混合类自身不能实例化 ,仅可用于被子类继承。
Mixin实现的功能是通用的,单一的,按需继承 。
Mixin只能用于扩展子类 ,不能影响子类的主要功能 。如果对主要功能造成影响,就是基类了,不要使用Mixin命名。
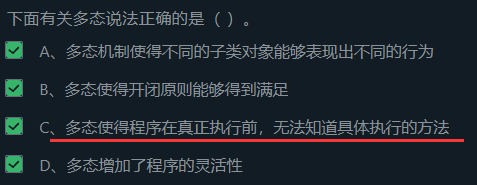
7.3.3 多态
概念引入:
何为多态 ?我们前面介绍了方法的重写,即在子类中对父类的方法进行重新编写,使得不同的子类对象表现出不同的行为 ,这就是多态。
看一个例子 :
上例就是多态 的一个体现。子类的数据类型与父类相同 ,但是父类对应的对象的数据类型与其子类对应的对象的数据类型不同 。
开闭原则
开:对扩展开放 ,即允许新增ball的子类
闭:对修改封闭 ,即不需要对ball类做修改就可实现不同的形式。
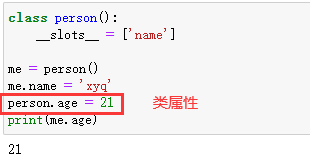
7.4 动态属性和slots 一个例子 :
__slots__是一个特殊的变量 ,可以看作一个卡槽 ,只有在这个卡槽里的属性才可以进行添加 。
Tips :slots只是限制了实例属性,对类属性 不进行限制。
7.5 定制类
老规矩,先上思维导图
7.5.1 python中的特殊方法 在python里,有些方法前后都添加了下划线 ,这些方法就是特殊方法 。我们可以对特殊方法进行重写,扩展类的功能。
下面我们就介绍一些常用的特殊方法:
1、__str__方法和__repr__方法
使得输出的格式更加好看。
先来介绍一些上面的两个方法 :
__str__方法:当我们使用print(对象1)时调用的就是这个方法。输出用户看到的字符串。__repr__方法:当我们直接使用对象1时,调用的是这个方法。输出程序开发人员看到的字符串。
所以我们可以对上方法进行重写 ,输出想要的格式。
也可以使用__repr__ = __str__简化
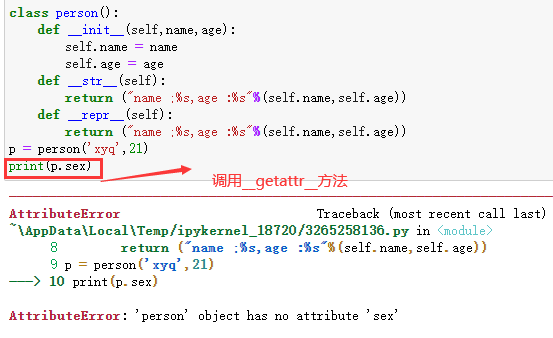
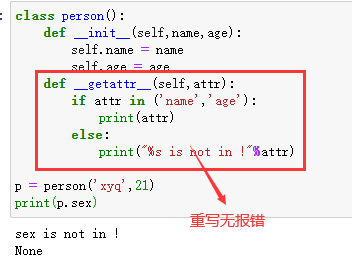
2、__getattr__方法
这个方法的作用就是获取某一个属性的值。也就是对象.属性
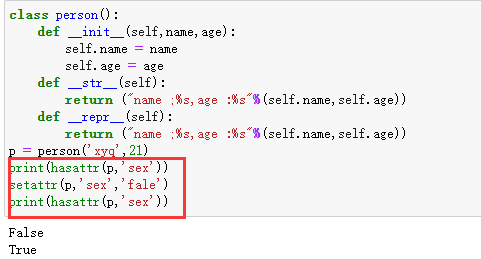
与这个方法类似 的还有:
__hasattr__:判断 是否有某属性__setattr__:修改 一个属性
所以我们可以重写这个方法把报错去掉 :
最后输出的None 是因为此方法有默认的返回值 。
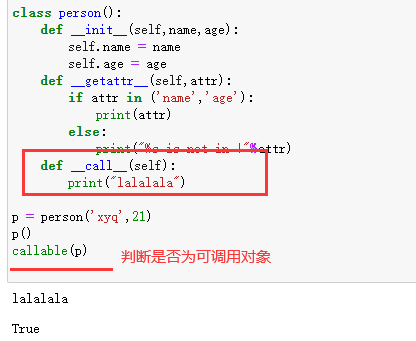
3、__call__方法
这个方法的作用是将一个对象变为可调用对象
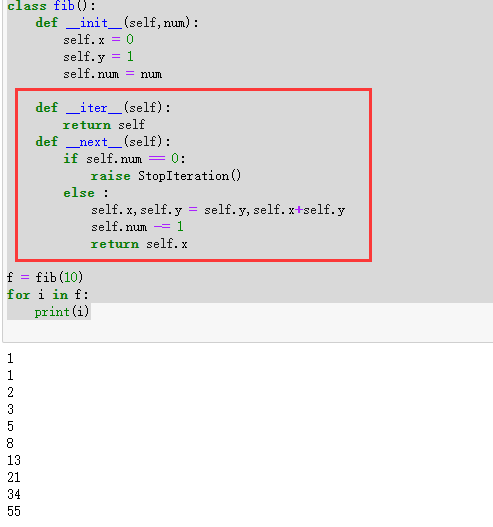
4、迭代器对象
所谓的迭代器,就是满足__iter__方法和__next__方法的对象。所以我们要将一个对象变成迭代器,就要重写这两个方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class fib (): def __init__ (self,num ): self.x = 0 self.y = 1 self.num = num def __iter__ (self ): return self def __next__ (self ): if self.num == 0 : raise StopIteration() else : self.x,self.y = self.y,self.x+self.y self.num -= 1 return self.x f = fib(10 ) for i in f: print (i)
结果 :
重写这两个方法后就对象就变成了迭代器 ,使用next的输出方法。
5、其他特殊方法
见链接:https://docs.python.org/zh-cn/3.8/reference/datamodel.html#special-method-names
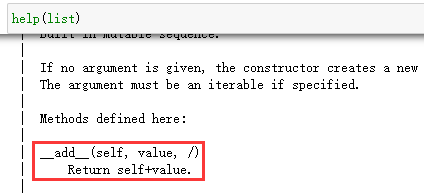
7.5.2 重载运算符 运算符的本质就是第一个操作数所在的命名空间的特殊方法。例如:
加法运算符就是上图所示的一个方法。
上例就是在int()这个命名空间 里调用了__add__方法。
