前节回顾与本节扩展
在正式开始学习之前,我们先来整理一下大体框架,让我们对接下来要学习的知识有一个清晰认识。

上图标画的部分就是接下来要学习的部分,在上一节使用六步法搭建神经网络的基础上,与实际问题相结合,解决一系列问题,实现神经网络的深度优化。
本节目录:
- ①自制数据集,解决本领域应用
- ②数据增强,扩充数据集
- ③断点续训,存取模型
- ④参数提取,把参数存入文本
- ⑤acc/loss可视化,查看训练效果
- ⑥应用程序,给图识物
下面我们依次介绍。
自制数据集,解决本领域应用
观察数据集结果,形成特征标签对
一个完备的、可以用于神经网络训练的数据集必须包含特征、标签对。其中特征用于输入和计算结果,标签用于计算loss从而进行参数优化。
我们这里准备了一份数据集,接下来将使用一个示例演示如何导入尚未封装的数据集。
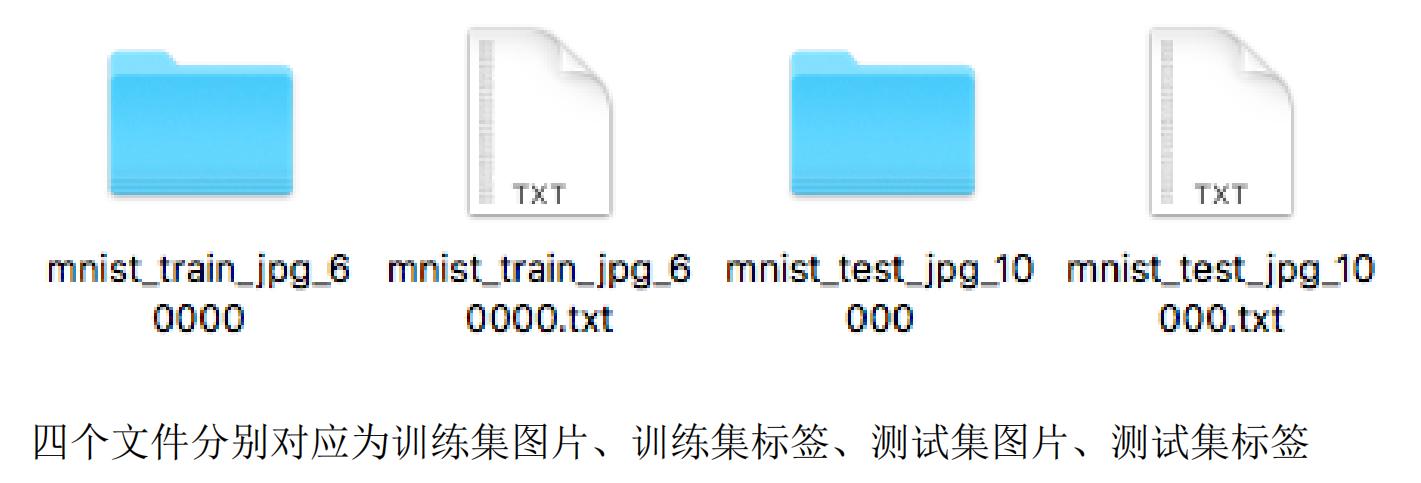
其实就是MNIST数据集,不过需要我们自己进行配对。
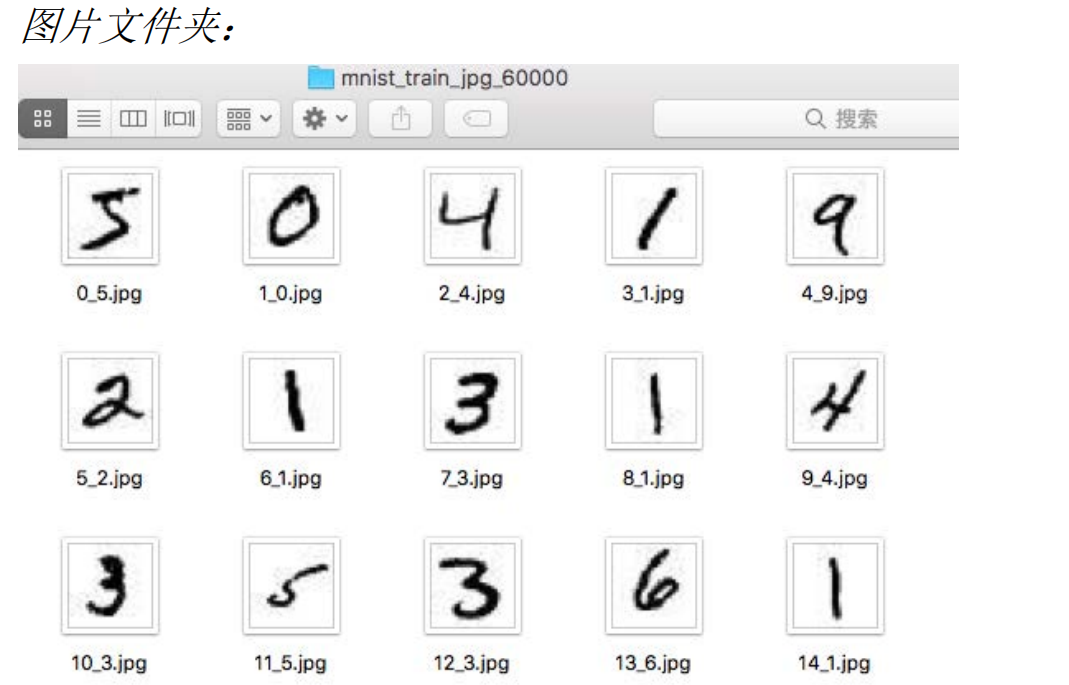
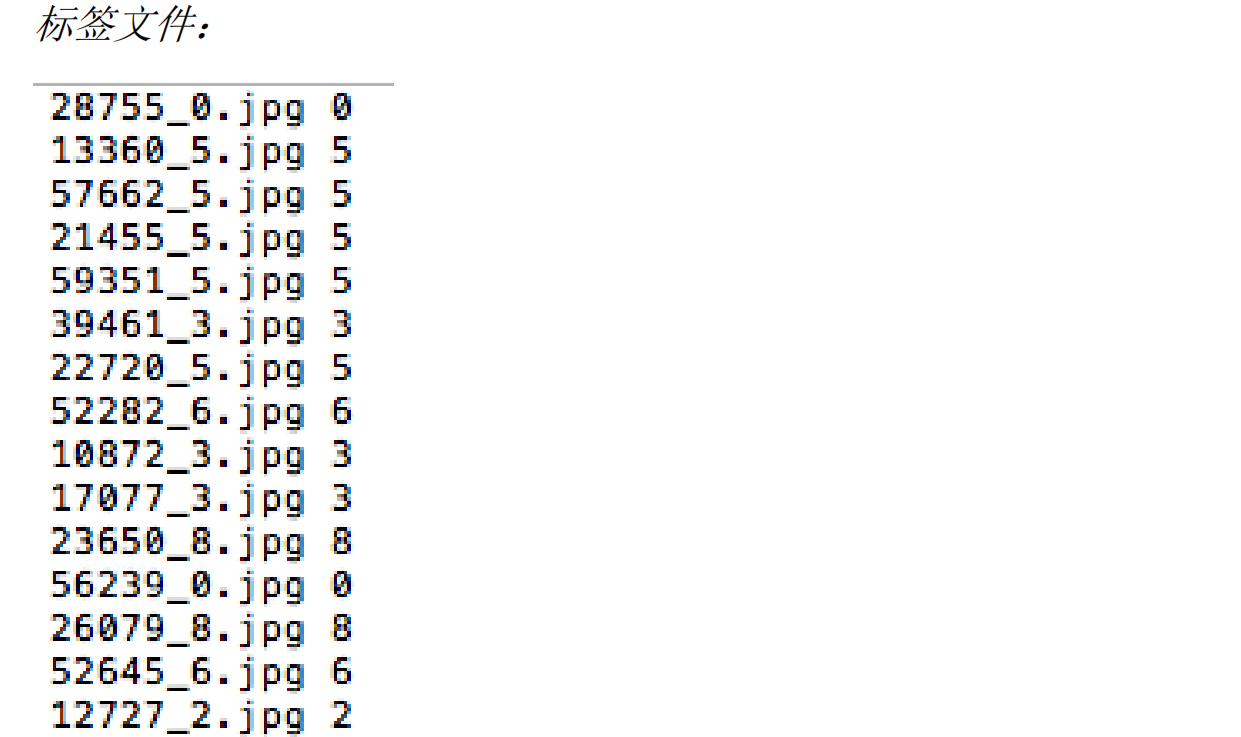
可见,x文件夹里是一张张图片,而y文件夹里是一行行数据对,将每一张图片与其表示的数字对应。
下面是导入代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
| import tensorflow as tf
from PIL import Image
import numpy as np
import os
train_path = './mnist_image_label/mnist_train_jpg_60000/'
train_txt = './mnist_image_label/mnist_train_jpg_60000.txt'
x_train_savepath = './mnist_image_label/mnist_x_train.npy'
y_train_savepath = './mnist_image_label/mnist_y_train.npy'
test_path = './mnist_image_label/mnist_test_jpg_10000/'
test_txt = './mnist_image_label/mnist_test_jpg_10000.txt'
x_test_savepath = './mnist_image_label/mnist_x_test.npy'
y_test_savepath = './mnist_image_label/mnist_y_test.npy'
def generateds(path, txt):
f = open(txt, 'r')
contents = f.readlines()
f.close()
x, y_ = [], []
