TensorFlow笔记--ch5 卷积神经网络
写在前面
由于种种原因,关于本章的部分内容不会很详细,旨在了解大体过程,为下面的循环神经网络的重点学习做铺垫。
卷积计算过程
全连接神经网络回顾
全连接NN:每个神经元与前后相邻层的每一个神经元都有连接关系,输入是特征,输出为预测的结果
以MNIST数据集为例:
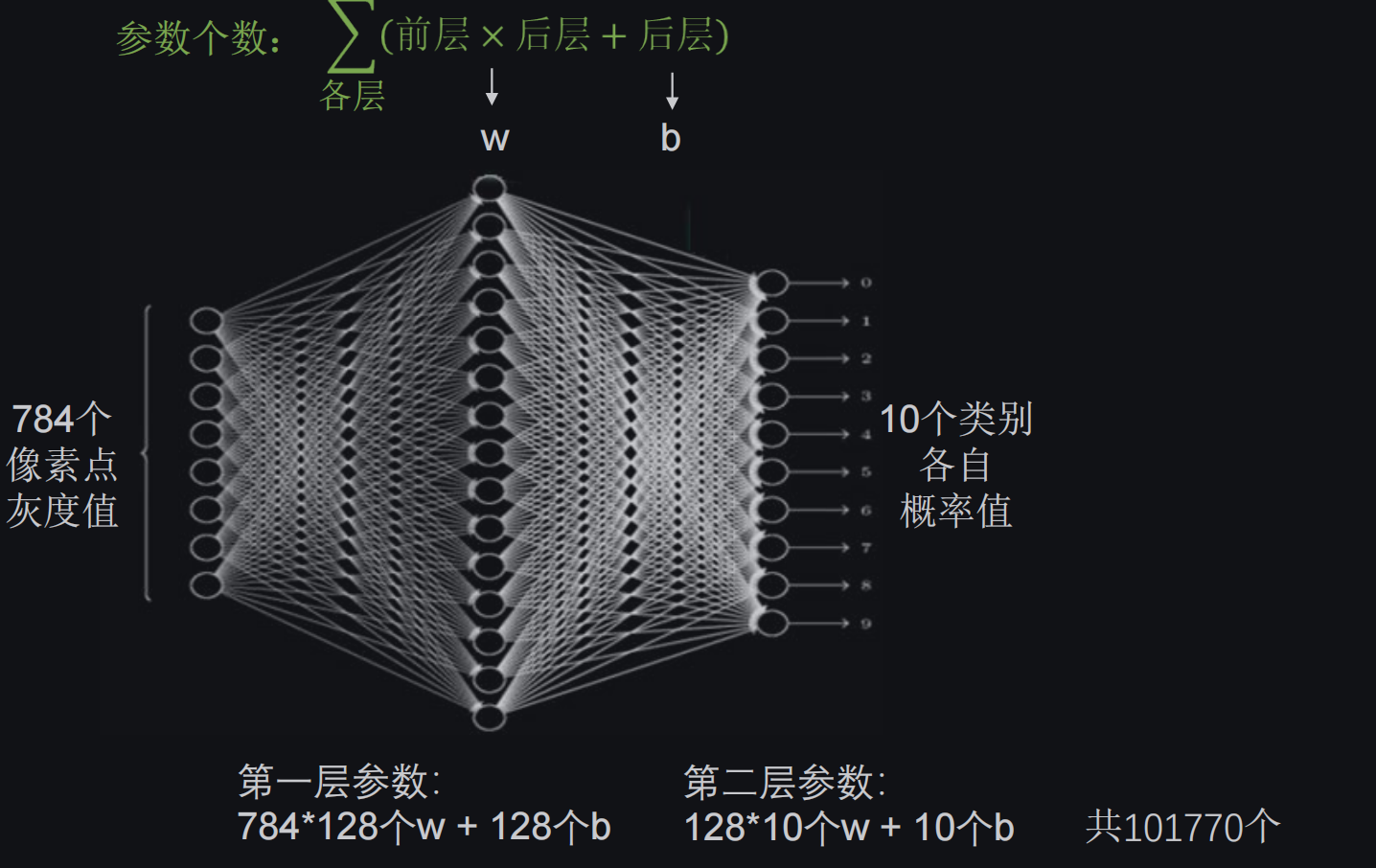
仅仅是输入黑白灰度值数据就有10万多个待优化参数,我们在实际项目中多是高分辨率彩色图,待优化的参数会更多,很容易造成过拟合。
如下是图像对比:

特征提取
实际应用时会先对原始图像进行特征提取再把提取到的特征送给全连接网络
下图是过程实例:
卷积计算可认为是一种有效提取图像特征的方法
