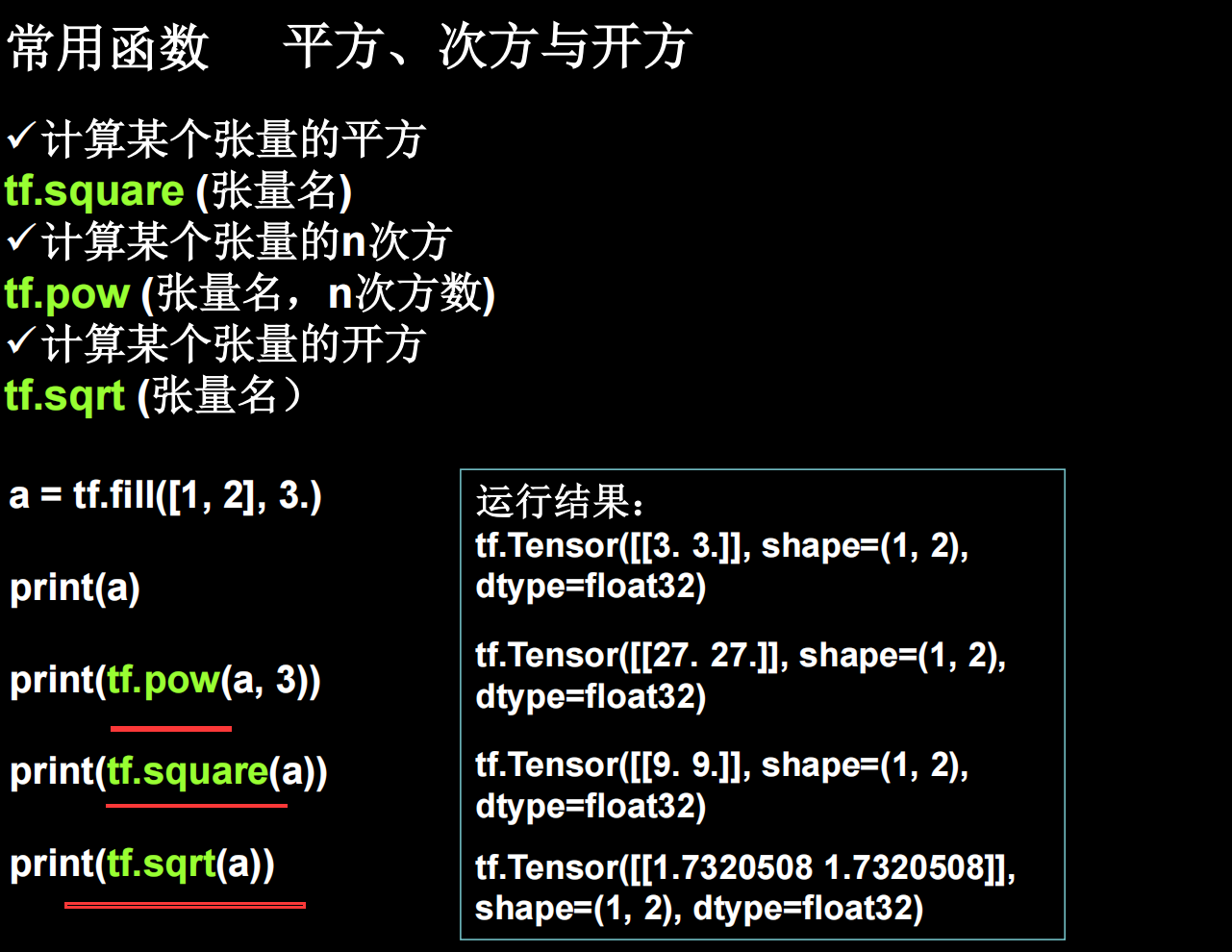
写在最前面:本篇文章时学习后的收获总结,学习流程大体如下:看视频—> 根据ppt整理 —> 阅读笔记后进行补充。(笔记自看,多思考;实践必做,跑dome)
人工智能三学派
什么是人工智能?让机器具备人的思维和意识 。
笔记补充
连接主义的神经网络
基于连接主义的神经网络模仿神经元,使计算机具有感性思维。图 1.2展示了从出生到成年,人脑中神经网络的变化。视觉、听觉 涌入大脑,使我们的神经网络连接,也就是这些神经元连接线上的权重 发生了变化,有些线上的权重增强了,有些线上的权重减弱了。如图 1.3 所示
基于连接主义的神经网络设计过程
神经网络设计过程?
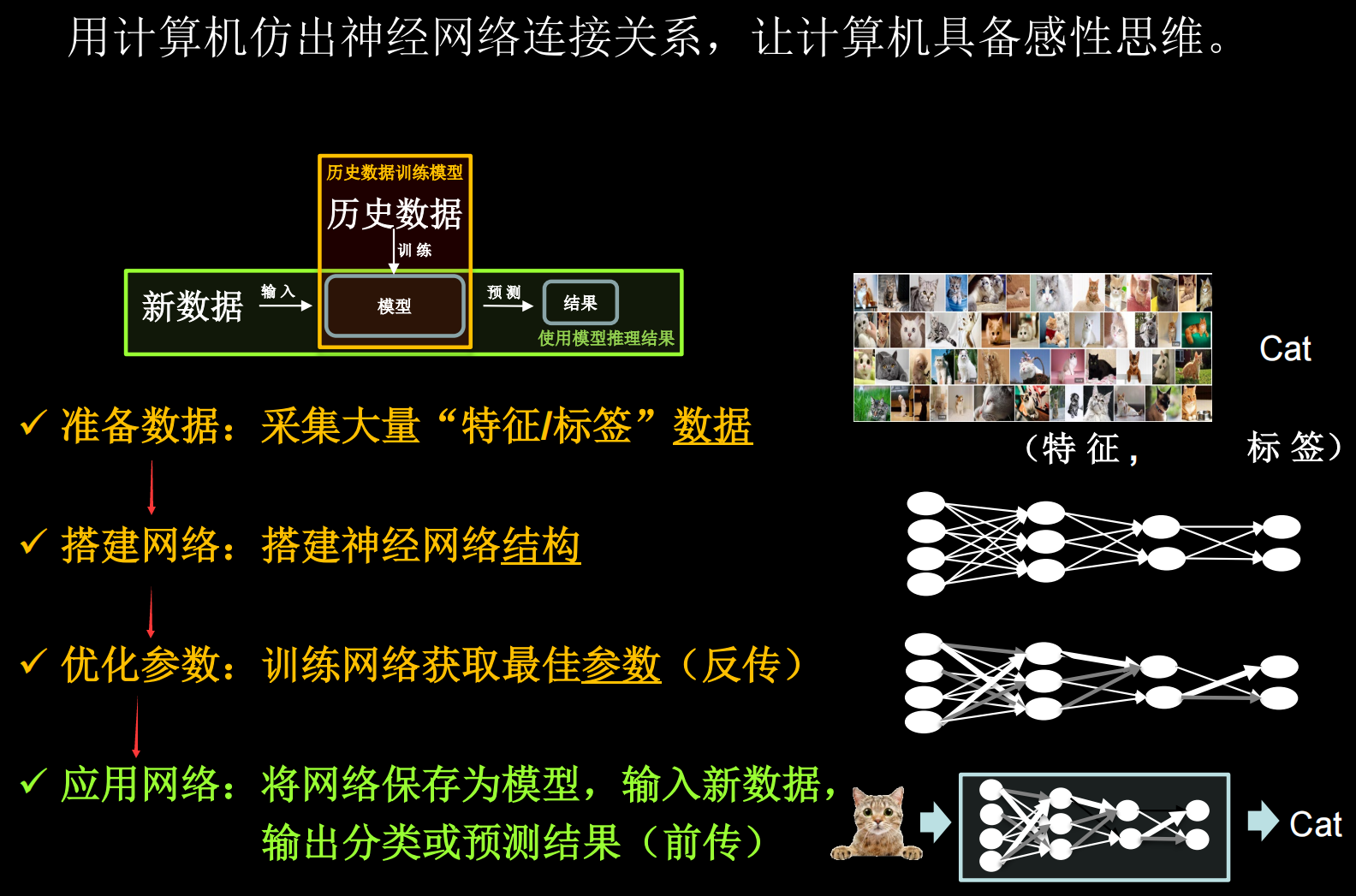
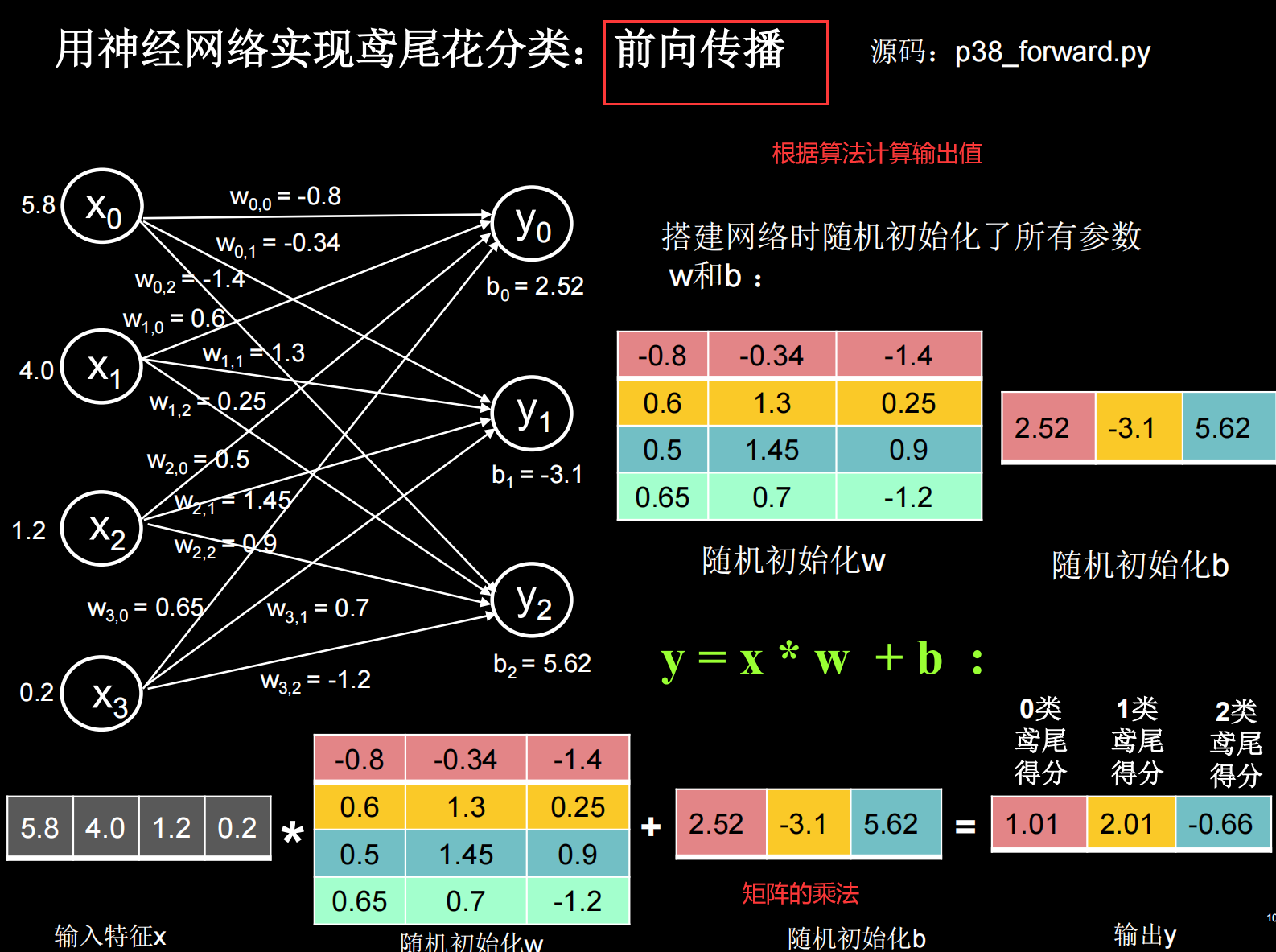
我们要用计算机模仿刚刚说到的神经网络连接关系,让计算机具备感性思维。准备数据 ,数据量越大越好 ,要构成特征和标签对 。如要识别猫,就要有大量猫的图片和这个图片是猫的标签,构成特征标签对。网络结构 ,并通过反向传播 ,优化连线的权重,直到模型的识别准确率达到要求,得到最优的连线权重,把这个模型保存 起来。前向传播 ,输出概率值,概率值最大的一个,就是分类或预测的结果。下图展示了搭建与使用神经网络模型的流程。
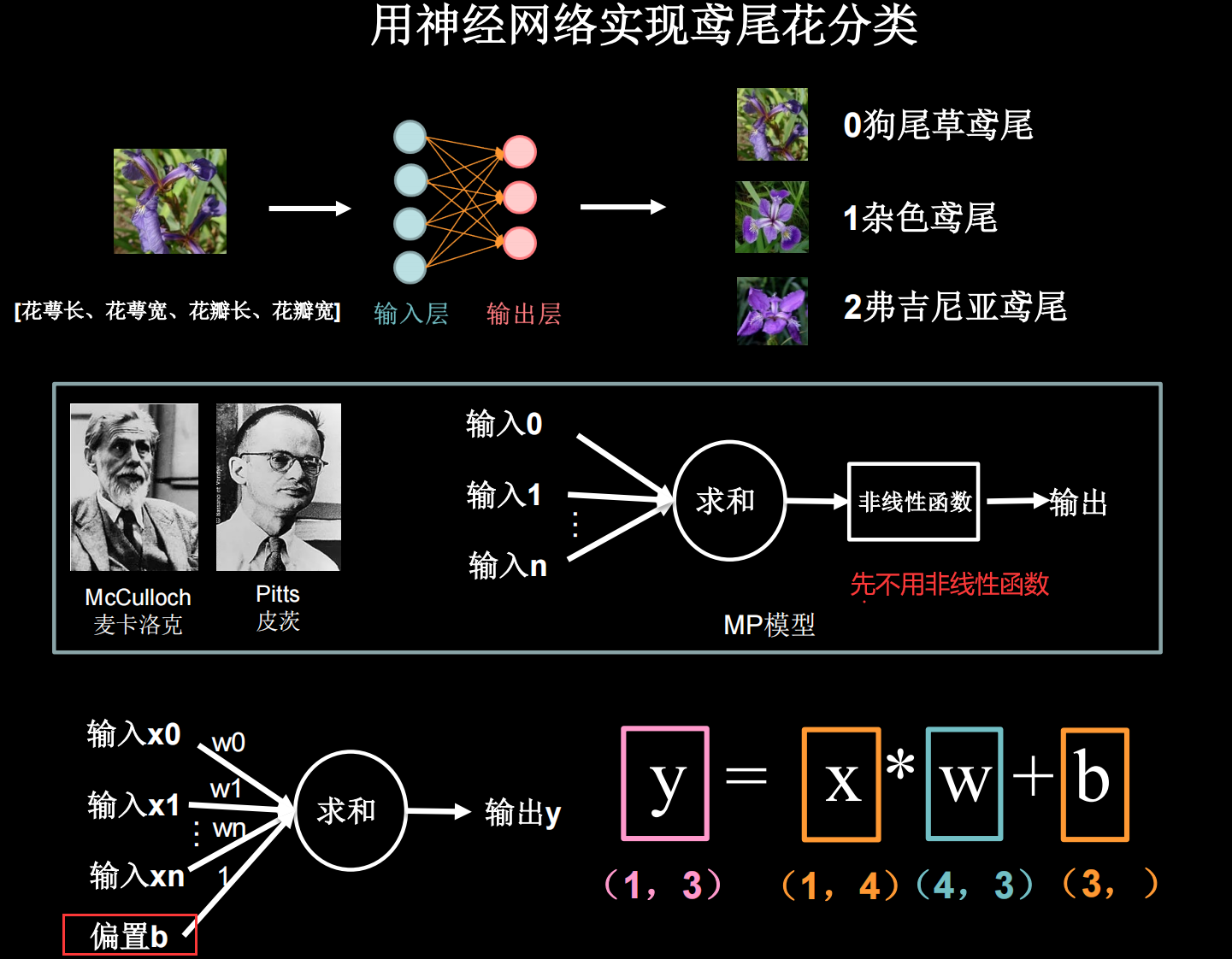
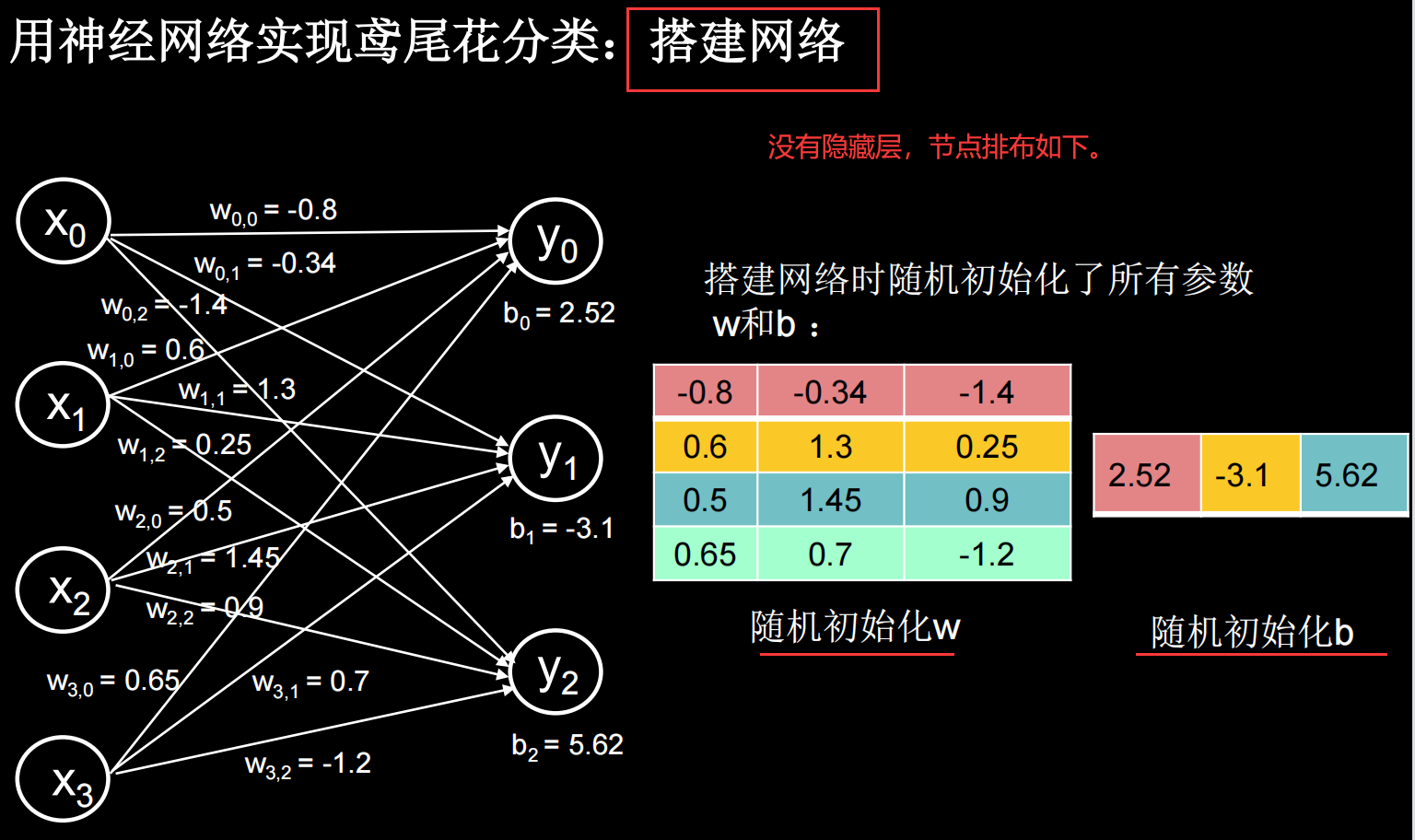
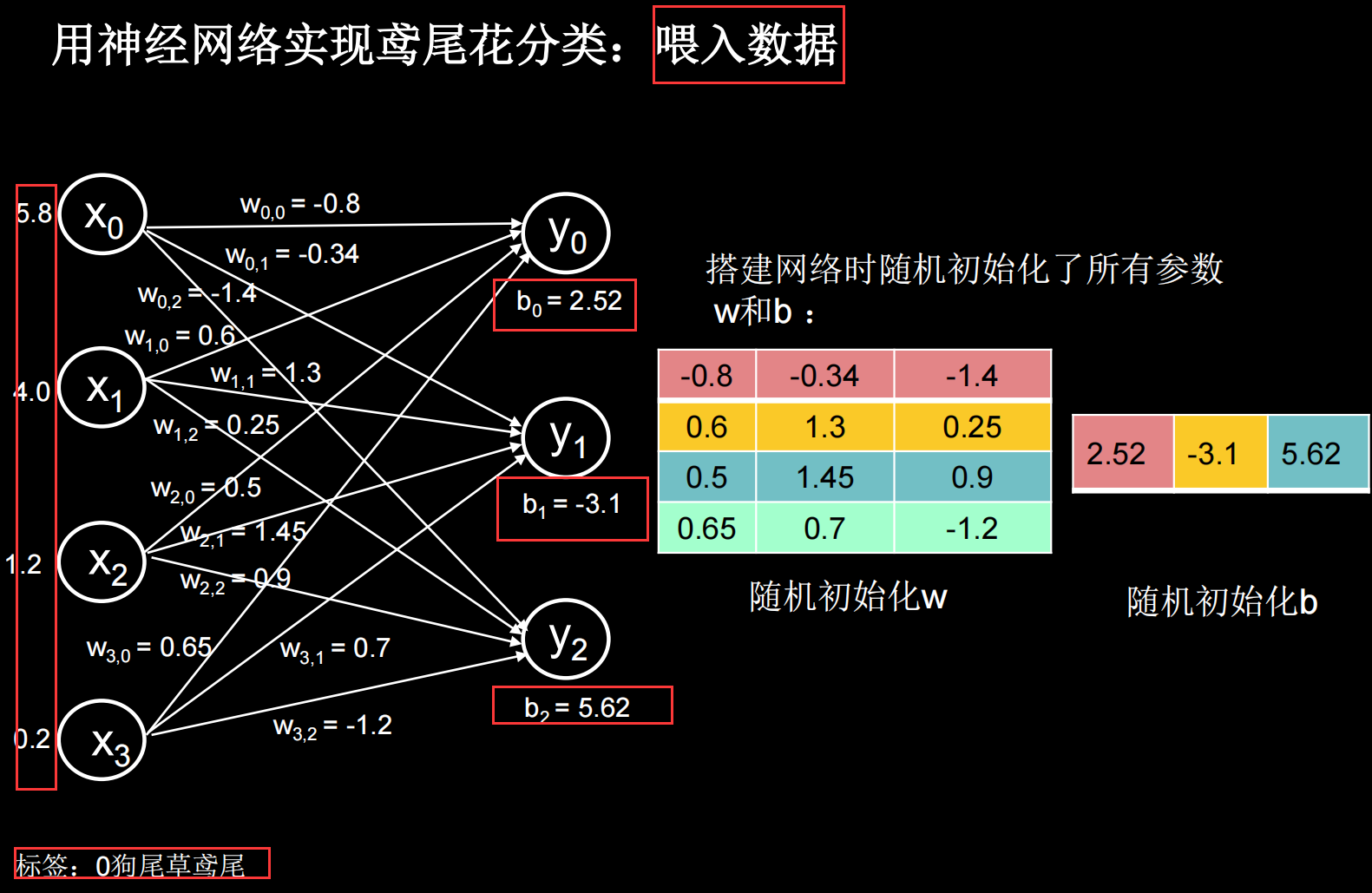