for content in contents:
value = content.split()
img_path = path + value[0]
img = Image.open(img_path)
img = np.array(img.convert('L'))
img = img / 255.
x.append(img)
y_.append(value[1])
print('loading : ' + content)
x = np.array(x)
y_ = np.array(y_)
y_ = y_.astype(np.int64)
return x, y_
if os.path.exists(x_train_savepath) and os.path.exists(y_train_savepath) and os.path.exists(
x_test_savepath) and os.path.exists(y_test_savepath):
print('-------------Load Datasets-----------------')
x_train_save = np.load(x_train_savepath)
y_train = np.load(y_train_savepath)
x_test_save = np.load(x_test_savepath)
y_test = np.load(y_test_savepath)
x_train = np.reshape(x_train_save, (len(x_train_save), 28, 28))
x_test = np.reshape(x_test_save, (len(x_test_save), 28, 28))
else:
print('-------------Generate Datasets-----------------')
x_train, y_train = generateds(train_path, train_txt)
x_test, y_test = generateds(test_path, test_txt)
print('-------------Save Datasets-----------------')
x_train_save = np.reshape(x_train, (len(x_train), -1))
x_test_save = np.reshape(x_test, (len(x_test), -1))
np.save(x_train_savepath, x_train_save)
np.save(y_train_savepath, y_train)
np.save(x_test_savepath, x_test_save)
np.save(y_test_savepath, y_test)
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)