一般会用一个正方形的卷积核,按指定步长,在输入特征图上滑动,遍历输入特征图中的每个像素点。每一个步长,卷积核会与输入特征图出现重合区域,重合区域对应元素相乘、求和再加上偏置项得到输出特征的一个像素点。
- 输入特征图的深度(channel数),决定了当前层卷积核的深度;
- 当前层卷积核的个数,决定了当前层输出特征图的深度。
下图是卷积计算过程:
经过卷积核的特征提取,我们的输入特征就会十分精简,利于优化,减少过拟合。
感受野(Receptive Field)
卷积神经网络各输出特征图中的每个像素点,在原始输入图片上映射区域的大小。
下图是感受野的示例:
可知,对于多次卷积核得到的输出特征图的感受野也是与最原始的特征图比较的。
同时通过图最下方的计算,可以知道对于x大于10的特征图,选择两层3x3的卷积核更好。
全零填充(Padding)
前面我们知道,在经过特征提取后的输出特征图的维度要比原始特征图小,如果不想改变特征图的维度,可以使用全零填充,即在原始特征图的一周添加0,再使用卷积核滑过。
下图是全零填充的示例: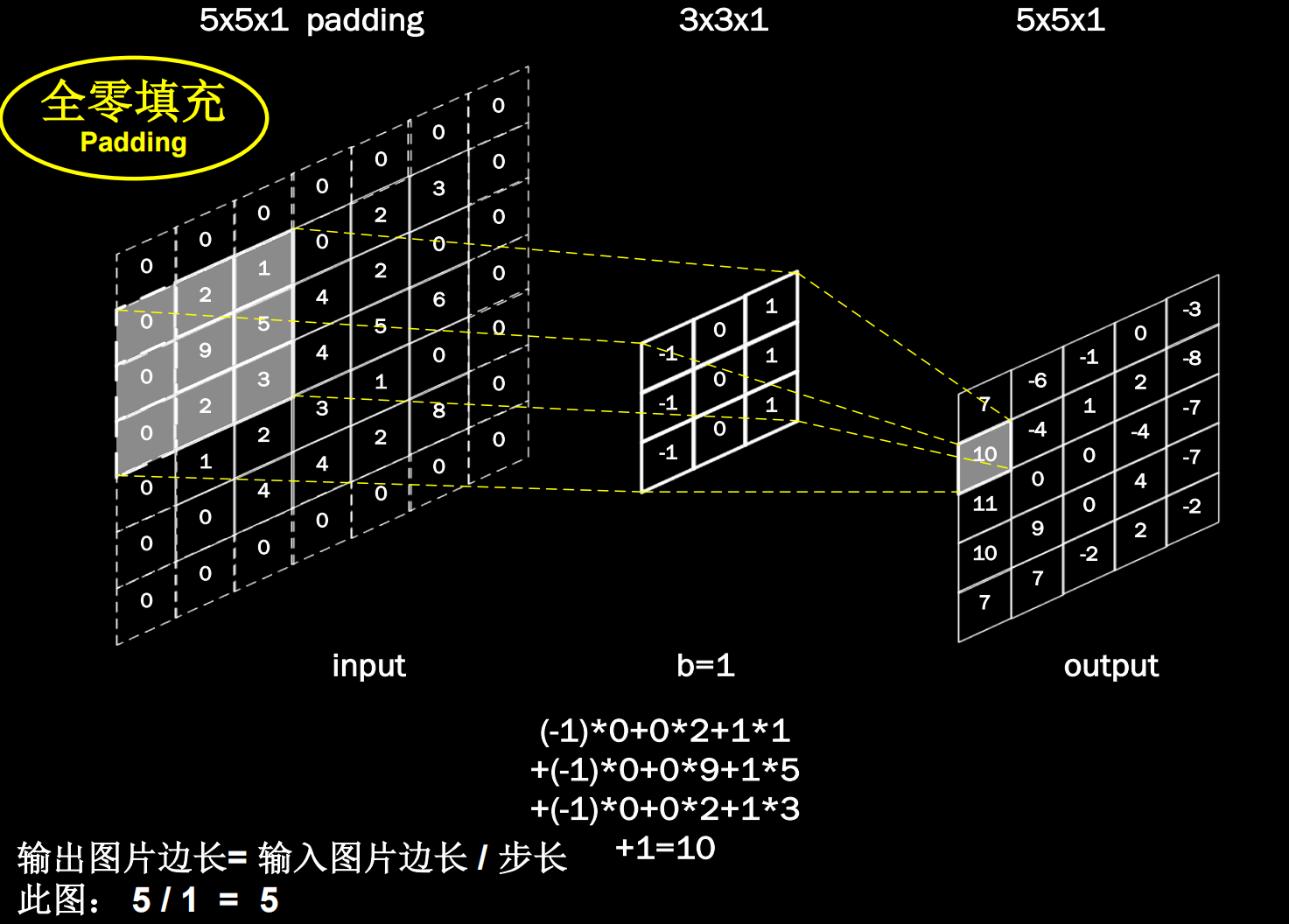
下面给出输出特征图的边长计算公式:
TensorFlow的使用:
- 用参数
padding=‘SAME’或padding=‘VALID’表示
下图给出了边长的计算过程: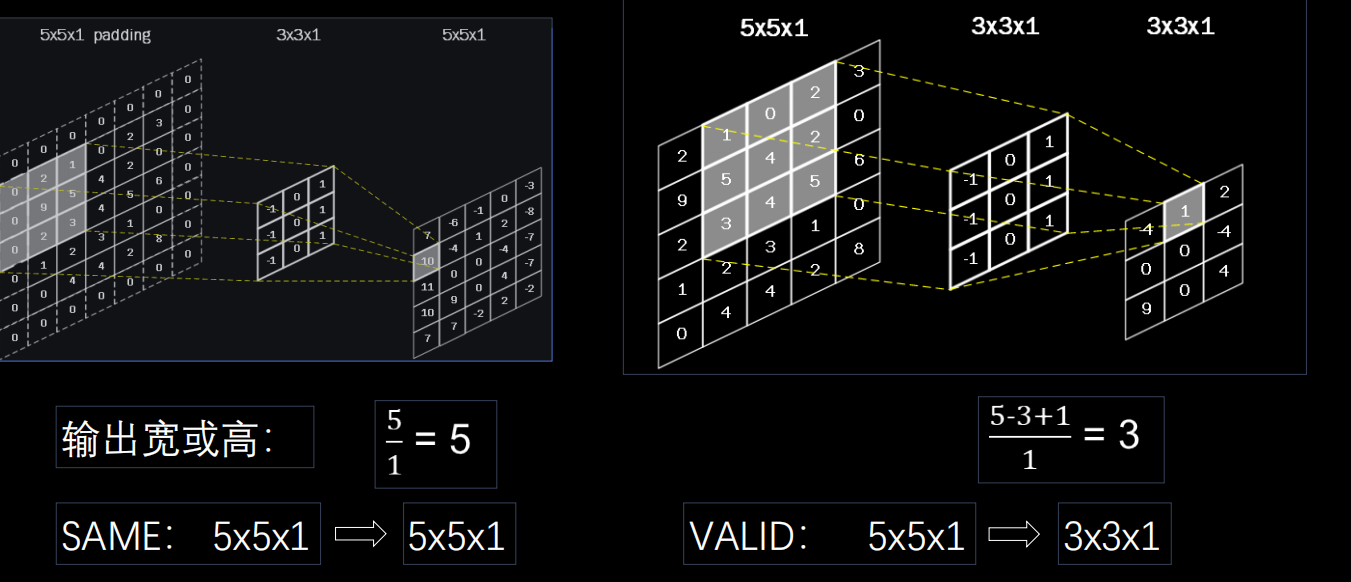
TF描述卷积层