7.6 综合实例:有理数类的实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 class Fraction (): def __init__ (self, high=0 , down=1 ): """ 一个初始化函数。我们需要实现有理数的判别与化简。 """ if down == 0 : raise ZeroDivisionError("down cannot be 0!" ) if high == 0 : self._high = 0 self._down = 1 else : if (high > 0 and down < 0 ) or (high < 0 and down > 0 ): flag = -1 else : flag = 1 a = abs (high) b = abs (down) while a % b != 0 : ta = a tb = b a = tb b = ta % tb self._high = abs (high) // b * flag self._down = abs (down) // b def __add__ (self, other ): high1 = (self._high * other._down) + (self._down * other._high) down1 = self._down * other._down return Fraction(high1, down1) def __sub__ (self, other ): high1 = (self._high * other._down) - (self._down * other._high) down1 = self._down * other._down return Fraction(high1, down1) def __eq__ (self, other ): return (self._high == other._high and self._down == other._down) def __lt__ (self, other ): return (self._high * other._down < self._down * other._high) def __repr__ (self ): return (str (self._high) + '/' + str (self._down)) a = int (input ()) b = int (input ()) frac1 = Fraction(a, b) print (frac1)c = int (input ()) d = int (input ()) frac2 = Fraction(c, d) print (frac1 < frac2)print (frac1 == frac2)res_add = frac1 + frac2 res_sub = frac1 - frac2 print (res_add)print (res_sub)
注意点 :化简 要理清原理。运算需要在类里进行定义 。(具体的原理在上小节)
7.7 练习补充
内容来自实训和测试
测试部分 1、__init__方法
2、多态辨析
3、静态方法
4、类方法
5、析构函数的调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Register : def __init__ (self, **kwargs ): self._age = kwargs.get('age' ) self._name = kwargs.get('name' ) self._sex = kwargs.get('sex' ) def get_age_value (self ): return self._age def get_name_value (self ): return self._name def get_sex_value (se1f ) : return self._sex def __del__ (self ): print ('调用了一次析构函数' ) def main (): wang = Register(age = 8 , name='wang' , sex='male' ) WANG = wang del wang if __name__ == '__main__' : main()