model.summary()
|
具体解释一下增加的部分代码:
导入模块部分:
1
2
3
4
| import tensorflow as tf
from PIL import Image
import numpy as np
import os
|
使用了以上四个模块。
- PIL是python的图像处理库,这里使用库里的Image类,进行图片的加载。
- os是“operating system”的缩写,提供的就是各种 Python 程序与操作系统进行交互的接口。这里使用的
os.path.exists()用于判断指向的文件是否存在。
- Numpy是python用于科学计算的基础软件包,这里主要用于文本的加载、保存和矩阵的转换。
注:在python学习模块会有专门的一个文章整理这些模块的用法,这里只需要知道使用到的函数的作用即可。
文件路径部分
1
2
3
4
5
6
7
8
9
| train_path = './mnist_image_label/mnist_train_jpg_60000/'
train_txt = './mnist_image_label/mnist_train_jpg_60000.txt'
x_train_savepath = './mnist_image_label/mnist_x_train.npy'
y_train_savepath = './mnist_image_label/mnist_y_train.npy'
test_path = './mnist_image_label/mnist_test_jpg_10000/'
test_txt = './mnist_image_label/mnist_test_jpg_10000.txt'
x_test_savepath = './mnist_image_label/mnist_x_test.npy'
y_test_savepath = './mnist_image_label/mnist_y_test.npy'
|
这里指定了文件的地址,其中图片是只有所在文件夹的地址,后面会组合成具体图片的地址。
而savepath则是用于保存已经匹配好的数据集。
generateds()函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| def generateds(path, txt):
f = open(txt, 'r')
contents = f.readlines()
f.close()
x, y_ = [], []
for content in contents:
value = content.split()
img_path = path + value[0]
img = Image.open(img_path)
img = np.array(img.convert('L'))
img = img / 255.