前面我们已经了解了卷积神经网络的计算过程,下面我们就要使用TensorFlow实现上述计算过程,这个过程不需要复杂的底层运算,只需要我们给出需要的参数即可。
下面是定义卷积层的代码规范:
1 | tf.keras.layers.Conv2D ( |
上述代码为tf.keras.models.Sequential()的一部分,写在全连接层之前。
批标准化(Batch Normalization,BN)
神经网络对0附近的数据更加敏感,但是随着网络层数的增加,特征数据会出现偏离0均值的情况。这时候就需要进行标准化处理。
- 标准化:使数据符合0均值,1为标准差的分布。
- 批标准化:对一小批数据(batch),做标准化处理。
批标准化后,第k个卷积核的输出特征图(feature map)中第i个像素点: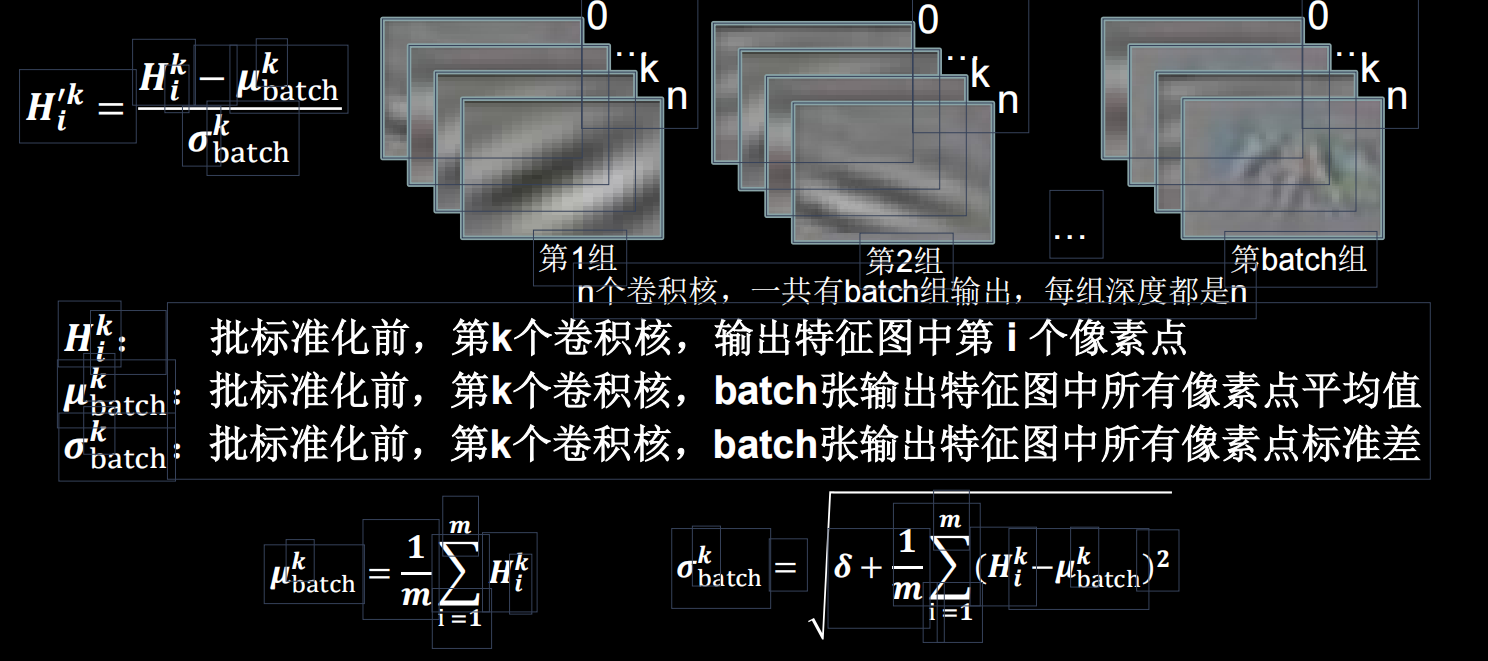