只是调用一个析构函数。
6、Mixin混合类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class ReprMixin : def __repr__ (self ): return '[%s, %s, %s]' %(self.name, self.gender, self.age) class MappingMixin : def __getitem__ (self, key ): return self.__dict__.get(key) def __setitem__ (self, key, value ): return self.__dict__.set (key, value) class Teacher (ReprMixin ): def __init__ (self, name, gender, age, **kwargs ): self.name = name self.gender = gender self.age = age self.zhicheng = kwargs.get('zhicheng' ) class Student (MappingMixin ): def __init__ (self, name, gender, age, **kwargs ): self.name = name self.gender = gender self.age = age self.num = kwargs.get('num' ) t = Teacher('教师甲' , 'female' , '48' , zhicheng = '副教授' ) s = Student('学生甲' , 'male' , '18' , num =20180019 ) print (t, s)
结果 :
原因 :
实训项目
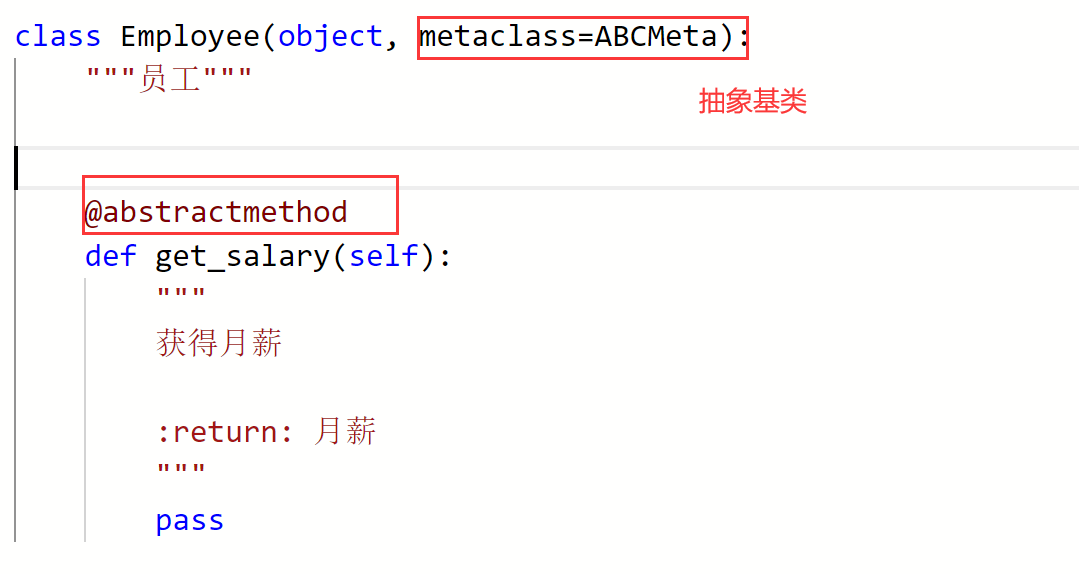
1、工资问题
from abc import ABCMeta, abstractmethod
上模块介绍见此
代码1 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 """ 某公司有三种类型的员工 分别是部门经理、程序员和销售员 需要设计一个工资结算系统 根据提供的员工信息来计算月薪 部门经理的月薪是每月固定15000元 程序员的月薪按本月工作时间计算 每小时150元 销售员的月薪是1200元的底薪加上销售额5%的提成 """ from abc import ABCMeta, abstractmethodclass Employee (object , metaclass=ABCMeta """员工""" def __init__ (self, name ): """ 初始化方法 :param name: 姓名 """ self._name = name @property def name (self ): '''返回姓名''' return self._name @abstractmethod def get_salary (self ): """ 获得月薪 :return: 月薪 """ pass class Manager (Employee ): """部门经理""" def get_salary (self ): return 15000.0 class Programmer (Employee ): """程序员""" def __init__ (self, name, working_hour=0 ): """ 初始化方法 :param name: 姓名 :param working_hour:工作时长 """ super ().__init__(name) self._working_hour = working_hour @property def working_hour (self ): '''返回工作时长''' return self._working_hour @working_hour.setter def working_hour (self, working_hour ): ''' 设置工作时长 :param working_hour:工作时长 ''' self._working_hour = working_hour if working_hour > 0 else 0 def get_salary (self ): '''返回程序员所得工资''' return 150.0 *self._working_hour class Salesman (Employee ): """销售员""" def __init__ (self, name, sales=0 ): """ 初始化方法 :param name: 姓名 :param sales:销售额 """ super ().