举一个例子:给鸢尾花分类(Iris)
示例代码如下:
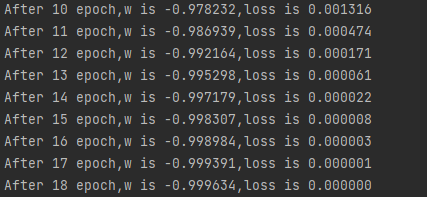
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import tensorflow as tfw = tf.Variable(tf.constant(5 , dtype=tf.float32)) lr = 0.2 epoch = 40 for epoch in range (epoch): with tf.GradientTape() as tape: loss = tf.square(w + 1 ) grads = tape.gradient(loss, w) w.assign_sub(lr * grads) print ("After %s epoch,w is %f,loss is %f" % (epoch, w.numpy(), loss))
代码结果:
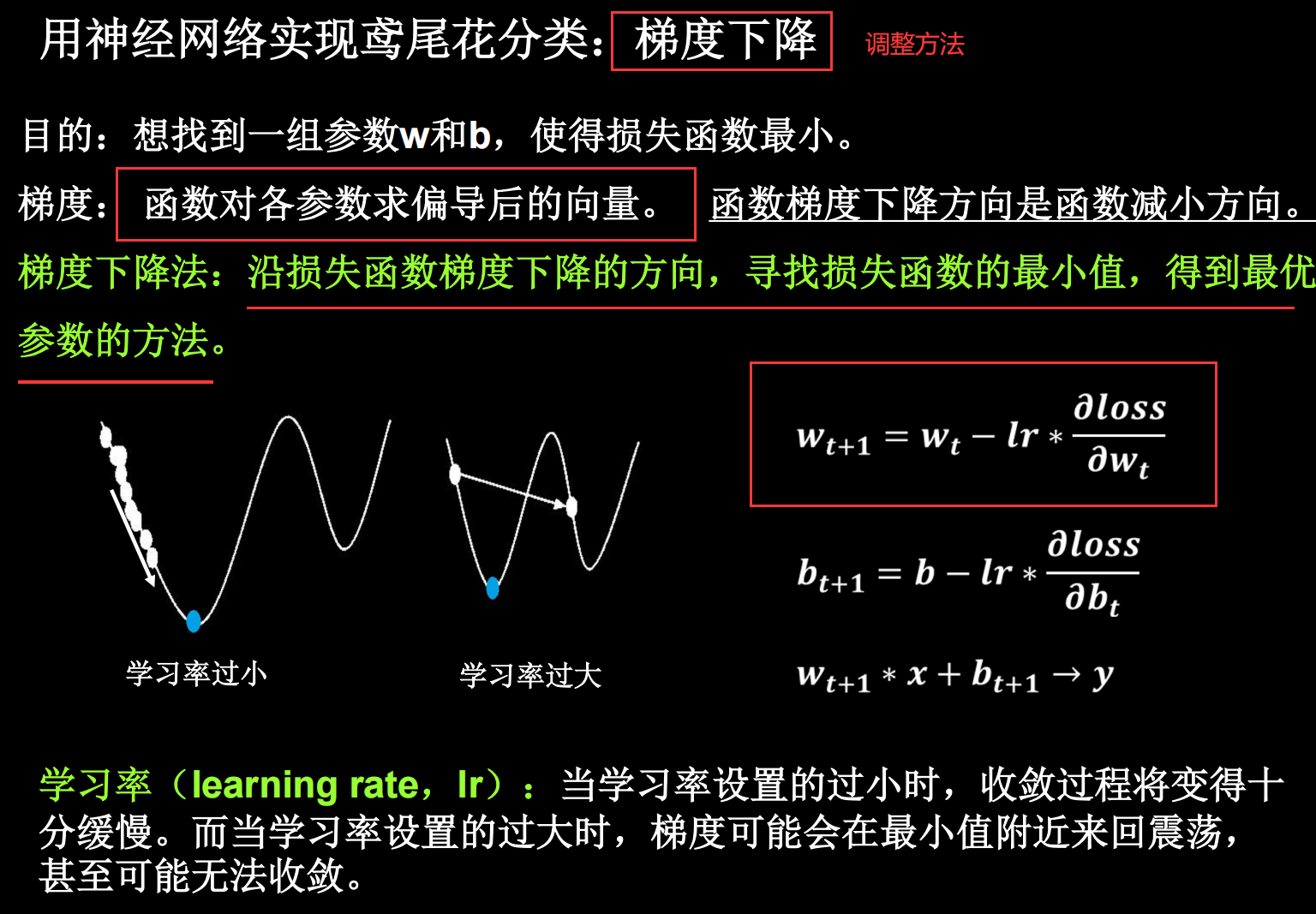
可见,经过18次迭代之后就可以得到最小值。但是如果学习率过小 ,经过40次迭代也无法得到最小值;如果学习率过大 ,会在最小值之间跳动,也无法得到最小值。所以我们需要通过更加科学的方法动态调整学习率 ,以达到最佳识别效果。
张量生成
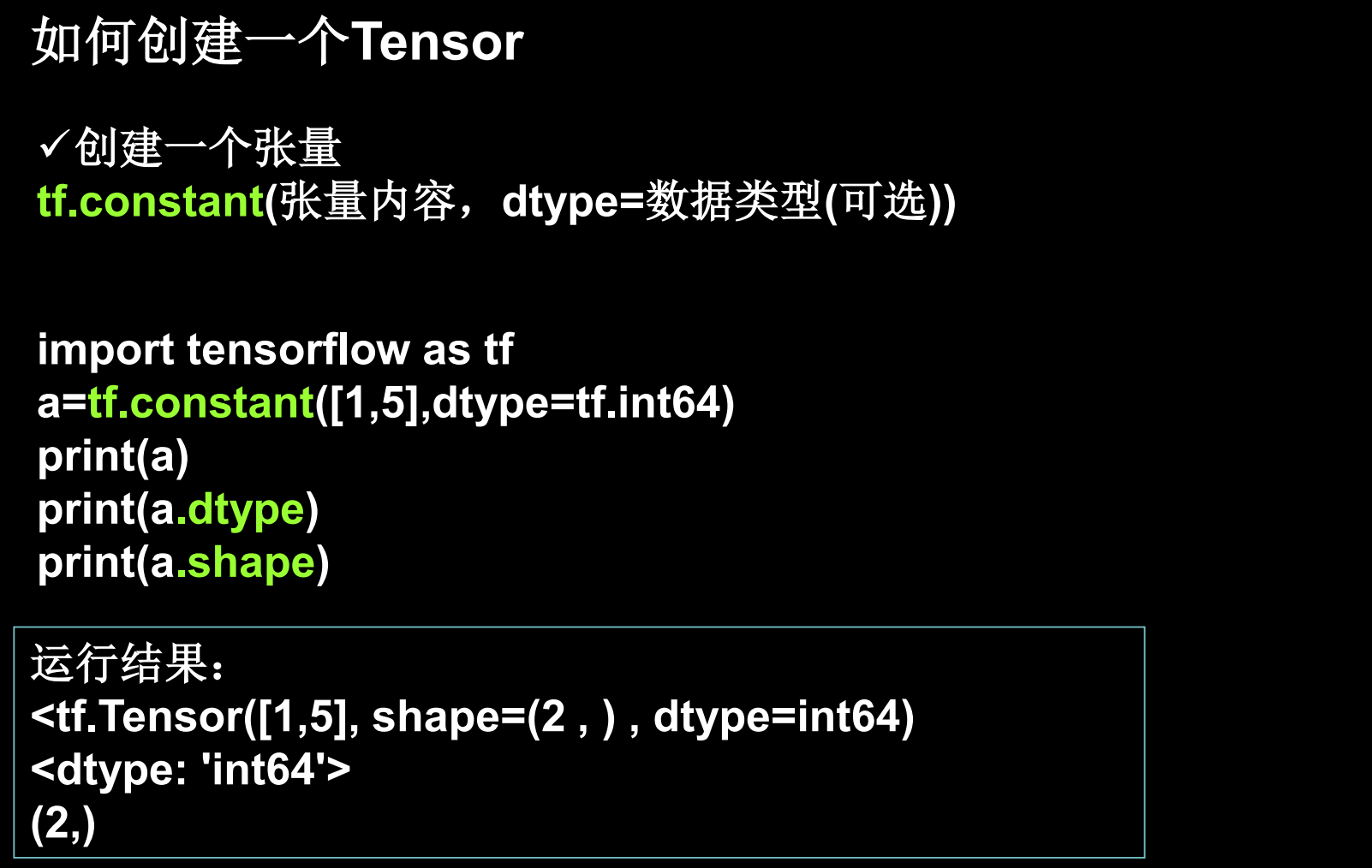
张量是TensorFlow的基础,从其名称就可以看出来。属于tensorflow的数据类型。
注:这里使用tf.constant创建的张量属于常量。要使用[xx]格式给出具体值,这里有几层中括号其维度就是多少 ,具体可以看上张量图。