上图给出了标准化的计算公式,以一个batch为单位进行数据的处理,使得数据回归到0为均值的状态。
我们来看一下标准化过后的数据偏移情况: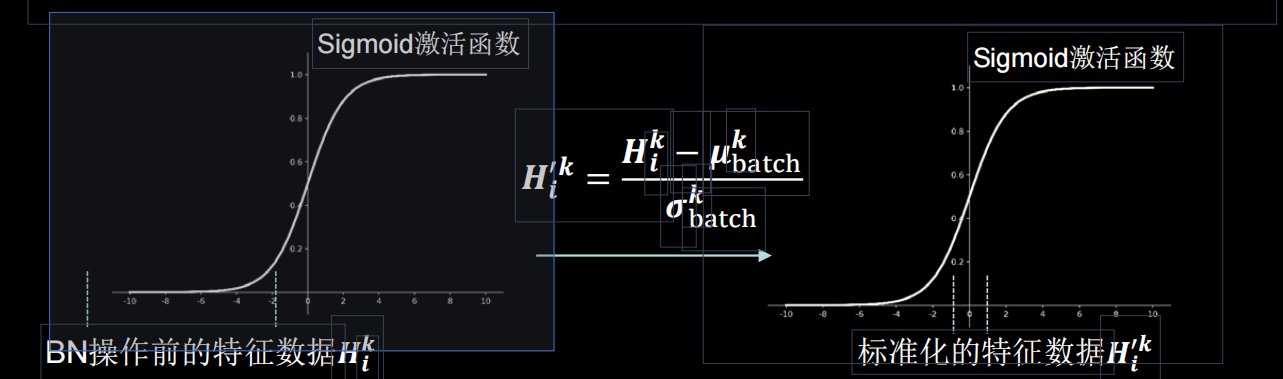
可见,经过标准化后的数据分布在计划函数的线性区,使得输入数据的微小变化更明显的体现到激活函数的输出,提升了激活函数对输入数据的区分力。
但是,上面那种简单的标准化处理使得数据完全满足正态分布,让数据分布在线性区,使得激活函数丧失了非线性特性,因此我们在BN操作上为每一个卷积核引入了两个可训练参数,这两个参数也是与其余参数一同优化,通过这两个参数实现数据的缩放和偏移,保证了网络的非线性表达力。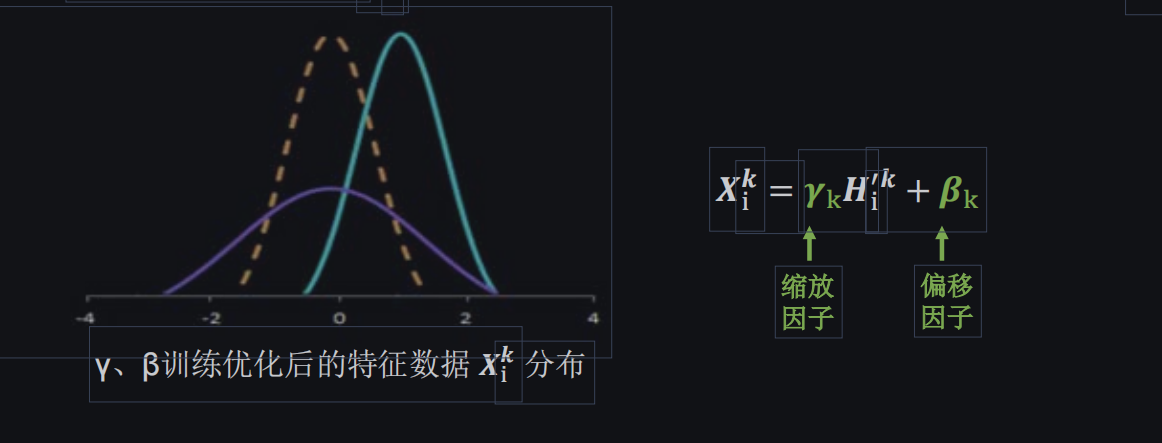