x.append(img)
y_.append(value[1])
print('loading : ' + content)
x = np.array(x)
y_ = np.array(y_)
y_ = y_.astype(np.int64)
return x, y_
|
此函数用于读取图片,将其转换为灰度值的二维矩阵,而后存储在列表之中。
在转换的过程中,会进行数据与标签的匹配。
os判断部分:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| if os.path.exists(x_train_savepath) and os.path.exists(y_train_savepath) and os.path.exists(
x_test_savepath) and os.path.exists(y_test_savepath):
print('-------------Load Datasets-----------------')
x_train_save = np.load(x_train_savepath)
y_train = np.load(y_train_savepath)
x_test_save = np.load(x_test_savepath)
y_test = np.load(y_test_savepath)
x_train = np.reshape(x_train_save, (len(x_train_save), 28, 28))
x_test = np.reshape(x_test_save, (len(x_test_save), 28, 28))
else:
print('-------------Generate Datasets-----------------')
x_train, y_train = generateds(train_path, train_txt)
x_test, y_test = generateds(test_path, test_txt)
print('-------------Save Datasets-----------------')
x_train_save = np.reshape(x_train, (len(x_train), -1))
x_test_save = np.reshape(x_test, (len(x_test), -1))
np.save(x_train_savepath, x_train_save)
np.save(y_train_savepath, y_train)
np.save(x_test_savepath, x_test_save)
np.save(y_test_savepath, y_test)
|
这里主要是进行判断,即是否已经运行过代码,生成了数据。可以加载已经保存的数据,不用再进行读入匹配。