注:将numpy生成的一维数组转换为张量(带有维度、数据类型)
注:使用这种方法可以创建数据相同的张量。不过其参数要给出维度,逗号分隔开几个数就有几维 。
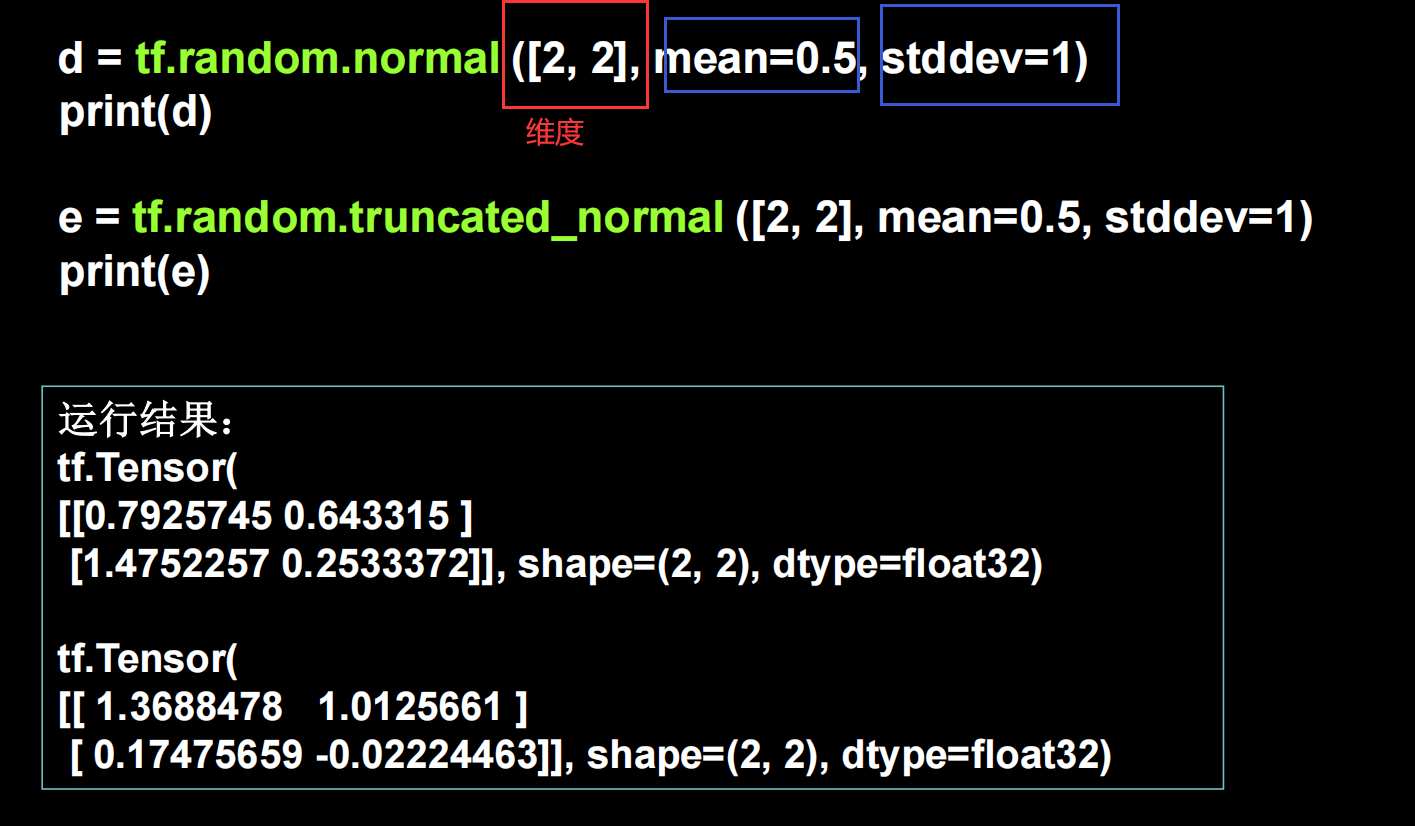
注:函数较长,但是都是属于random 。并且这个是属于随机生成 ,不需要指定数据。
注:与上正态分布格式类似,不过分布不同。
常用tf函数
tf.cast与tf.reduce_max+tf.reduce_min
注:使用cast转换后仍为张量 ,只是改名数据类型。tf.reduce有很多类别,上面已经有了max和min,取值后仍为张量。
1 2 3 4 5 6 7 8 import tensorflow as tfx1 = tf.constant([1. , 2. , 3. ], dtype=tf.float64) print ("x1:" , x1)x2 = tf.cast(x1, tf.int32) print ("x2" , x2)print ("minimum of x2:" , tf.reduce_min(x2))print ("maxmum of x2:" , tf.reduce_max(x2))
注:这里的axis可以指定计算的区域,0为纵向,1为横向 。
代码示例:
1 2 3 4 5 6 7 import tensorflow as tfx = tf.constant([[1 , 2 , 3 ], [2 , 2 , 3 ]]) print ("x:" , x)print ("mean of x:" , tf.reduce_mean(x)) print ("sum of x:" , tf.reduce_sum(x, axis=1 ))