批标准化的代码实现:
批标准化位于卷积层和激活函数层之间,在TensorFlow中以下面的代码进行描述:
池化(Pooling)
所谓池化,就是通过池化核减少特征数量。
- 最大池化:MaxPool2D:提取图片纹理
- 均值池化:.AveragePooling2D:保留图片背景
下图给出了池化的过程:
可以看到,特征数据的数量变少了,同时二种池化方式的原理也很清楚。
池化的代码实现:
1 | tf.keras.layers.MaxPool2D( |
舍弃(Dropout)
在神经网络训练时,将一部分神经元按照一定概率从神经网络中暂时舍弃。神经网络使用时,被舍弃的神经元恢复链接。
下图给出了舍弃操作的示例: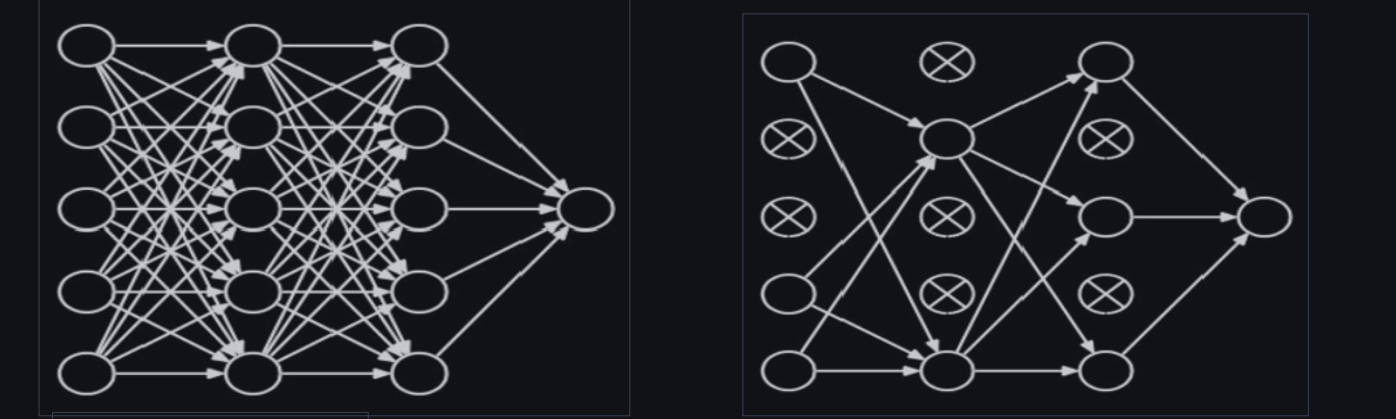
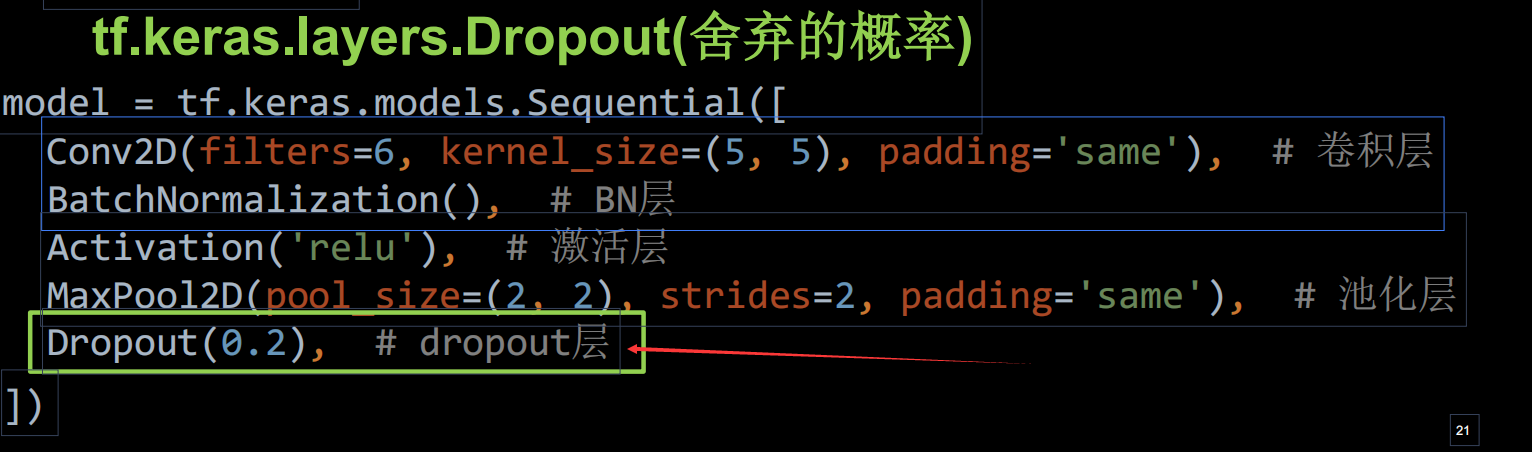
舍弃操作的代码实现:
卷积神经网络
经过上述内容的学习,我们已经对卷积神经网络有了清晰的认识,下面我们来回顾梳理一下。
卷积神经网络:借助卷积核提取特征后,送人全连接神经网络。
主要模块:
W:卷积是什么?
D:特征提取器,CBAPD.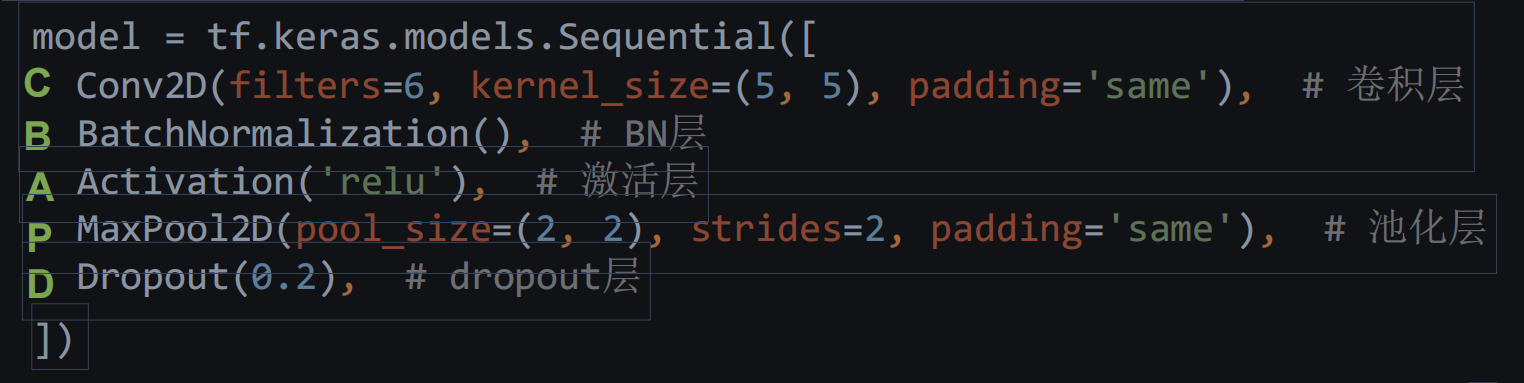
写在最后
关于卷积神经网络的部分内容就先到这里,课程内还要一些示例与扩展,这里先不进行。以后在系统学习机器学习时会再详细进行,并附上链接。
最后,再默念一句:特征提取器,CBAPD。