__init__(name) self._sales = sales @property def sales (self ): '''返回销售额''' return self._sales @sales.setter def sales (self, sales ): ''' 设置销售额 :param sales:销售额 ''' self._sales = sales if sales>0 else 0 def get_salary (self ): '''返回销售员所得工资''' return 1200 +0.05 *self._sales
代码2 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from main import *from abc import ABCMeta, abstractmethoddef main (): emps = [ Manager('刘备' ), Programmer('诸葛亮' ), Manager('曹操' ), Salesman('荀彧' ), Salesman('吕布' ), Programmer('张辽' ), Programmer('赵云' ) ] for emp in emps: if isinstance (emp, Programmer): emp.working_hour = 7 elif isinstance (emp, Salesman): emp.sales = 100 print ('%s本月工资为: ¥%s元' % (emp.name, emp.get_salary())) if __name__ == '__main__' : main()
结果 :
注意点: 抽象基类 的使用from abc import ABCMeta, abstractmethod导入模块。
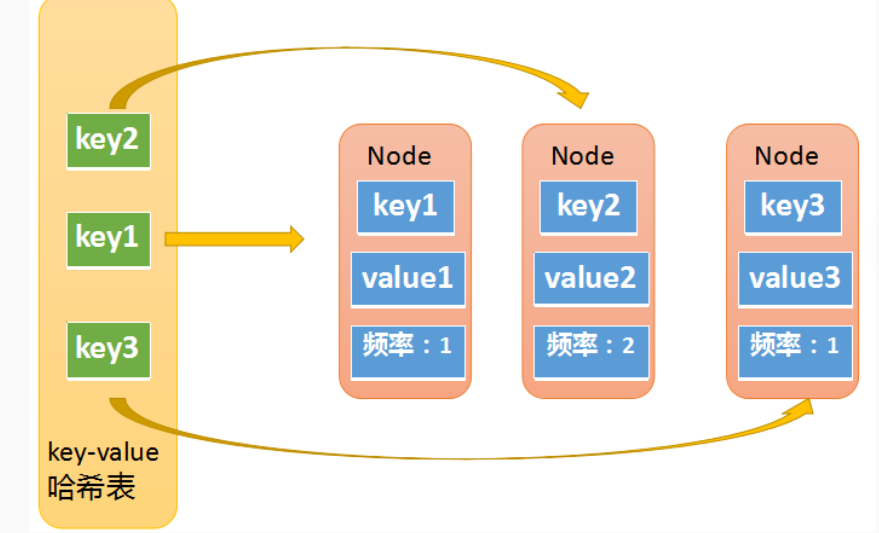
2、设计LFU缓存类
题目介绍:
LFU缓存的实现:LFU(Least Frequently Used)是根据频率维度来选择将要淘汰的元素,即删除访问频率最低的元素。如果两个元素的访问频率相同,则淘汰最久没被访问的元素。那么LFU淘汰的时候会选择两个维度,先比较频率,选择访问频率最小的元素;如果频率相同,则按时间维度淘汰掉最久远的那个元素。
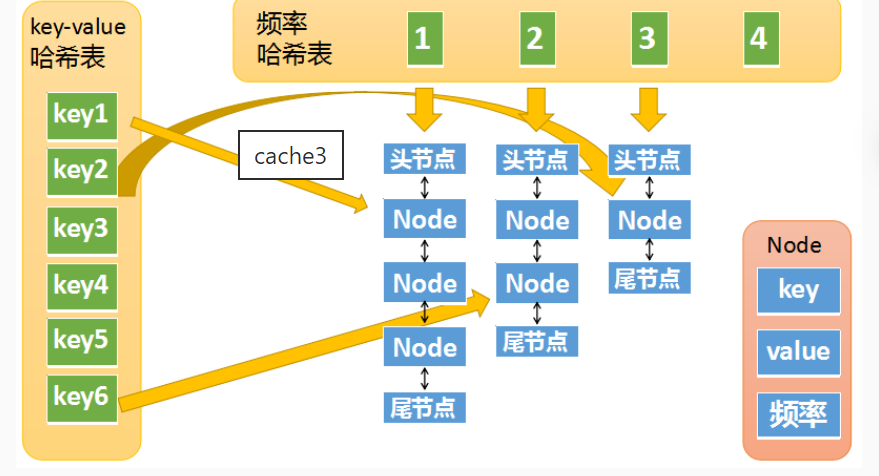
因此,LFU可以通过两个哈希表再加上多个双链表来实现:
第二张哈希表是频率哈希表,如下图所示。这张哈希表中的key是频率,也就是元素被访问的频率(被访问了1次,被访问了两次等),它的value是一个双向链表,图一中的Node对象,在图二中同样存在,图二中的Node其实是双向链表中的一个节点。图一中的Node对象中包含了一个冗余的key,其实它还包含了一个冗余的频率值,因为某些情况下,我们需要通过Node对象中的频率值,去频率哈希表中做查找,所以也需要一个冗余的频率值。
因此,我们将两个哈希表整合可以发现,整个完整的LFU cache结构如下图所示。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 from operator import methodcallerclass Node (object """ 双链表中的链表节点对象 """ def __init__ (self, key=None , value=None , freq=0 ): """ Args: key:对应输入的key value:对应输入的value freq:被访问的频率 pre:指向前一个节点的指针 next:指向后一个节点的指针 """ self.key = key self.value = value self.freq = freq self.pre = None self.next = None class LinkedList (object """ 自定义的双向链表 """ def __init__ (self ): """ Args: __head:双向链表的头结点 __tail:双向链表的尾节点 """ self.