tf.Variable可以生成变量,常用于训练量。
注:矩阵乘法的计算过程要知道。
代码示例:
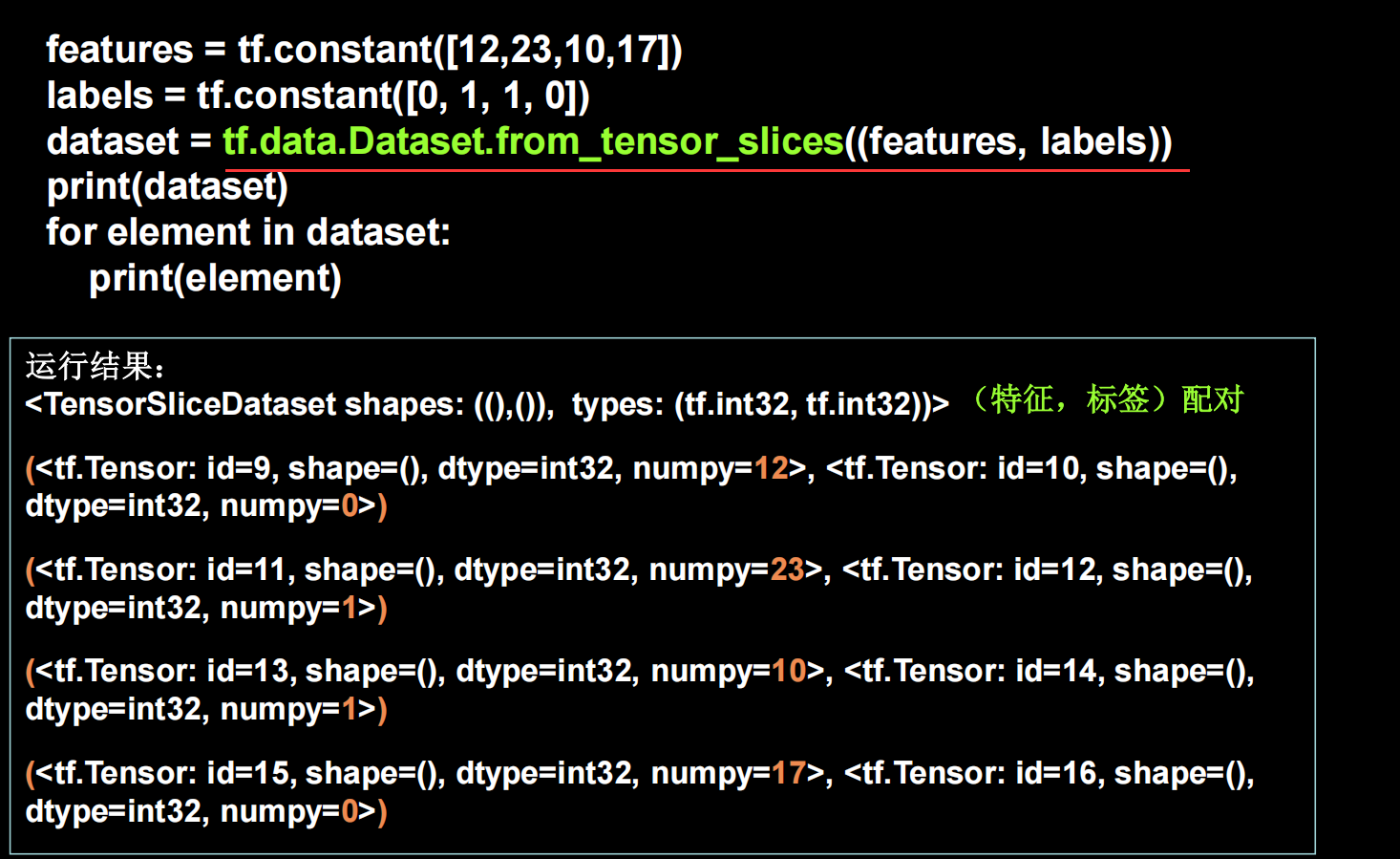
1 2 3 4 5 6 7 8 import tensorflow as tffeatures = tf.constant([12 , 23 , 10 , 17 ]) labels = tf.constant([0 , 1 , 1 , 0 ]) dataset = tf.data.Dataset.from_tensor_slices((features, labels)) for element in dataset: print (element)
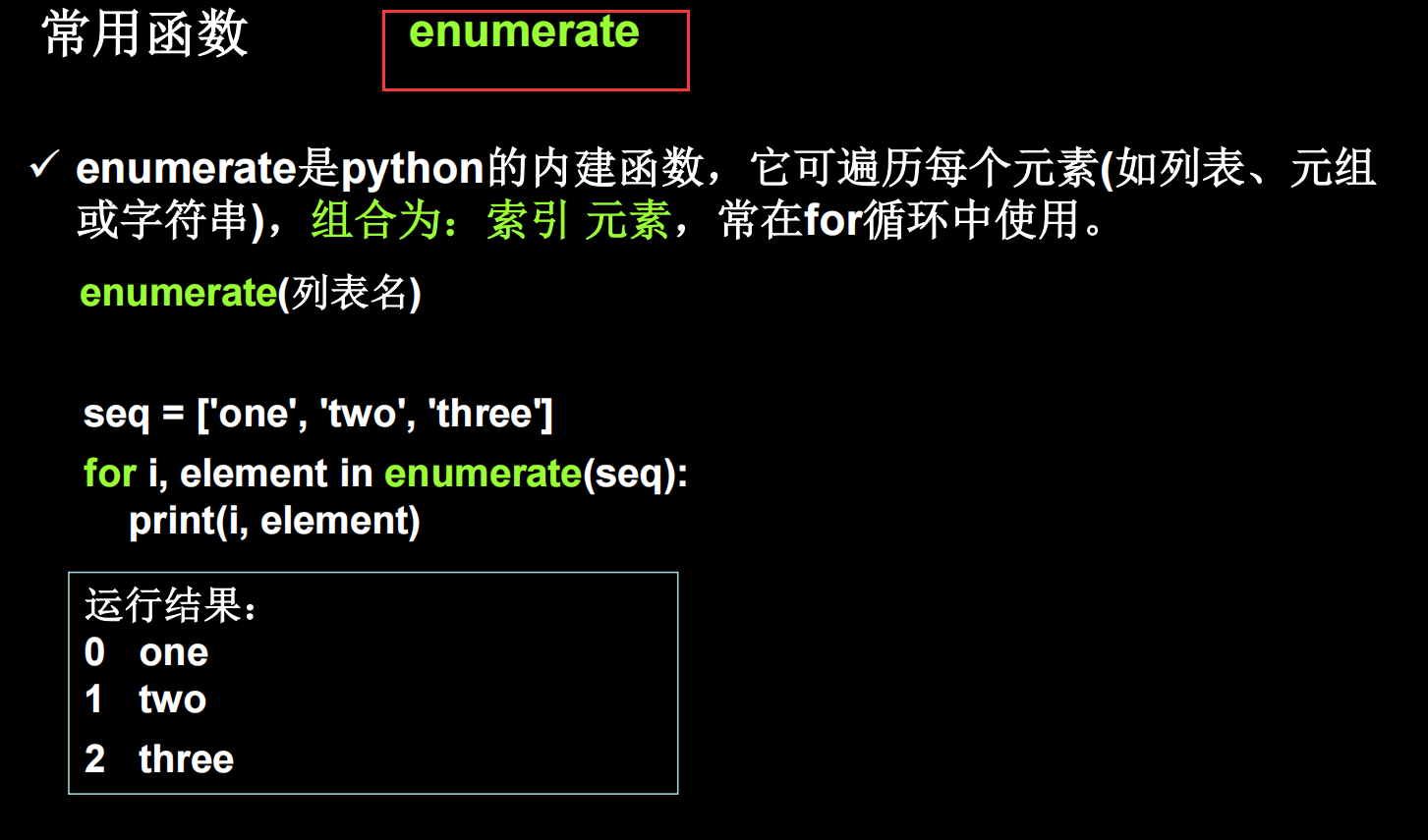
注:可利用 enumerate(列表名)函数枚举出每一个元素,并在元素前配上对应的索引号,常在 for 循环中使用。
注:可用tf.one_hot(待转换数据,depth=几分类)函数实现用独热码 表示标签,在分类问题中很常见。标记类别为为 1 和 0,其中 1 表示是,0 表示非。如在鸢尾花分类任务中,如果标签是 1,表示分类结果是 1 杂色鸢尾,其用把它用独热码表示就是 0,1,0,这样可以表示出每个分类的概率:也就是百分之 0 的可能是 0狗尾草鸢尾,百分百的可能是 1 杂色鸢尾,百分之 0 的可能是弗吉尼亚鸢尾。
实例:神经网络实现鸢尾花分类(简化)