我的收获
在进行深度学习的过程中,很多数据集是没有内置的,我们需要自制数据集。一般来说,自制数据集都是将数据转换为可以进行模型读入的形式,这里Numpy很重要,需要加大学习深度与灵活应用。
上面的例子是一个很好的参考,以后进行实践的时候可以参考这个进行数据集的搭建。
数据增强,扩充数据集
这个部分主要是对数据进行预处理,对数据集进行某些操作以减少其噪音干扰,提高准确率。
不同的数据集需要进行不同的预处理,这里主要是针对MNIST数据集进行演示。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
image_gen_train = ImageDataGenerator(
rescale=1. / 1.,
rotation_range=45,
width_shift_range=.15,
height_shift_range=.15,
horizontal_flip=False,
zoom_range=0.5
)
image_gen_train.fit(x_train)
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(image_gen_train.flow(x_train, y_train, batch_size=32), epochs=5, validation_data=(x_test, y_test),
validation_freq=1)
model.summary()
|
因为是局限于MNIST数据集,这里不再进行介绍。
断点续训,存取模型
我们在进行完模型的训练与优化之后,就要进行模型的保存,这样在进行数据的预测时就可以直接调用保存的模型即可。
在keras中给出了模型读取和保存的函数,我们接下来进行演示。
模型的读取
使用load_weights(路径名)进行模型的读取
代码如下:
1
2
3
4
| checkpoint_save_path = "./checkpoint/mnist.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
|
具体介绍:
- 先定义好模型的存储地址(ckpt文件)
- 再通过
os.path.exists()判断是否有保存的模型(在文件保存时会同步生成索引表,通过index进行判断)
- 使用
model.load.weights()进行模型参数的读取(model为前面定义好的空模型)
模型的保存
使用TensorFlow提供的回调函数进行保存。
代码如下:
1
2
3
4
5
6
| cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
|
具体介绍:
- 在
tf.keras.callbacks.ModelCheckpoint()告知文件存储路径、是否只保存模型参数,是否只保存最优值。