__head = Node() self.__tail = Node() self.__head.next = self.__tail self.__tail.pre = self.__head def insertFirst (self, node ): """ 将指定的节点插入到链表的第一个位置 Args: node:将要插入的节点 """ node.next = self.__head.next self.__head.next .pre = node self.__head.next = node node.pre = self.__head def delete (self, node ): """ 从链表中删除指定的节点 Args: node:将要删除的节点 """ if self.__head.next == self.__tail: return node.pre.next = node.next node.next .pre = node.pre node.next = None node.pre = None def getLast (self ): """ 从链表中获取最后一个节点 Returns: 双向链表中的最后一个节点,如果是空链表则返回None """ if self.__head.next == self.__tail: return None return self.__tail.pre def isEmpty (self ): """ 判断链表是否为空,除了head和tail没有其他节点即为空链表 Returns: 链表不空返回True,否则返回False """ return self.__head.next == self.__tail class LFUCache (object """ 自定义的LFU缓存 """ def __init__ (self, capacity ): """ Args: __capacity:缓存的最大容量 __keyMap: key->Node 这种结构的字典 __freqMap:freq->LinkedList 这种结构的字典 __minFreq:记录缓存中最低频率 """ self.__capacity = capacity self.__keyMap = dict () self.__freqMap = dict () self.__minFreq = 0 def get (self, key ): """ 获取一个元素,如果key不存在则返回-1,否则返回对应的value 同时更新被访问元素的频率 Args: key:要查找的关键字 Returns: 如果没找到则返回-1,否则返回对应的value """ if key not in self.__keyMap: return -1 else : o_node = self.__keyMap.get(key) self.__increment(o_node) return o_node.value def put (self, key, value ): """ 插入指定的key和value,如果key存在则更新value,同时更新频率 如果key不存并且缓存满了,则删除频率最低的元素,并插入新元素 否则,直接插入新元素 Args: key:要插入的关键字 value:要插入的值 """ if key in self.__keyMap: o_node = self.__keyMap.get(key) o_node.value = value self.__increment(o_node) self.__deleteNode(o_node) else : if len (self.__keyMap.keys())==self.__capacity: self.__removeMinFreqElement() n_node=Node(key, value,freq=1 ) self.__keyMap[key] = n_node self.