具体代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 import tensorflow as tffrom sklearn import datasetsfrom matplotlib import pyplot as pltimport numpy as npx_data = datasets.load_iris().data y_data = datasets.load_iris().target print (x_data, y_data)np.random.seed(116 ) np.random.shuffle(x_data) np.random.seed(116 ) np.random.shuffle(y_data) tf.random.set_seed(116 ) x_train = x_data[:-30 ] y_train = y_data[:-30 ] x_test = x_data[-30 :] y_test = y_data[-30 :] x_train = tf.cast(x_train, tf.float32) x_test = tf.cast(x_test, tf.float32) train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32 ) test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32 ) w1 = tf.Variable(tf.random.truncated_normal([4 , 3 ], stddev=0.1 , seed=1 )) b1 = tf.Variable(tf.random.truncated_normal([3 ], stddev=0.1 , seed=1 )) lr = 0.1 train_loss_results = [] test_acc = [] epoch = 500 loss_all = 0 for epoch in range (epoch): for step, (x_train, y_train) in enumerate (train_db): with tf.GradientTape() as tape: y = tf.matmul(x_train, w1) + b1 y = tf.nn.softmax(y) y_ = tf.one_hot(y_train, depth=3 ) loss = tf.reduce_mean(tf.square(y_ - y)) loss_all += loss.numpy() grads = tape.gradient(loss, [w1, b1]) w1.assign_sub(lr * grads[0 ]) b1.assign_sub(lr * grads[1 ]) print ("Epoch {}, loss: {}" .format (epoch, loss_all/4 )) train_loss_results.append(loss_all / 4 ) loss_all = 0 total_correct, total_number = 0 , 0 for x_test, y_test in test_db: y = tf.matmul(x_test, w1) + b1 y = tf.nn.softmax(y) pred = tf.argmax(y, axis=1 ) pred = tf.cast(pred, dtype=y_test.dtype) correct = tf.cast(tf.equal(pred, y_test), dtype=tf.int32) correct = tf.reduce_sum(correct) total_correct += int (correct) total_number += x_test.shape[0 ] acc = total_correct / total_number test_acc.append(acc) print ("Test_acc:" , acc) print ("--------------------------" ) plt.title('Loss Function Curve' ) plt.xlabel('Epoch' ) plt.ylabel('Loss' ) plt.plot(train_loss_results, label="$Loss$" ) plt.legend() plt.show() plt.title('Acc Curve' ) plt.xlabel('Epoch' ) plt.ylabel('Acc' ) plt.plot(test_acc, label="$Accuracy$" ) plt.legend() plt.show()
对以上代码的补充分析:
1、数据集读入、数据集乱序、将数据集分割成永不相见的训练集和测试集、将数据配成[输入特征,标签]对。
补充1:数据集 也需要被打乱顺序。
补充2:同样的随机种子 ,所以打乱顺序后输入特征和标签仍然是一一对应 的。
补充3:配对打包 ,将每 32 组输入特征标签对打包为一个 batch,在喂入神经网络时会以 batch 为单位 喂入。
训练过程?
补充1:整个数据集 进行循环,故用 epoch 表示;第二层 for 循环是针对 batch 的,用 step 表示。
补充2:batch 级别循环 4 次 ,所以 loss 除以 4,求得每次 step 迭代的平均 loss。
扩展方法
梯度爆炸?
参数更新量为学习率与损失函数偏导数相乘,二者乘积过大,则会导致梯度爆炸。
故解决方法可为:逐步减小 学习率,0.1、0.01 等;归一化与标准化 ,其主要方法有线性归一化 、非线性归一化 、Z-Score 标准化 。
以线性归一化为例,其代码实现如下:
1 2 3 4 5 6 7 def normalize (data ): x_data = data.T for i in range (4 ): x_data[i] = (x_data[i] - tf.reduce_min(x_data[i])) / (tf.reduce_max(x_data[i]) - tf.reduce_min(x_data[i])) return x_data.T
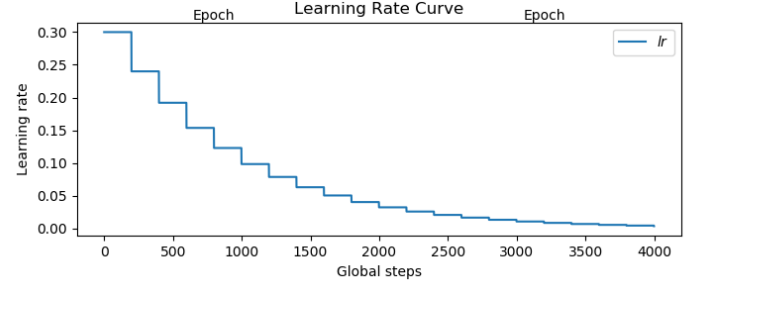
指数衰减学习率:指数衰减学习率可在训练初期赋予网络较大学习率,并在训练过程中逐步减小,可有效增加网络收敛速度。tf.compat.v1.train.exponential_decay(learning_rate_base,global_step,decay_step,deca y_rate,staircase =True(False),name),当 staircase 为 True 时,学习率呈现阶梯状递减。