- 在执行训练过程时加入
callbacks选项,记录到history中
完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| import tensorflow as tf
import os
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/mnist.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
|
运行结果:
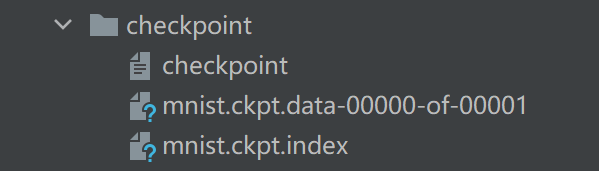
可以在文件夹里看见保存的模型。再次运行代码,会在已有模型的基础上进行训练。
参数提取
本节学习如何将保存模型的参数提取出来,变成可以量化的文本形式。
- 提取可训练参数
model.trainable_variables 返回模型中可训练的参数
- 打印参数
1
2
3
4
5
6
7
8
9
| np.set_printoptions(threshold=np.inf)
print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
|
p.set_printoptions(precision=小数点后按四舍五入保留几位,threshold=数组元素数量少于或等于门槛值,打印全部元素;否则打印门槛值+1 个元素,中间用省略号补充)
这里使用np.set_printoptions(threshold=np.inf)表示打印所有的元素。
运行结果:
在文件夹里看到生成的weight.txt文件,其中可以看到保存的参数。
Acc与loss可视化
其实在进行fit时,已经实时记录了我们所需的参数,我们只需要读取并使用模块画出即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
|
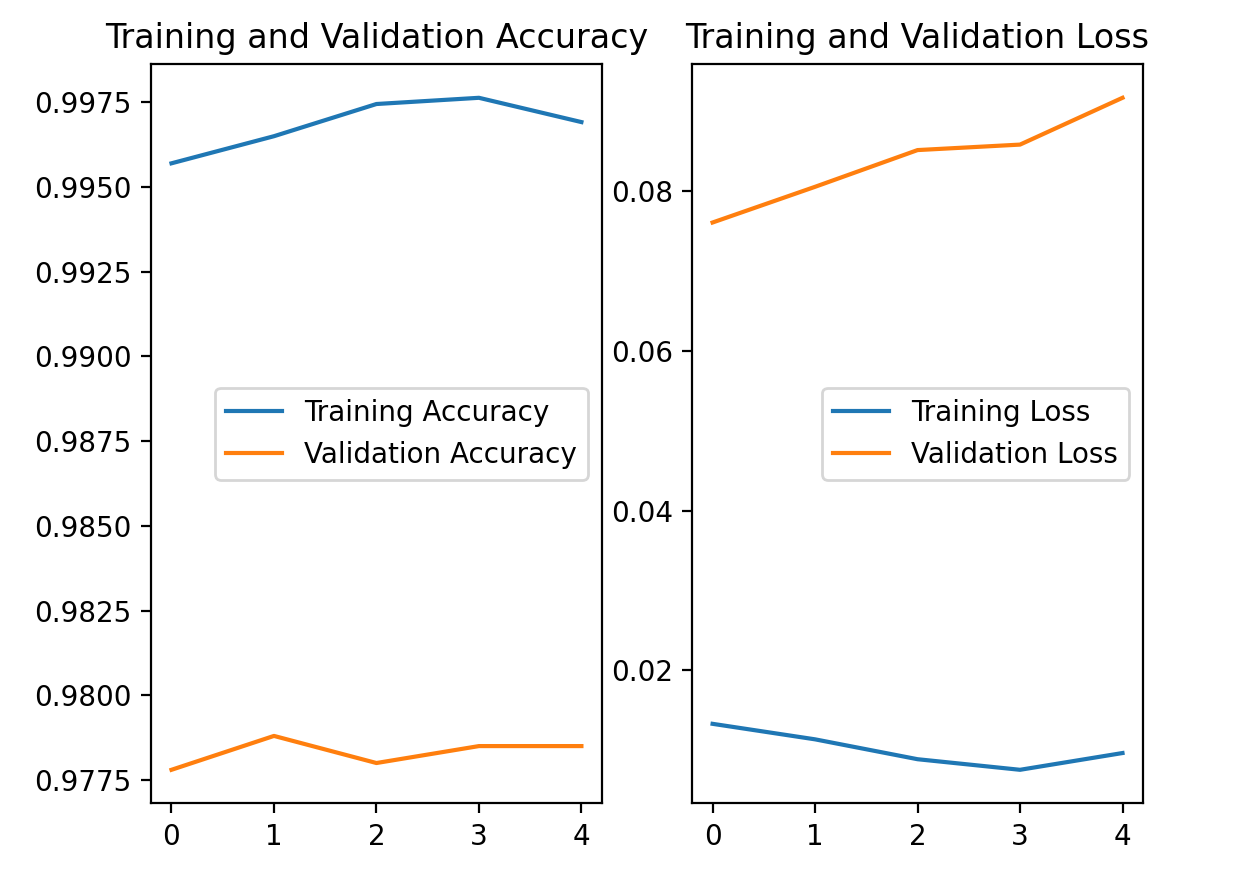
以上代码就是读取保存的数据,再使用plt模型进行图像绘制的过程。
其中:
- 训练集loss: loss
- 测试集loss: val_loss
- 训练集准确率: sparse_categorical_accuracy
- 测试集准确率: val_sparse_categorical_accuracy
而关于plt的使用在python的学习中会进行整理。
这里我们来看一下运行结果:
实际应用:绘图识字
我们前面的一系列操作就是为了提供已有的数据集将我们的神经网络训练完成,得到一套可以成功识别的参数。下面我们要进行实际的测试,即使用我们已经训练好的模型进行手写数字的识别。
大体流程如下:
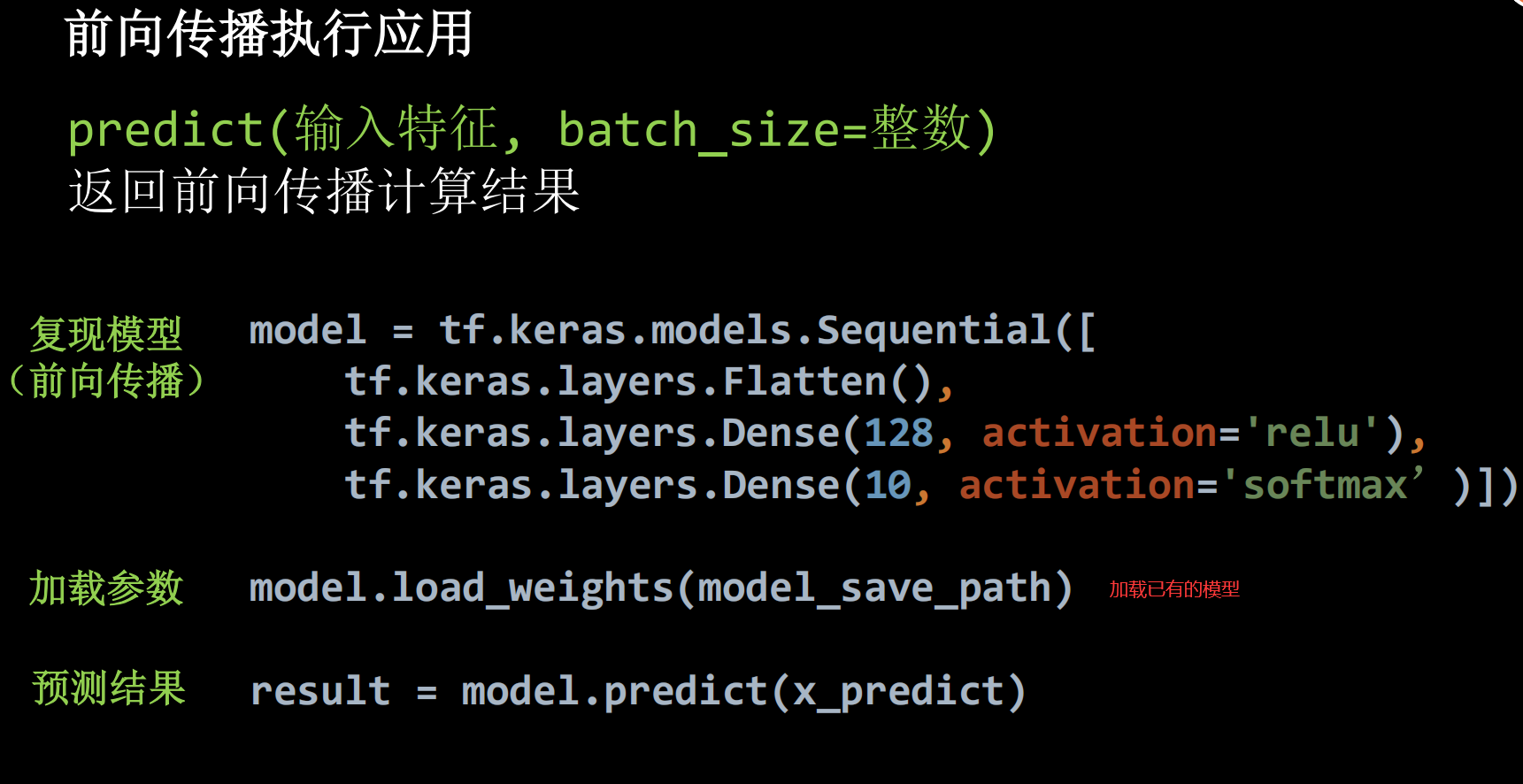
前两个部分已经介绍过,这里我们主要介绍一些第三个部分,即图片的读取与预处理。