__increment(n_node,is_new_node=True ) else : n_node = Node(key, value, freq=1 ) self.__keyMap[key] = n_node self.__increment(n_node, is_new_node=True ) def __increment (self, node, is_new_node=False ): """ 更新节点的访问频率 Args: node:要更新的节点 is_new_node:是否是新节点,新插入的节点和非新插入节点更新逻辑不同 """ if is_new_node: self.__minFreq = 1 self.__setDefaultLinkedList(node) else : self.__deleteNode(node) node.freq += 1 self.__setDefaultLinkedList(node) if self.__minFreq not in self.__freqMap: self.__minFreq += 1 def __setDefaultLinkedList (self, node ): """ 根据节点的频率,插入到对应的LinkedList中,如果LinkedList不存在则创建 Args: node:将要插入到LinkedList的节点 """ if node.freq not in self.__freqMap: self.__freqMap[node.freq] = LinkedList() linkedList = self.__freqMap[node.freq] linkedList.insertFirst(node) def __deleteNode (self, node ): """ 删除指定的节点,如果节点删除后,对应的双链表为空,则从__freqMap中删除这个链表 Args: node:将要删除的节点 """ if node.freq not in self.__freqMap: return linkedList = self.__freqMap[node.freq] freq = node.freq linkedList.delete(node) if linkedList.isEmpty(): del self.__freqMap[freq] def __removeMinFreqElement (self ): """ 删除频率最低的元素,从__freqMap和__keyMap中都要删除这个节点, 如果节点删除后对应的链表为空,则要从__freqMap中删除这个链表 """ linkedList = self.__freqMap[self.__minFreq] node = linkedList.getLast() linkedList.delete(node) del self.__keyMap[node.key] if linkedList.isEmpty(): del self.__freqMap[node.freq] if __name__ == '__main__' : operation = eval (input ()) data = eval (input ()) cache = eval ("{}({})" .format (operation.pop(0 ), data.pop(0 )[0 ])) output = [] for i, j in zip (operation, data): if i == 'put' : methodcaller('put' , j[0 ], j[1 ])(cache) output.append(None ) elif i == 'get' : output.append(methodcaller('get' , j[0 ])(cache)) print (output)
注意点分析 :from operator import methodcaller的使用
2、 cache = eval("{}({})".format(operation.pop(0), data.pop(0)[0]))的初始化
3、get时需要在keyMap提取到对应的节点,而后查看其值。同时注意__increment方法包含了节点的删除与插入,不需要再删除一次。
4、put时,需要新建一个节点(频率赋值为1 ),并把节点放到表里。