先给出代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| from PIL import Image
import numpy as np
import tensorflow as tf
model_save_path = './checkpoint/mnist.ckpt'
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')])
model.load_weights(model_save_path)
preNum = int(input("input the number of test pictures:"))
for i in range(preNum):
image_path = input("the path of test picture:")
img = Image.open(image_path)
img = img.resize((28, 28), Image.ANTIALIAS)
img_arr = np.array(img.convert('L'))
for i in range(28):
for j in range(28):
if img_arr[i][j] < 200:
img_arr[i][j] = 255
else:
img_arr[i][j] = 0
img_arr = img_arr / 255.0
x_predict = img_arr[tf.newaxis, ...]
result = model.predict(x_predict)
pred = tf.argmax(result, axis=1)
print('\n')
tf.print(pred)
|
有几个需要注意的地方:
- 通过Image模块进行图片的读取。在读取的时候要进行图片长宽的变化:
img = img.resize((28, 28), Image.ANTIALIAS)
- 我们需要的是黑底白字的图片,所以要在读取前进行灰度值的改变。
这里对这个二维数组进行了遍历,把小于200的灰度值变成255,其余变成了0,使得图片的对比度提高。
- 在输入神经网络前还要进行归一化,和矩阵维数的变化,变成1x28x28的三维矩阵。
- 使用
tf.argmax(result, axis=1)获取最大值下标为结果。
识别结果:

写在最后:
至此,有关TensorFlow的基本知识已经完成,对一个全连接神经网络的建立与训练也已经有了一个规范化的模式。可以说关于深度学习的树干已经树立好了,接下来就是为其添枝加叶,开花结果。
行百里者半九十,况且我还只是刚刚开始,更加不能松懈。接下来要时时复习所学知识,巩固基础。并不断学习更加深入的知识,有选择的与实践项目结合。同时对python的学习也不能落下,对用到的第三方库要进行整理。





